 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgeryV2: Bridging the Gap Between Model Merging and Multi-Task Learning with Deep Representation Surgery
Oct 18, 2024



Model merging-based multitask learning (MTL) offers a promising approach for performing MTL by merging multiple expert models without requiring access to raw training data. However, in this paper, we examine the merged model's representation distribution and uncover a critical issue of "representation bias". This bias arises from a significant distribution gap between the representations of the merged and expert models, leading to the suboptimal performance of the merged MTL model. To address this challenge, we first propose a representation surgery solution called Surgery. Surgery is a lightweight, task-specific module that aligns the final layer representations of the merged model with those of the expert models, effectively alleviating bias and improving the merged model's performance. Despite these improvements, a performance gap remains compared to the traditional MTL method. Further analysis reveals that representation bias phenomena exist at each layer of the merged model, and aligning representations only in the last layer is insufficient for fully reducing systemic bias because biases introduced at each layer can accumulate and interact in complex ways. To tackle this, we then propose a more comprehensive solution, deep representation surgery (also called SurgeryV2), which mitigates representation bias across all layers, and thus bridges the performance gap between model merging-based MTL and traditional MTL. Finally, we design an unsupervised optimization objective to optimize both the Surgery and SurgeryV2 modules. Our experimental results show that incorporating these modules into state-of-the-art (SOTA) model merging schemes leads to significant performance gains. Notably, our SurgeryV2 scheme reaches almost the same level as individual expert models or the traditional MTL model. The code is available at \url{https://github.com/EnnengYang/SurgeryV2}.
Towards Real-World Blind Face Restoration with Generative Diffusion Prior
Dec 25, 2023
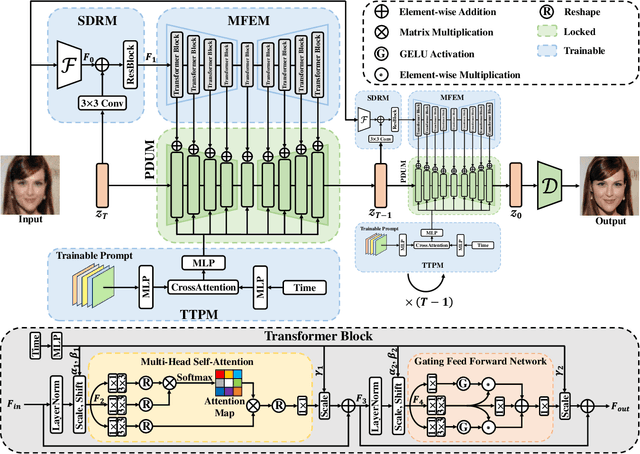
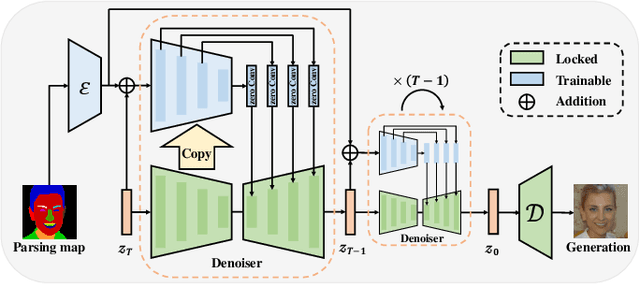

Blind face restoration is an important task in computer vision and has gained significant attention due to its wide-range applications. In this work, we delve into the potential of leveraging the pretrained Stable Diffusion for blind face restoration. We propose BFRffusion which is thoughtfully designed to effectively extract features from low-quality face images and could restore realistic and faithful facial details with the generative prior of the pretrained Stable Diffusion. In addition, we build a privacy-preserving face dataset called PFHQ with balanced attributes like race, gender, and age. This dataset can serve as a viable alternative for training blind face restoration methods, effectively addressing privacy and bias concerns usually associated with the real face datasets. Through an extensive series of experiments, we demonstrate that our BFRffusion achieves state-of-the-art performance on both synthetic and real-world public testing datasets for blind face restoration and our PFHQ dataset is an available resource for training blind face restoration networks. The codes, pretrained models, and dataset are released at https://github.com/chenxx89/BFRffusion.
Blind Face Restoration for Under-Display Camera via Dictionary Guided Transformer
Aug 20, 2023



By hiding the front-facing camera below the display panel, Under-Display Camera (UDC) provides users with a full-screen experience. However, due to the characteristics of the display, images taken by UDC suffer from significant quality degradation. Methods have been proposed to tackle UDC image restoration and advances have been achieved. There are still no specialized methods and datasets for restoring UDC face images, which may be the most common problem in the UDC scene. To this end, considering color filtering, brightness attenuation, and diffraction in the imaging process of UDC, we propose a two-stage network UDC Degradation Model Network named UDC-DMNet to synthesize UDC images by modeling the processes of UDC imaging. Then we use UDC-DMNet and high-quality face images from FFHQ and CelebA-Test to create UDC face training datasets FFHQ-P/T and testing datasets CelebA-Test-P/T for UDC face restoration. We propose a novel dictionary-guided transformer network named DGFormer. Introducing the facial component dictionary and the characteristics of the UDC image in the restoration makes DGFormer capable of addressing blind face restoration in UDC scenarios. Experiments show that our DGFormer and UDC-DMNet achieve state-of-the-art performance.