 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
The Reality of AI and Biorisk
Dec 02, 2024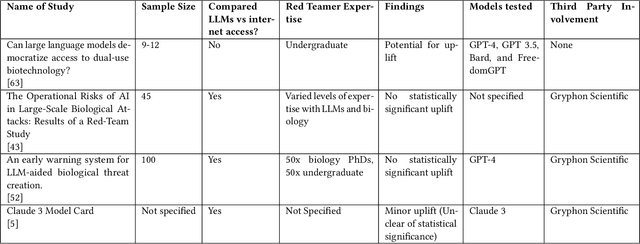
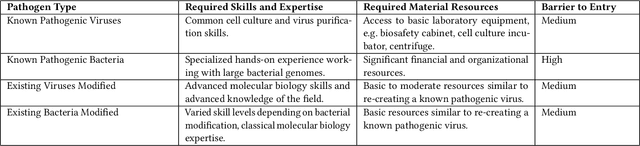
To accurately and confidently answer the question 'could an AI model or system increase biorisk', it is necessary to have both a sound theoretical threat model for how AI models or systems could increase biorisk and a robust method for testing that threat model. This paper provides an analysis of existing available research surrounding two AI and biorisk threat models: 1) access to information and planning via large language models (LLMs), and 2) the use of AI-enabled biological tools (BTs) in synthesizing novel biological artifacts. We find that existing studies around AI-related biorisk are nascent, often speculative in nature, or limited in terms of their methodological maturity and transparency. The available literature suggests that current LLMs and BTs do not pose an immediate risk, and more work is needed to develop rigorous approaches to understanding how future models could increase biorisks. We end with recommendations about how empirical work can be expanded to more precisely target biorisk and ensure rigor and validity of findings.
Aya 23: Open Weight Releases to Further Multilingual Progress
May 23, 2024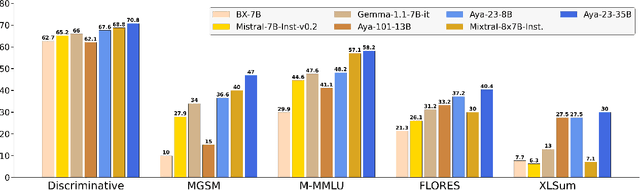

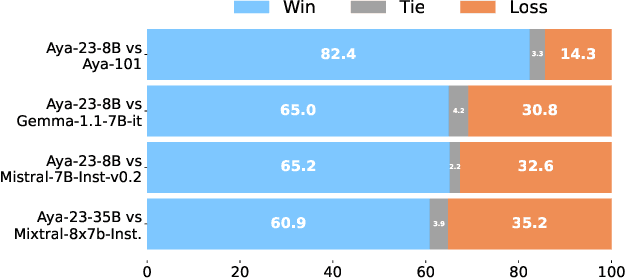

This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model (\"Ust\"un et al., 2024), focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024). The result is a powerful multilingual large language model serving 23 languages, expanding state-of-art language modeling capabilities to approximately half of the world's population. The Aya model covered 101 languages whereas Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training. Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment for expanding access to multilingual progress.
Interlocking Backpropagation: Improving depthwise model-parallelism
Oct 08, 2020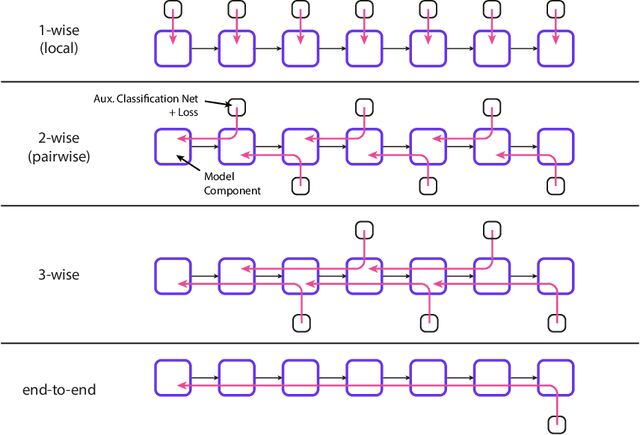



The number of parameters in state of the art neural networks has drastically increased in recent years. This surge of interest in large scale neural networks has motivated the development of new distributed training strategies enabling such models. One such strategy is model-parallel distributed training. Unfortunately, model-parallelism suffers from poor resource utilisation, which leads to wasted resources. In this work, we improve upon recent developments in an idealised model-parallel optimisation setting: local learning. Motivated by poor resource utilisation, we introduce a class of intermediary strategies between local and global learning referred to as interlocking backpropagation. These strategies preserve many of the compute-efficiency advantages of local optimisation, while recovering much of the task performance achieved by global optimisation. We assess our strategies on both image classification ResNets and Transformer language models, finding that our strategy consistently out-performs local learning in terms of task performance, and out-performs global learning in training efficiency.