 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Transformers Know about Government?
Apr 22, 2024
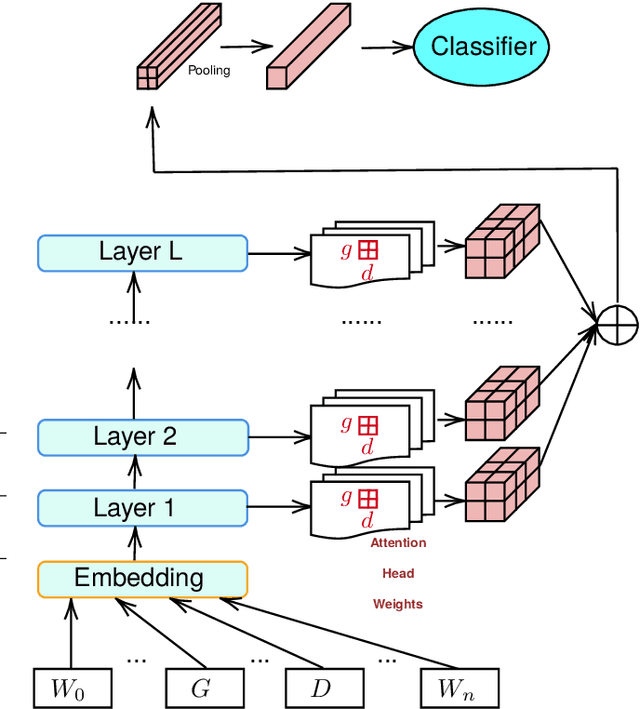
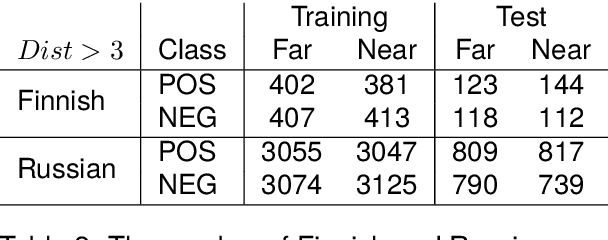
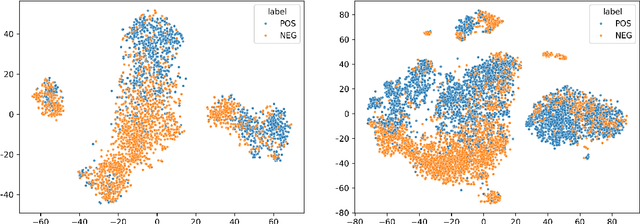
This paper investigates what insights about linguistic features and what knowledge about the structure of natural language can be obtained from the encodings in transformer language models.In particular, we explore how BERT encodes the government relation between constituents in a sentence. We use several probing classifiers, and data from two morphologically rich languages. Our experiments show that information about government is encoded across all transformer layers, but predominantly in the early layers of the model. We find that, for both languages, a small number of attention heads encode enough information about the government relations to enable us to train a classifier capable of discovering new, previously unknown types of government, never seen in the training data. Currently, data is lacking for the research community working on grammatical constructions, and government in particular. We release the Government Bank -- a dataset defining the government relations for thousands of lemmas in the languages in our experiments.