 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Rates for the Regret of Offline Reinforcement Learning
Paper and Code
Jan 31, 2021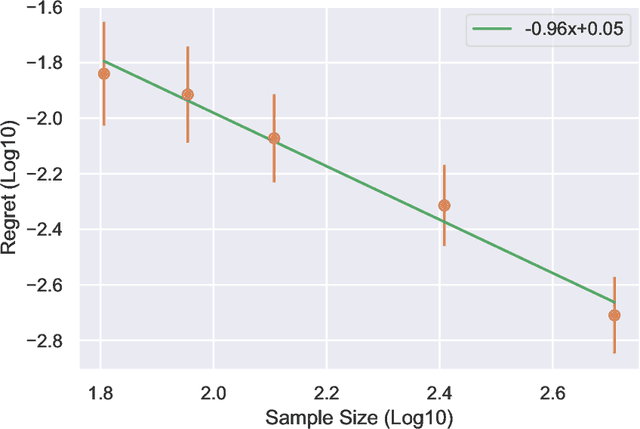
We study the regret of reinforcement learning from offline data generated by a fixed behavior policy in an infinite-horizon discounted Markov decision process (MDP). While existing analyses of common approaches, such as fitted $Q$-iteration (FQI), suggest a $O(1/\sqrt{n})$ convergence for regret, empirical behavior exhibits much faster convergence. In this paper, we present a finer regret analysis that exactly characterizes this phenomenon by providing fast rates for the regret convergence. First, we show that given any estimate for the optimal quality function $Q^*$, the regret of the policy it defines converges at a rate given by the exponentiation of the $Q^*$-estimate's pointwise convergence rate, thus speeding it up. The level of exponentiation depends on the level of noise in the decision-making problem, rather than the estimation problem. We establish such noise levels for linear and tabular MDPs as examples. Second, we provide new analyses of FQI and Bellman residual minimization to establish the correct pointwise convergence guarantees. As specific cases, our results imply $O(1/n)$ regret rates in linear cases and $\exp(-\Omega(n))$ regret rates in tabular cases.