 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint multi-dimensional dynamic attention and transformer for general image restoration
Nov 12, 2024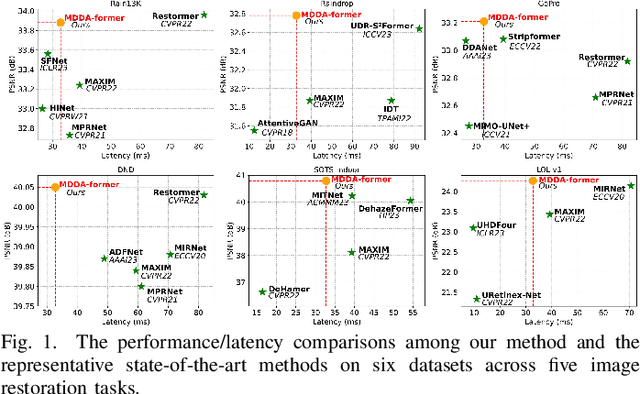



Outdoor images often suffer from severe degradation due to rain, haze, and noise, impairing image quality and challenging high-level tasks. Current image restoration methods struggle to handle complex degradation while maintaining efficiency. This paper introduces a novel image restoration architecture that combines multi-dimensional dynamic attention and self-attention within a U-Net framework. To leverage the global modeling capabilities of transformers and the local modeling capabilities of convolutions, we integrate sole CNNs in the encoder-decoder and sole transformers in the latent layer. Additionally, we design convolutional kernels with selected multi-dimensional dynamic attention to capture diverse degraded inputs efficiently. A transformer block with transposed self-attention further enhances global feature extraction while maintaining efficiency. Extensive experiments demonstrate that our method achieves a better balance between performance and computational complexity across five image restoration tasks: deraining, deblurring, denoising, dehazing, and enhancement, as well as superior performance for high-level vision tasks. The source code will be available at https://github.com/House-yuyu/MDDA-former.
CA-CentripetalNet: A novel anchor-free deep learning framework for hardhat wearing detection
Jul 09, 2023Automatic hardhat wearing detection can strengthen the safety management in construction sites, which is still challenging due to complicated video surveillance scenes. To deal with the poor generalization of previous deep learning based methods, a novel anchor-free deep learning framework called CA-CentripetalNet is proposed for hardhat wearing detection. Two novel schemes are proposed to improve the feature extraction and utilization ability of CA-CentripetalNet, which are vertical-horizontal corner pooling and bounding constrained center attention. The former is designed to realize the comprehensive utilization of marginal features and internal features. The latter is designed to enforce the backbone to pay attention to internal features, which is only used during the training rather than during the detection. Experimental results indicate that the CA-CentripetalNet achieves better performance with the 86.63% mAP (mean Average Precision) with less memory consumption at a reasonable speed than the existing deep learning based methods, especially in case of small-scale hardhats and non-worn-hardhats.
* It has been accepted for the journal of Signal, Image and Video Processing, which is a complete version. It is noted that it has been deleted for future publishing
Conditioning Optimization of Extreme Learning Machine by Multitask Beetle Antennae Swarm Algorithm
Nov 22, 2018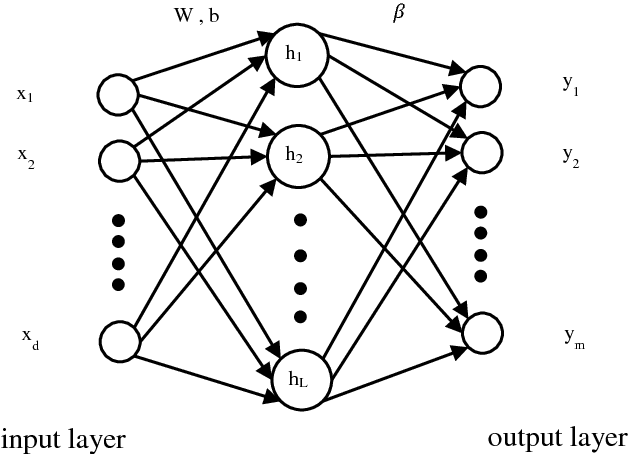

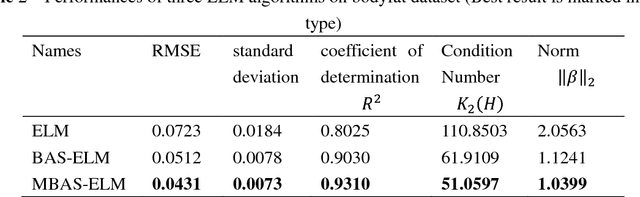

Extreme learning machine (ELM) as a simple and rapid neural network has been shown its good performance in various areas. Different from the general single hidden layer feedforward neural network (SLFN), the input weights and biases in hidden layer of ELM are generated randomly, so that it only takes a little computation overhead to train the model. However, the strategy of selecting input weights and biases at random may result in ill-posed problem. Aiming to optimize the conditioning of ELM, we propose an effective particle swarm heuristic algorithm called Multitask Beetle Antennae Swarm Algorithm (MBAS), which is inspired by the structures of artificial bee colony (ABS) algorithm and Beetle Antennae Search (BAS) algorithm. Then, the proposed MBAS is applied to optimize the input weights and biases of ELM. Experiment results show that the proposed method is capable of simultaneously reducing the condition number and regression error, and achieving good generalization performances.
Detecting facial landmarks in the video based on a hybrid framework
Sep 21, 2016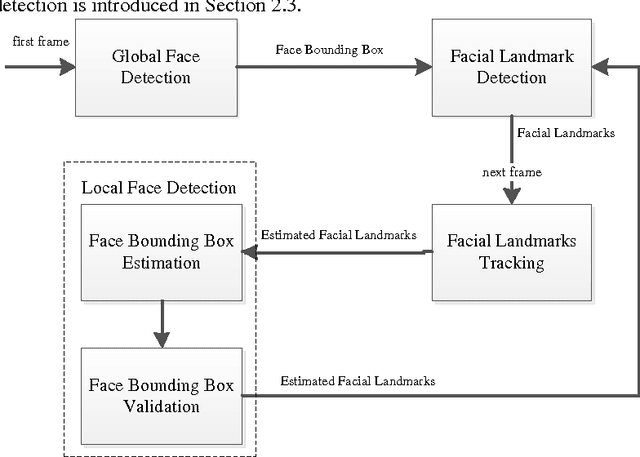



To dynamically detect the facial landmarks in the video, we propose a novel hybrid framework termed as detection-tracking-detection (DTD). First, the face bounding box is achieved from the first frame of the video sequence based on a traditional face detection method. Then, a landmark detector detects the facial landmarks, which is based on a cascaded deep convolution neural network (DCNN). Next, the face bounding box in the current frame is estimated and validated after the facial landmarks in the previous frame are tracked based on the median flow. Finally, the facial landmarks in the current frame are exactly detected from the validated face bounding box via the landmark detector. Experimental results indicate that the proposed framework can detect the facial landmarks in the video sequence more effectively and with lower consuming time compared to the frame-by-frame method via the DCNN.