 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFracture interactive geodesic active contours for bone segmentation
Sep 18, 2025For bone segmentation, the classical geodesic active contour model is usually limited by its indiscriminate feature extraction, and then struggles to handle the phenomena of edge obstruction, edge leakage and bone fracture. Thus, we propose a fracture interactive geodesic active contour algorithm tailored for bone segmentation, which can better capture bone features and perform robustly to the presence of bone fractures and soft tissues. Inspired by orthopedic knowledge, we construct a novel edge-detector function that combines the intensity and gradient norm, which guides the contour towards bone edges without being obstructed by other soft tissues and therefore reduces mis-segmentation. Furthermore, distance information, where fracture prompts can be embedded, is introduced into the contour evolution as an adaptive step size to stabilize the evolution and help the contour stop at bone edges and fractures. This embedding provides a way to interact with bone fractures and improves the accuracy in the fracture regions. Experiments in pelvic and ankle segmentation demonstrate the effectiveness on addressing the aforementioned problems and show an accurate, stable and consistent performance, indicating a broader application in other bone anatomies. Our algorithm also provides insights into combining the domain knowledge and deep neural networks.
MatterChat: A Multi-Modal LLM for Material Science
Feb 18, 2025


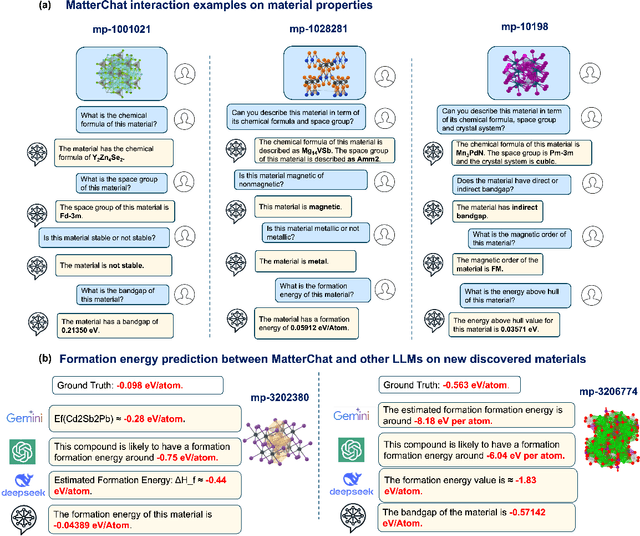
Understanding and predicting the properties of inorganic materials is crucial for accelerating advancements in materials science and driving applications in energy, electronics, and beyond. Integrating material structure data with language-based information through multi-modal large language models (LLMs) offers great potential to support these efforts by enhancing human-AI interaction. However, a key challenge lies in integrating atomic structures at full resolution into LLMs. In this work, we introduce MatterChat, a versatile structure-aware multi-modal LLM that unifies material structural data and textual inputs into a single cohesive model. MatterChat employs a bridging module to effectively align a pretrained machine learning interatomic potential with a pretrained LLM, reducing training costs and enhancing flexibility. Our results demonstrate that MatterChat significantly improves performance in material property prediction and human-AI interaction, surpassing general-purpose LLMs such as GPT-4. We also demonstrate its usefulness in applications such as more advanced scientific reasoning and step-by-step material synthesis.
Rubik's Optical Neural Networks: Multi-task Learning with Physics-aware Rotation Architecture
May 02, 2023



Recently, there are increasing efforts on advancing optical neural networks (ONNs), which bring significant advantages for machine learning (ML) in terms of power efficiency, parallelism, and computational speed. With the considerable benefits in computation speed and energy efficiency, there are significant interests in leveraging ONNs into medical sensing, security screening, drug detection, and autonomous driving. However, due to the challenge of implementing reconfigurability, deploying multi-task learning (MTL) algorithms on ONNs requires re-building and duplicating the physical diffractive systems, which significantly degrades the energy and cost efficiency in practical application scenarios. This work presents a novel ONNs architecture, namely, \textit{RubikONNs}, which utilizes the physical properties of optical systems to encode multiple feed-forward functions by physically rotating the hardware similarly to rotating a \textit{Rubik's Cube}. To optimize MTL performance on RubikONNs, two domain-specific physics-aware training algorithms \textit{RotAgg} and \textit{RotSeq} are proposed. Our experimental results demonstrate more than 4$\times$ improvements in energy and cost efficiency with marginal accuracy degradation compared to the state-of-the-art approaches.
Physics-aware Roughness Optimization for Diffractive Optical Neural Networks
Apr 04, 2023As a representative next-generation device/circuit technology beyond CMOS, diffractive optical neural networks (DONNs) have shown promising advantages over conventional deep neural networks due to extreme fast computation speed (light speed) and low energy consumption. However, there is a mismatch, i.e., significant prediction accuracy loss, between the DONN numerical modelling and physical optical device deployment, because of the interpixel interaction within the diffractive layers. In this work, we propose a physics-aware diffractive optical neural network training framework to reduce the performance difference between numerical modeling and practical deployment. Specifically, we propose the roughness modeling regularization in the training process and integrate the physics-aware sparsification method to introduce sparsity to the phase masks to reduce sharp phase changes between adjacent pixels in diffractive layers. We further develop $2\pi$ periodic optimization to reduce the roughness of the phase masks to preserve the performance of DONN. Experiment results demonstrate that, compared to state-of-the-arts, our physics-aware optimization can provide $35.7\%$, $34.2\%$, $28.1\%$, and $27.3\%$ reduction in roughness with only accuracy loss on MNIST, FMNIST, KMNIST, and EMNIST, respectively.
Scientific Computing with Diffractive Optical Neural Networks
Feb 12, 2023Diffractive optical neural networks (DONNs) have been emerging as a high-throughput and energy-efficient hardware platform to perform all-optical machine learning (ML) in machine vision systems. However, the current demonstrated applications of DONNs are largely straightforward image classification tasks, which undermines the prospect of developing and utilizing such hardware for other ML applications. Here, we numerically and experimentally demonstrate the deployment of an all-optical reconfigurable DONNs system for scientific computing, including guiding two-dimensional quantum material synthesis, predicting the properties of nanomaterials and small molecular cancer drugs, predicting the device response of nanopatterned integrated photonic power splitters, and the dynamic stabilization of an inverted pendulum with reinforcement learning. Despite a large variety of input data structures, we develop a universal feature engineering approach to convert categorical input features to the images that can be processed in the DONNs system. Our results open up new opportunities of employing DONNs systems for a broad range of ML applications.
Physics-aware Differentiable Discrete Codesign for Diffractive Optical Neural Networks
Sep 28, 2022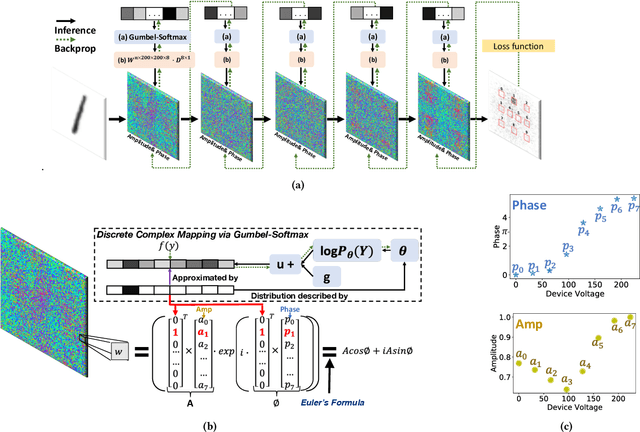
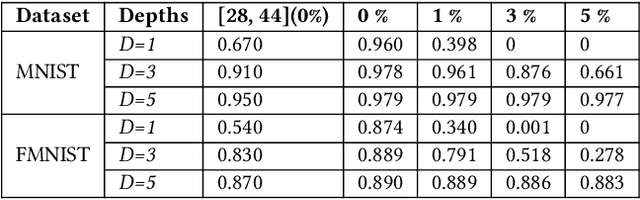
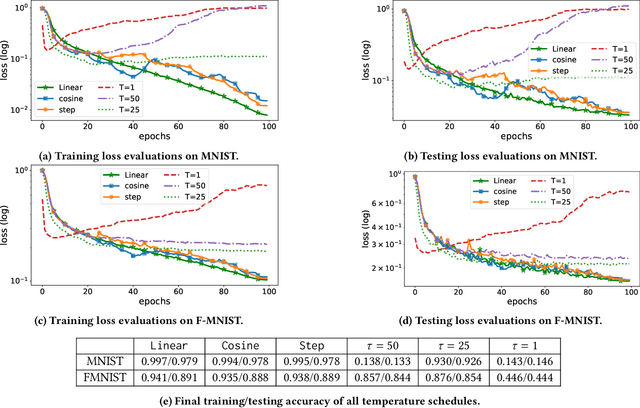
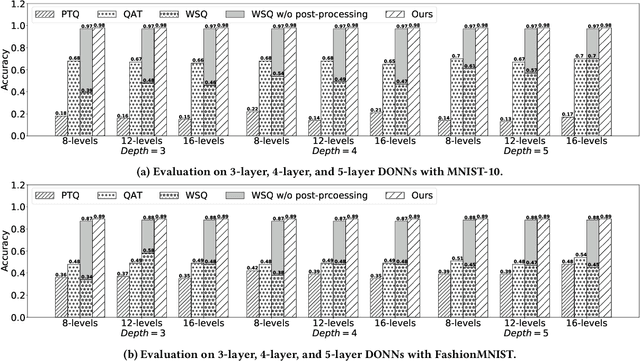
Diffractive optical neural networks (DONNs) have attracted lots of attention as they bring significant advantages in terms of power efficiency, parallelism, and computational speed compared with conventional deep neural networks (DNNs), which have intrinsic limitations when implemented on digital platforms. However, inversely mapping algorithm-trained physical model parameters onto real-world optical devices with discrete values is a non-trivial task as existing optical devices have non-unified discrete levels and non-monotonic properties. This work proposes a novel device-to-system hardware-software codesign framework, which enables efficient physics-aware training of DONNs w.r.t arbitrary experimental measured optical devices across layers. Specifically, Gumbel-Softmax is employed to enable differentiable discrete mapping from real-world device parameters into the forward function of DONNs, where the physical parameters in DONNs can be trained by simply minimizing the loss function of the ML task. The results have demonstrated that our proposed framework offers significant advantages over conventional quantization-based methods, especially with low-precision optical devices. Finally, the proposed algorithm is fully verified with physical experimental optical systems in low-precision settings.
Multi-Task Learning in Diffractive Deep Neural Networks via Hardware-Software Co-design
Dec 16, 2020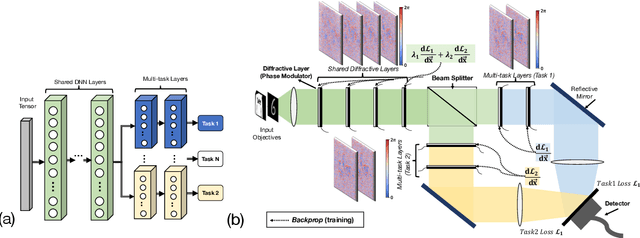


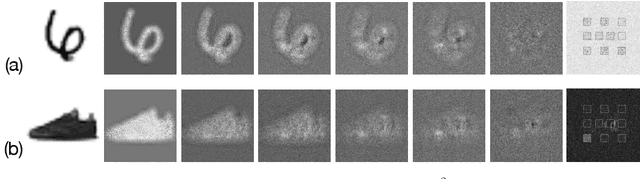
Deep neural networks (DNNs) have substantial computational requirements, which greatly limit their performance in resource-constrained environments. Recently, there are increasing efforts on optical neural networks and optical computing based DNNs hardware, which bring significant advantages for deep learning systems in terms of their power efficiency, parallelism and computational speed. Among them, free-space diffractive deep neural networks (D$^2$NNs) based on the light diffraction, feature millions of neurons in each layer interconnected with neurons in neighboring layers. However, due to the challenge of implementing reconfigurability, deploying different DNNs algorithms requires re-building and duplicating the physical diffractive systems, which significantly degrades the hardware efficiency in practical application scenarios. Thus, this work proposes a novel hardware-software co-design method that enables robust and noise-resilient Multi-task Learning in D$^2$2NNs. Our experimental results demonstrate significant improvements in versatility and hardware efficiency, and also demonstrate the robustness of proposed multi-task D$^2$NN architecture under wide noise ranges of all system components. In addition, we propose a domain-specific regularization algorithm for training the proposed multi-task architecture, which can be used to flexibly adjust the desired performance for each task.