 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposite Goodness-of-fit Tests with Kernels
Nov 19, 2021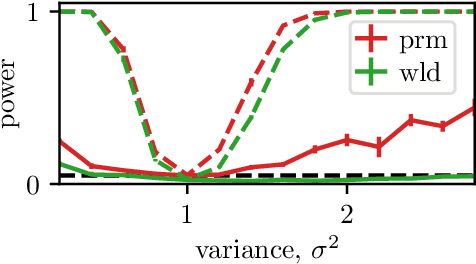

Model misspecification can create significant challenges for the implementation of probabilistic models, and this has led to development of a range of inference methods which directly account for this issue. However, whether these more involved methods are required will depend on whether the model is really misspecified, and there is a lack of generally applicable methods to answer this question. One set of tools which can help are goodness-of-fit tests, where we test whether a dataset could have been generated by a fixed distribution. Kernel-based tests have been developed to for this problem, and these are popular due to their flexibility, strong theoretical guarantees and ease of implementation in a wide range of scenarios. In this paper, we extend this line of work to the more challenging composite goodness-of-fit problem, where we are instead interested in whether the data comes from any distribution in some parametric family. This is equivalent to testing whether a parametric model is well-specified for the data.
Kernelized Stein Discrepancy Tests of Goodness-of-fit for Time-to-Event Data
Aug 26, 2020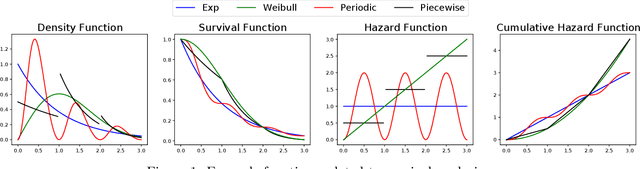

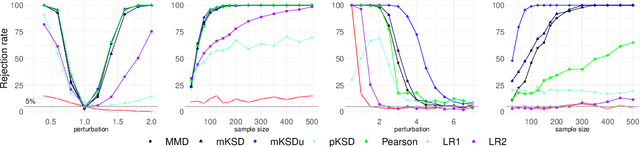

Survival Analysis and Reliability Theory are concerned with the analysis of time-to-event data, in which observations correspond to waiting times until an event of interest such as death from a particular disease or failure of a component in a mechanical system. This type of data is unique due to the presence of censoring, a type of missing data that occurs when we do not observe the actual time of the event of interest but, instead, we have access to an approximation for it given by random interval in which the observation is known to belong. Most traditional methods are not designed to deal with censoring, and thus we need to adapt them to censored time-to-event data. In this paper, we focus on non-parametric goodness-of-fit testing procedures based on combining the Stein's method and kernelized discrepancies. While for uncensored data, there is a natural way of implementing a kernelized Stein discrepancy test, for censored data there are several options, each of them with different advantages and disadvantages. In this paper, we propose a collection of kernelized Stein discrepancy tests for time-to-event data, and we study each of them theoretically and empirically; our experimental results show that our proposed methods perform better than existing tests, including previous tests based on a kernelized maximum mean discrepancy.
A kernel log-rank test of independence for right-censored data
Dec 08, 2019



With the incorporation of new data gathering methods in clinical research, it becomes fundamental for survival analysis techniques to deal with high-dimensional or/and non-standard covariates. In this paper we introduce a general non-parametric independence test between right-censored survival times and covariates taking values on a general (not necessarily Euclidean) space $\mathcal{X}$. We show that our test statistic has a dual interpretation, first in terms of the supremum of a potentially infinite collection of weight-indexed log-rank tests, with weight functions belonging to a reproducing kernel Hilbert space (RKHS) of functions; and second, as the norm of the difference of embeddings of certain finite measures into the RKHS, similar to the Hilbert-Schmidt Independence Criterion (HSIC) test-statistic. We study the asymptotic properties of the test, finding sufficient conditions to ensure that our test is omnibus. The test statistic can be computed straightforwardly, and the rejection threshold is obtained via an asymptotically consistent Wild-Bootstrap procedure. We perform extensive simulations demonstrating that our testing procedure generally performs better than competing approaches in detecting complex nonlinear dependence.
A Reproducing Kernel Hilbert Space log-rank test for the two-sample problem
Apr 10, 2019Weighted log-rank tests are arguably the most widely used tests by practitioners for the two-sample problem in the context of right-censored data. Many approaches have been considered to make weighted log-rank tests more robust against a broader family of alternatives, among them: considering linear combinations of weighted log-rank tests or taking the maximum between a finite collection of them. In this paper, we propose as test-statistic the supremum of a collection of (potentially infinite) weight-indexed log-rank tests where the index space is the unit ball of a reproducing kernel Hilbert space (RKHS). By using the good properties of the RKHS's we provide an exact and simple evaluation of the test-statistic and establish relationships between previous tests in the literature. Additionally, we show that for a special family of RKHS's, the proposed test is omnibus. We finalise by performing an empirical evaluation of the proposed methodology and show an application to a real data scenario.