 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcerns for Self-Localization of Ad-Hoc Arrays Using Time Difference of Arrivals
Aug 01, 2024This document presents some insights and observations regarding the paper that was published in IEEE Transactions on Signal Processing (TSP), titled "Self-Localization of Ad-Hoc Arrays Using Time Difference of Arrivals". In the spirit of constructive feedback, I wish to highlight two key areas of consideration. The first pertains to aspects related to methodology, experimental results, and statements made in the paper. The second part addresses specific equation/typographical errors. This work aims to initiate a constructive dialogue concerning certain aspects of the paper published in IEEE TSP. Our intention is to provide feedback that contributes to the ongoing improvement of the paper's robustness and clarity.
Low Rank Properties for Estimating Microphones Start Time and Sources Emission Time
Jul 22, 2023



Uncertainty in timing information pertaining to the start time of microphone recordings and sources' emission time pose significant challenges in various applications, such as joint microphones and sources localization. Traditional optimization methods, which directly estimate this unknown timing information (UTIm), often fall short compared to approaches exploiting the low-rank property (LRP). LRP encompasses an additional low-rank structure, facilitating a linear constraint on UTIm to help formulate related low-rank structure information. This method allows us to attain globally optimal solutions for UTIm, given proper initialization. However, the initialization process often involves randomness, leading to suboptimal, local minimum values. This paper presents a novel, combined low-rank approximation (CLRA) method designed to mitigate the effects of this random initialization. We introduce three new LRP variants, underpinned by mathematical proof, which allow the UTIm to draw on a richer pool of low-rank structural information. Utilizing this augmented low-rank structural information from both LRP and the proposed variants, we formulate four linear constraints on the UTIm. Employing the proposed CLRA algorithm, we derive global optimal solutions for the UTIm via these four linear constraints.Experimental results highlight the superior performance of our method over existing state-of-the-art approaches, measured in terms of both the recovery number and reduced estimation errors of UTIm.
Are Microphone Signals Alone Sufficient for Joint Microphones and Sources Localization?
May 19, 2023Joint microphones and sources localization can be achieved by using both time of arrival (TOA) and time difference of arrival (TDOA) measurements, even in scenarios where both microphones and sources are asynchronous due to unknown emission time of human voices or sources and unknown recording start time of independent microphones. However, TOA measurements require both microphone signals and the waveform of source signals while TDOA measurements can be obtained using microphone signals alone. In this letter, we explore the sufficiency of using only microphone signals for joint microphones and sources localization by presenting two mapping functions for both TOA and TDOA formulas. Our proposed mapping functions demonstrate that the transformations of TOA and TDOA formulas can be the same, indicating that microphone signals alone are sufficient for joint microphones and sources localization without knowledge of the waveform of source signals. We have validated our proposed mapping functions through both mathematical proof and experimental results.
Justices for Information Bottleneck Theory
May 19, 2023
This study comes as a timely response to mounting criticism of the information bottleneck (IB) theory, injecting fresh perspectives to rectify misconceptions and reaffirm its validity. Firstly, we introduce an auxiliary function to reinterpret the maximal coding rate reduction method as a special yet local optimal case of IB theory. Through this auxiliary function, we clarify the paradox of decreasing mutual information during the application of ReLU activation in deep learning (DL) networks. Secondly, we challenge the doubts about IB theory's applicability by demonstrating its capacity to explain the absence of a compression phase with linear activation functions in hidden layers, when viewed through the lens of the auxiliary function. Lastly, by taking a novel theoretical stance, we provide a new way to interpret the inner organizations of DL networks by using IB theory, aligning them with recent experimental evidence. Thus, this paper serves as an act of justice for IB theory, potentially reinvigorating its standing and application in DL and other fields such as communications and biomedical research.
Conditioning Optimization of Extreme Learning Machine by Multitask Beetle Antennae Swarm Algorithm
Nov 22, 2018

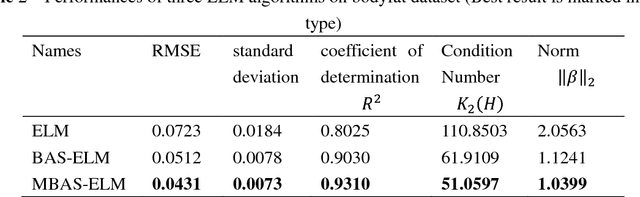

Extreme learning machine (ELM) as a simple and rapid neural network has been shown its good performance in various areas. Different from the general single hidden layer feedforward neural network (SLFN), the input weights and biases in hidden layer of ELM are generated randomly, so that it only takes a little computation overhead to train the model. However, the strategy of selecting input weights and biases at random may result in ill-posed problem. Aiming to optimize the conditioning of ELM, we propose an effective particle swarm heuristic algorithm called Multitask Beetle Antennae Swarm Algorithm (MBAS), which is inspired by the structures of artificial bee colony (ABS) algorithm and Beetle Antennae Search (BAS) algorithm. Then, the proposed MBAS is applied to optimize the input weights and biases of ELM. Experiment results show that the proposed method is capable of simultaneously reducing the condition number and regression error, and achieving good generalization performances.
Sparse Representation Based Augmented Multinomial Logistic Extreme Learning Machine with Weighted Composite Features for Spectral Spatial Hyperspectral Image Classification
Oct 14, 2017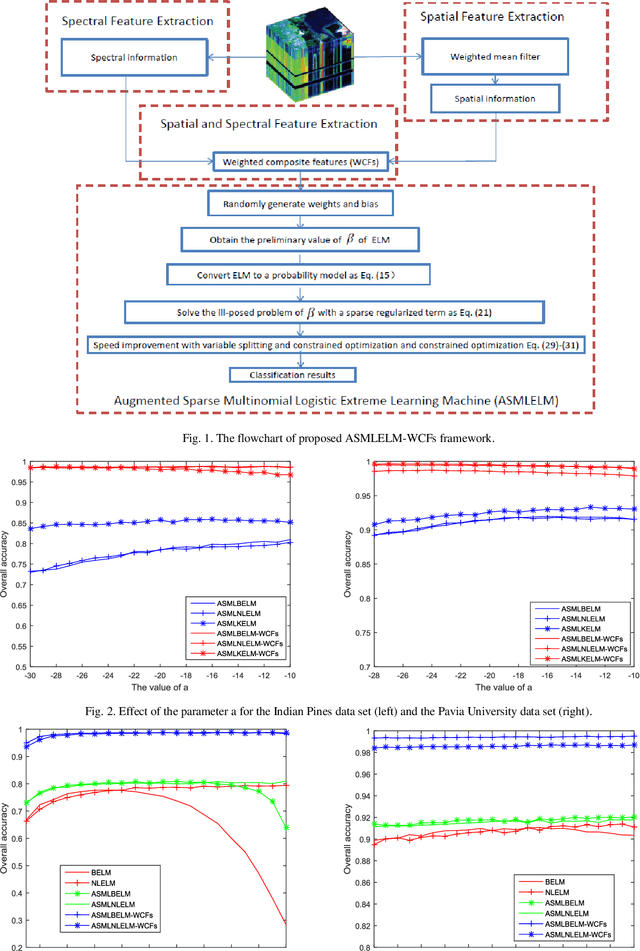
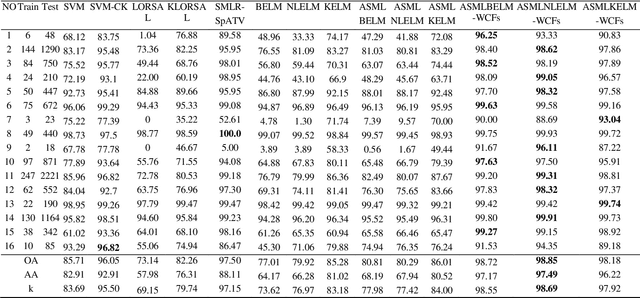
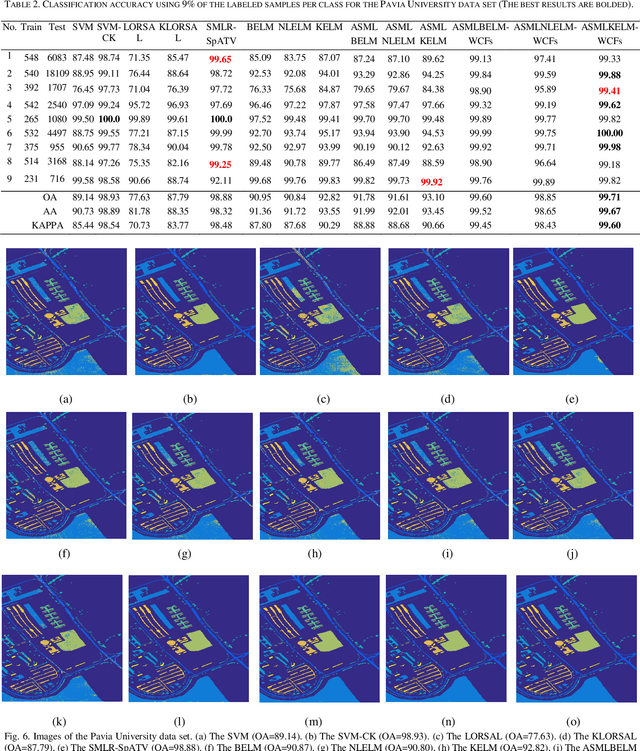
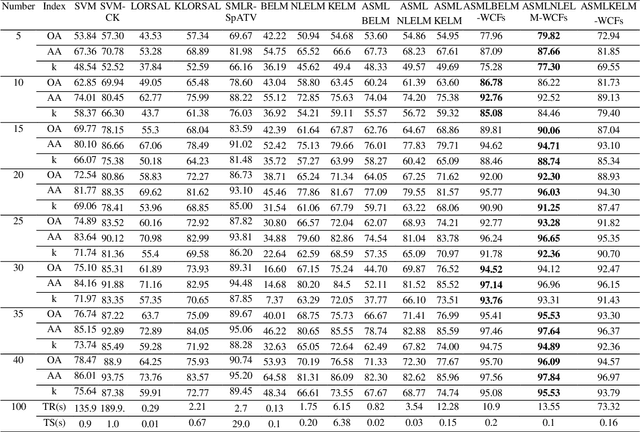
Although extreme learning machine (ELM) has been successfully applied to a number of pattern recognition problems, it fails to pro-vide sufficient good results in hyperspectral image (HSI) classification due to two main drawbacks. The first is due to the random weights and bias of ELM, which may lead to ill-posed problems. The second is the lack of spatial information for classification. To tackle these two problems, in this paper, we propose a new framework for ELM based spectral-spatial classification of HSI, where probabilistic modelling with sparse representation and weighted composite features (WCF) are employed respectively to derive the op-timized output weights and extract spatial features. First, the ELM is represented as a concave logarithmic likelihood function under statistical modelling using the maximum a posteriori (MAP). Second, the sparse representation is applied to the Laplacian prior to effi-ciently determine a logarithmic posterior with a unique maximum in order to solve the ill-posed problem of ELM. The variable splitting and the augmented Lagrangian are subsequently used to further reduce the computation complexity of the proposed algorithm and it has been proven a more efficient method for speed improvement. Third, the spatial information is extracted using the weighted compo-site features (WCFs) to construct the spectral-spatial classification framework. In addition, the lower bound of the proposed method is derived by a rigorous mathematical proof. Experimental results on two publicly available HSI data sets demonstrate that the proposed methodology outperforms ELM and a number of state-of-the-art approaches.
Linear vs Nonlinear Extreme Learning Machine for Spectral-Spatial Classification of Hyperspectral Image
Oct 12, 2017
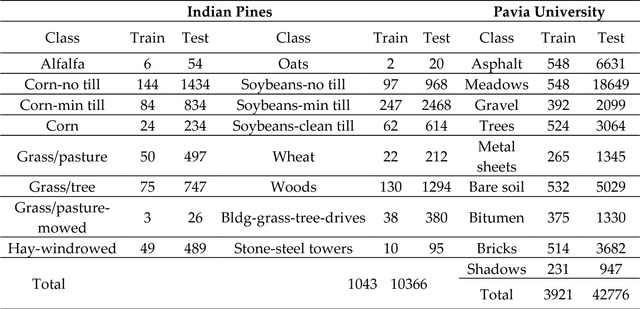
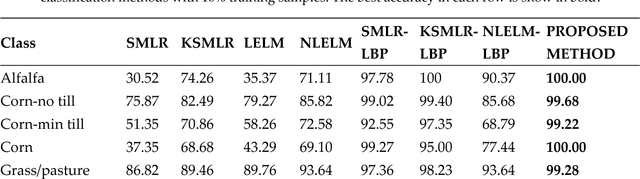
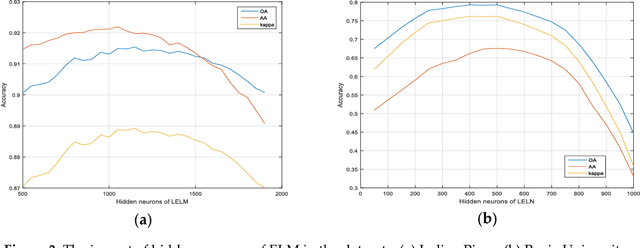
As a new machine learning approach, extreme learning machine (ELM) has received wide attentions due to its good performances. However, when directly applied to the hyperspectral image (HSI) classification, the recognition rate is too low. This is because ELM does not use the spatial information which is very important for HSI classification. In view of this, this paper proposes a new framework for spectral-spatial classification of HSI by combining ELM with loopy belief propagation (LBP). The original ELM is linear, and the nonlinear ELMs (or Kernel ELMs) are the improvement of linear ELM (LELM). However, based on lots of experiments and analysis, we found out that the LELM is a better choice than nonlinear ELM for spectral-spatial classification of HSI. Furthermore, we exploit the marginal probability distribution that uses the whole information in the HSI and learn such distribution using the LBP. The proposed method not only maintain the fast speed of ELM, but also greatly improves the accuracy of classification. The experimental results in the well-known HSI data sets, Indian Pines and Pavia University, demonstrate the good performances of the proposed method.
* 13 pages,8 figures,3 tables,article
Does Normalization Methods Play a Role for Hyperspectral Image Classification?
Oct 09, 2017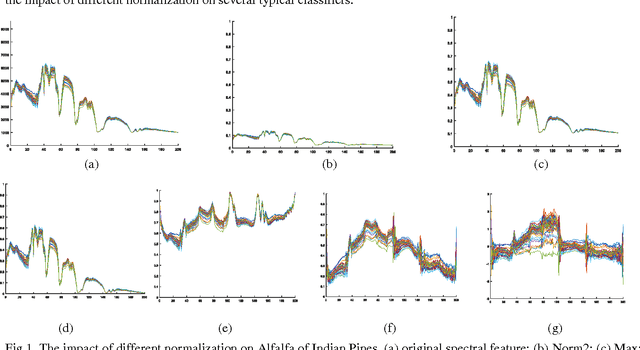
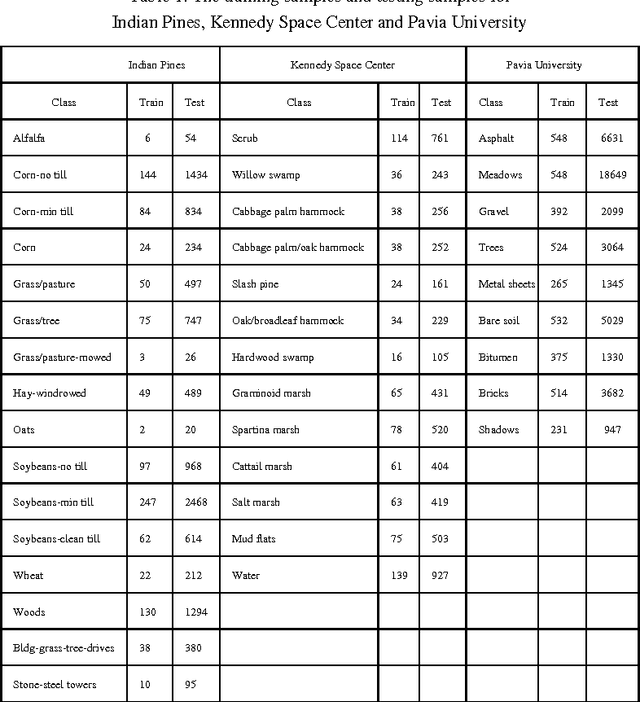
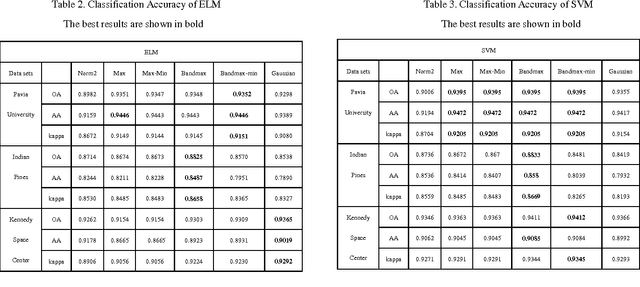
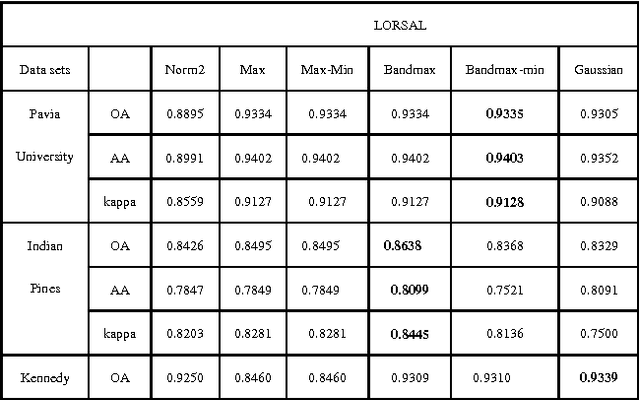
For Hyperspectral image (HSI) datasets, each class have their salient feature and classifiers classify HSI datasets according to the class's saliency features, however, there will be different salient features when use different normalization method. In this letter, we report the effect on classifiers by different normalization methods and recommend the best normalization methods for classifier after analyzing the impact of different normalization methods on classifiers. Pavia University datasets, Indian Pines datasets and Kennedy Space Center datasets will apply to several typical classifiers in order to evaluate and analysis the impact of different normalization methods on typical classifiers.
Extreme Sparse Multinomial Logistic Regression: A Fast and Robust Framework for Hyperspectral Image Classification
Sep 27, 2017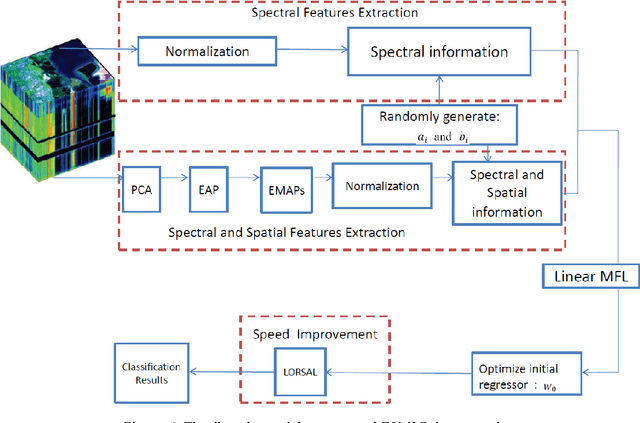
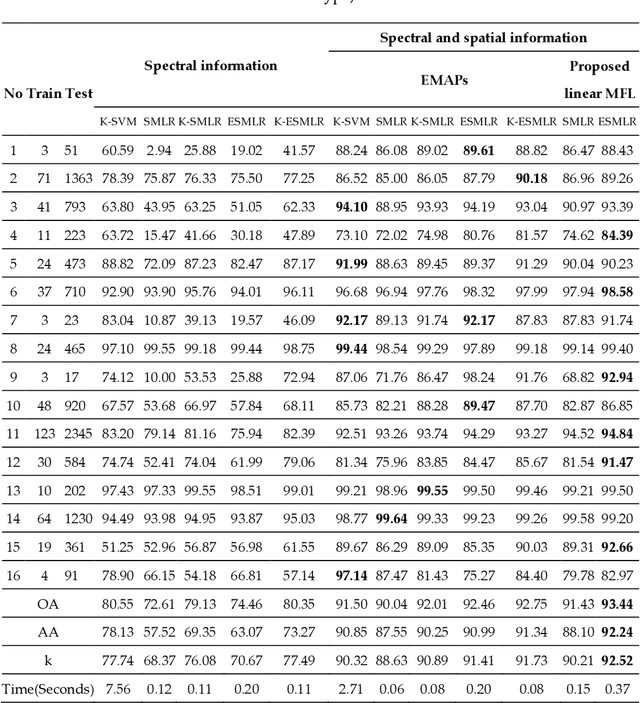
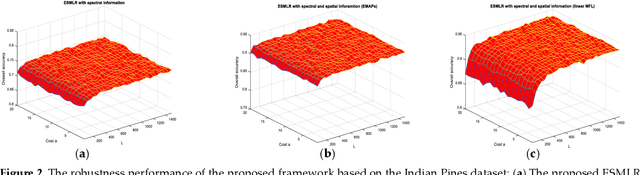
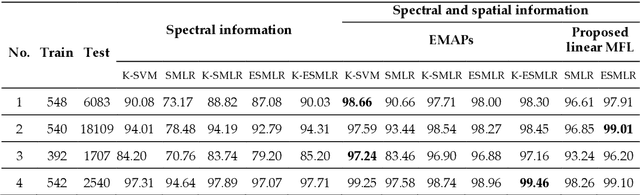
Although the sparse multinomial logistic regression (SMLR) has provided a useful tool for sparse classification, it suffers from inefficacy in dealing with high dimensional features and manually set initial regressor values. This has significantly constrained its applications for hyperspectral image (HSI) classification. In order to tackle these two drawbacks, an extreme sparse multinomial logistic regression (ESMLR) is proposed for effective classification of HSI. First, the HSI dataset is projected to a new feature space with randomly generated weight and bias. Second, an optimization model is established by the Lagrange multiplier method and the dual principle to automatically determine a good initial regressor for SMLR via minimizing the training error and the regressor value. Furthermore, the extended multi-attribute profiles (EMAPs) are utilized for extracting both the spectral and spatial features. A combinational linear multiple features learning (MFL) method is proposed to further enhance the features extracted by ESMLR and EMAPs. Finally, the logistic regression via the variable splitting and the augmented Lagrangian (LORSAL) is adopted in the proposed framework for reducing the computational time. Experiments are conducted on two well-known HSI datasets, namely the Indian Pines dataset and the Pavia University dataset, which have shown the fast and robust performance of the proposed ESMLR framework.
* 14 pages,7 figures,4 tables