 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDF-CR: Iterative Diffusion Process for Divide-and-Conquer Cloud Removal in Remote-sensing Images
Mar 18, 2024



Deep learning technologies have demonstrated their effectiveness in removing cloud cover from optical remote-sensing images. Convolutional Neural Networks (CNNs) exert dominance in the cloud removal tasks. However, constrained by the inherent limitations of convolutional operations, CNNs can address only a modest fraction of cloud occlusion. In recent years, diffusion models have achieved state-of-the-art (SOTA) proficiency in image generation and reconstruction due to their formidable generative capabilities. Inspired by the rapid development of diffusion models, we first present an iterative diffusion process for cloud removal (IDF-CR), which exhibits a strong generative capabilities to achieve component divide-and-conquer cloud removal. IDF-CR consists of a pixel space cloud removal module (Pixel-CR) and a latent space iterative noise diffusion network (IND). Specifically, IDF-CR is divided into two-stage models that address pixel space and latent space. The two-stage model facilitates a strategic transition from preliminary cloud reduction to meticulous detail refinement. In the pixel space stage, Pixel-CR initiates the processing of cloudy images, yielding a suboptimal cloud removal prior to providing the diffusion model with prior cloud removal knowledge. In the latent space stage, the diffusion model transforms low-quality cloud removal into high-quality clean output. We refine the Stable Diffusion by implementing ControlNet. In addition, an unsupervised iterative noise refinement (INR) module is introduced for diffusion model to optimize the distribution of the predicted noise, thereby enhancing advanced detail recovery. Our model performs best with other SOTA methods, including image reconstruction and optical remote-sensing cloud removal on the optical remote-sensing datasets.
NegVSR: Augmenting Negatives for Generalized Noise Modeling in Real-World Video Super-Resolution
May 24, 2023



The capability of video super-resolution (VSR) to synthesize high-resolution (HR) video from ideal datasets has been demonstrated in many works. However, applying the VSR model to real-world video with unknown and complex degradation remains a challenging task. First, existing degradation metrics in most VSR methods are not able to effectively simulate real-world noise and blur. On the contrary, simple combinations of classical degradation are used for real-world noise modeling, which led to the VSR model often being violated by out-of-distribution noise. Second, many SR models focus on noise simulation and transfer. Nevertheless, the sampled noise is monotonous and limited. To address the aforementioned problems, we propose a Negatives augmentation strategy for generalized noise modeling in Video Super-Resolution (NegVSR) task. Specifically, we first propose sequential noise generation toward real-world data to extract practical noise sequences. Then, the degeneration domain is widely expanded by negative augmentation to build up various yet challenging real-world noise sets. We further propose the augmented negative guidance loss to learn robust features among augmented negatives effectively. Extensive experiments on real-world datasets (e.g., VideoLQ and FLIR) show that our method outperforms state-of-the-art methods with clear margins, especially in visual quality.
Conditioning Optimization of Extreme Learning Machine by Multitask Beetle Antennae Swarm Algorithm
Nov 22, 2018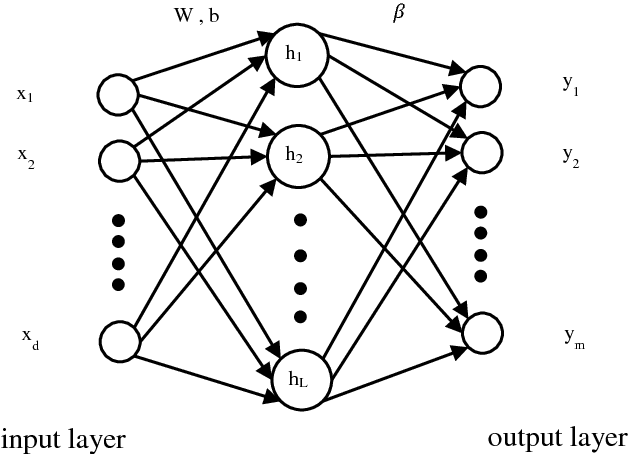

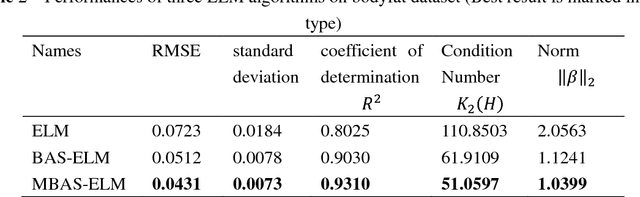

Extreme learning machine (ELM) as a simple and rapid neural network has been shown its good performance in various areas. Different from the general single hidden layer feedforward neural network (SLFN), the input weights and biases in hidden layer of ELM are generated randomly, so that it only takes a little computation overhead to train the model. However, the strategy of selecting input weights and biases at random may result in ill-posed problem. Aiming to optimize the conditioning of ELM, we propose an effective particle swarm heuristic algorithm called Multitask Beetle Antennae Swarm Algorithm (MBAS), which is inspired by the structures of artificial bee colony (ABS) algorithm and Beetle Antennae Search (BAS) algorithm. Then, the proposed MBAS is applied to optimize the input weights and biases of ELM. Experiment results show that the proposed method is capable of simultaneously reducing the condition number and regression error, and achieving good generalization performances.