 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection
Jan 27, 2026Current AI-Generated Image (AIGI) detection approaches predominantly rely on binary classification to distinguish real from synthetic images, often lacking interpretable or convincing evidence to substantiate their decisions. This limitation stems from existing AIGI detection benchmarks, which, despite featuring a broad collection of synthetic images, remain restricted in their coverage of artifact diversity and lack detailed, localized annotations. To bridge this gap, we introduce a fine-grained benchmark towards eXplainable AI-Generated image Detection, named X-AIGD, which provides pixel-level, categorized annotations of perceptual artifacts, spanning low-level distortions, high-level semantics, and cognitive-level counterfactuals. These comprehensive annotations facilitate fine-grained interpretability evaluation and deeper insight into model decision-making processes. Our extensive investigation using X-AIGD provides several key insights: (1) Existing AIGI detectors demonstrate negligible reliance on perceptual artifacts, even at the most basic distortion level. (2) While AIGI detectors can be trained to identify specific artifacts, they still substantially base their judgment on uninterpretable features. (3) Explicitly aligning model attention with artifact regions can increase the interpretability and generalization of detectors. The data and code are available at: https://github.com/Coxy7/X-AIGD.
A Large-scale Dataset for Robust Complex Anime Scene Text Detection
Oct 09, 2025Current text detection datasets primarily target natural or document scenes, where text typically appear in regular font and shapes, monotonous colors, and orderly layouts. The text usually arranged along straight or curved lines. However, these characteristics differ significantly from anime scenes, where text is often diverse in style, irregularly arranged, and easily confused with complex visual elements such as symbols and decorative patterns. Text in anime scene also includes a large number of handwritten and stylized fonts. Motivated by this gap, we introduce AnimeText, a large-scale dataset containing 735K images and 4.2M annotated text blocks. It features hierarchical annotations and hard negative samples tailored for anime scenarios. %Cross-dataset evaluations using state-of-the-art methods demonstrate that models trained on AnimeText achieve superior performance in anime text detection tasks compared to existing datasets. To evaluate the robustness of AnimeText in complex anime scenes, we conducted cross-dataset benchmarking using state-of-the-art text detection methods. Experimental results demonstrate that models trained on AnimeText outperform those trained on existing datasets in anime scene text detection tasks. AnimeText on HuggingFace: https://huggingface.co/datasets/deepghs/AnimeText
Decoder-Only LLMs are Better Controllers for Diffusion Models
Feb 06, 2025Groundbreaking advancements in text-to-image generation have recently been achieved with the emergence of diffusion models. These models exhibit a remarkable ability to generate highly artistic and intricately detailed images based on textual prompts. However, obtaining desired generation outcomes often necessitates repetitive trials of manipulating text prompts just like casting spells on a magic mirror, and the reason behind that is the limited capability of semantic understanding inherent in current image generation models. Specifically, existing diffusion models encode the text prompt input with a pre-trained encoder structure, which is usually trained on a limited number of image-caption pairs. The state-of-the-art large language models (LLMs) based on the decoder-only structure have shown a powerful semantic understanding capability as their architectures are more suitable for training on very large-scale unlabeled data. In this work, we propose to enhance text-to-image diffusion models by borrowing the strength of semantic understanding from large language models, and devise a simple yet effective adapter to allow the diffusion models to be compatible with the decoder-only structure. Meanwhile, we also provide a supporting theoretical analysis with various architectures (e.g., encoder-only, encoder-decoder, and decoder-only), and conduct extensive empirical evaluations to verify its effectiveness. The experimental results show that the enhanced models with our adapter module are superior to the stat-of-the-art models in terms of text-to-image generation quality and reliability.
Towards Better Adversarial Purification via Adversarial Denoising Diffusion Training
Apr 22, 2024

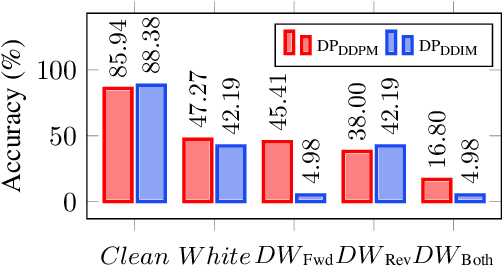

Recently, diffusion-based purification (DBP) has emerged as a promising approach for defending against adversarial attacks. However, previous studies have used questionable methods to evaluate the robustness of DBP models, their explanations of DBP robustness also lack experimental support. We re-examine DBP robustness using precise gradient, and discuss the impact of stochasticity on DBP robustness. To better explain DBP robustness, we assess DBP robustness under a novel attack setting, Deterministic White-box, and pinpoint stochasticity as the main factor in DBP robustness. Our results suggest that DBP models rely on stochasticity to evade the most effective attack direction, rather than directly countering adversarial perturbations. To improve the robustness of DBP models, we propose Adversarial Denoising Diffusion Training (ADDT). This technique uses Classifier-Guided Perturbation Optimization (CGPO) to generate adversarial perturbation through guidance from a pre-trained classifier, and uses Rank-Based Gaussian Mapping (RBGM) to convert adversarial pertubation into a normal Gaussian distribution. Empirical results show that ADDT improves the robustness of DBP models. Further experiments confirm that ADDT equips DBP models with the ability to directly counter adversarial perturbations.
DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning
Nov 21, 2022Large-scale text-to-image generation models with an exponential evolution can currently synthesize high-resolution, feature-rich, high-quality images based on text guidance. However, they are often overwhelmed by words of new concepts, styles, or object entities that always emerge. Although there are some recent attempts to use fine-tuning or prompt-tuning methods to teach the model a new concept as a new pseudo-word from a given reference image set, these methods are not only still difficult to synthesize diverse and high-quality images without distortion and artifacts, but also suffer from low controllability. To address these problems, we propose a DreamArtist method that employs a learning strategy of contrastive prompt-tuning, which introduces both positive and negative embeddings as pseudo-words and trains them jointly. The positive embedding aggressively learns characteristics in the reference image to drive the model diversified generation, while the negative embedding introspects in a self-supervised manner to rectify the mistakes and inadequacies from positive embedding in reverse. It learns not only what is correct but also what should be avoided. Extensive experiments on image quality and diversity analysis, controllability analysis, model learning analysis and task expansion have demonstrated that our model learns not only concept but also form, content and context. Pseudo-words of DreamArtist have similar properties as true words to generate high-quality images.
Adversarially-Aware Robust Object Detector
Jul 22, 2022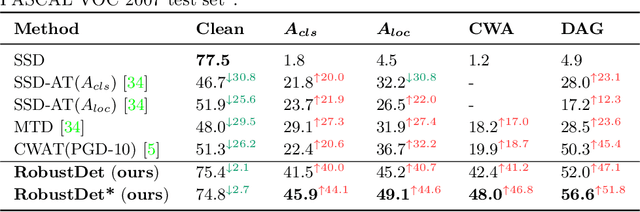
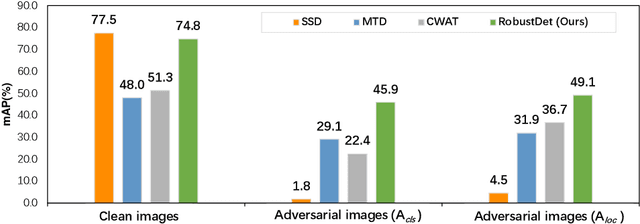
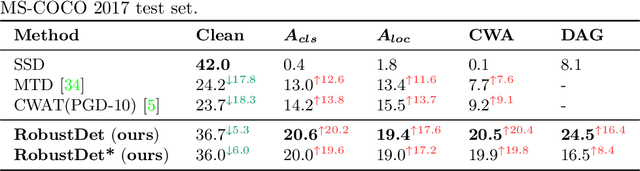
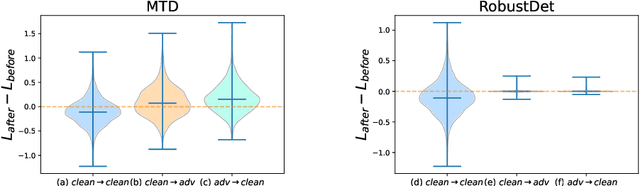
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper