 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Anticipation for Collaborative Environments: The Impact of Contextual Information and Uncertainty-Based Prediction
Oct 01, 2019



For effectively interacting with humans in collaborative environments, machines need to be able anticipate future events, in order to execute actions in a timely manner. However, the observation of the human limbs movements may not be sufficient to anticipate their actions in an unambiguous manner. In this work we consider two additional sources of information (i.e. context) over time, gaze movements and object information, and study how these additional contextual cues improve the action anticipation performance. We address action anticipation as a classification task, where the model takes the available information as the input, and predicts the most likely action. We propose to use the uncertainty about each prediction as an online decision-making criterion for action anticipation. Uncertainty is modeled as a stochastic process applied to a time-based neural network architecture, which improves the conventional class-likelihood (i.e. deterministic) criterion. The main contributions of this paper are three-fold: (i) we propose a deep architecture that outperforms previous results in the action anticipation task; (ii) we show that contextual information is important do disambiguate the interpretation of similar actions; (iii) we propose the minimization of uncertainty as a more effective criterion for action anticipation, when compared with the maximization of class probability. Our results on the Acticipate dataset showed the importance of contextual information and the uncertainty criterion for action anticipation. We achieve an average accuracy of 98.75% in the anticipation task using only an average of 25% of observations. In addition, considering that a good anticipation model should also perform well in the action recognition task, we achieve an average accuracy of 100% in action recognition on the Acticipate dataset, when the entire observation set is used.
Dynamic Gesture Recognition by Using CNNs and Star RGB: a Temporal Information Condensation
Apr 10, 2019

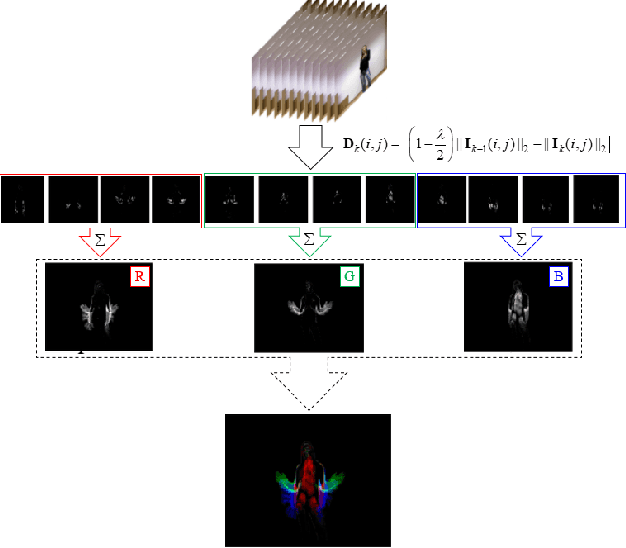
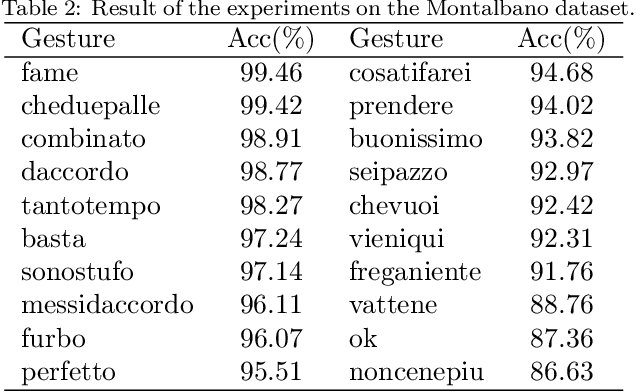
With the advance of technologies, machines are increasingly present in people's daily lives. Thus, there has been more and more effort for developing interfaces, such as dynamic gestures, that provide an intuitive way of interaction. Currently, the most common trend is to use multimodal data, as depth and skeleton information, to try to recognize dynamic gestures. However, the use of only color information would be more interesting, once RGB cameras are usually found in almost every public place, and could be used for gesture recognition without the need to install other equipment. The main problem with this approach is the difficulty of representing spatio-temporal information using just color. With this in mind, we propose a technique that we called Star RGB, capable of describing a videoclip containing a dynamic gesture as an RGB image. This image is then passed to a classifier formed by two Resnet CNN's, a soft-attention ensemble, and a multilayer perceptron, which returns the predicted class label that indicates to which type of gesture the input video belongs. Experiments were carried out using the Montalbano and GRIT datasets. On the Montalbano dataset, the proposed approach achieved an accuracy of 94.58%, this result reaches the state-of-the-art using this dataset, considering only color information. On the GRIT dataset, our proposal achieves more than 98% of accuracy, recall, precision, and F1-score, outperforming the reference approach in more than 6%.