 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting facial landmarks in the video based on a hybrid framework
Sep 21, 2016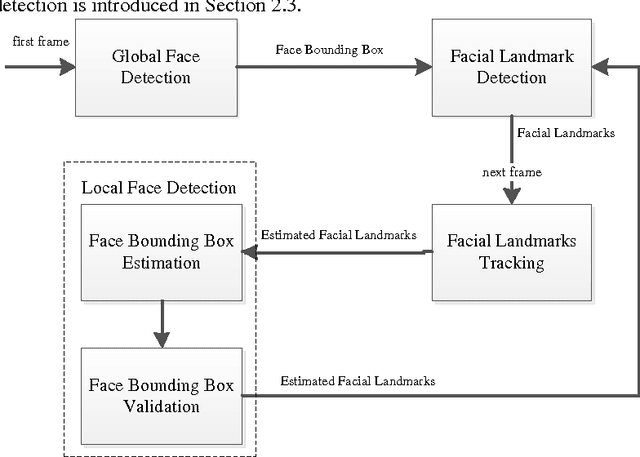



To dynamically detect the facial landmarks in the video, we propose a novel hybrid framework termed as detection-tracking-detection (DTD). First, the face bounding box is achieved from the first frame of the video sequence based on a traditional face detection method. Then, a landmark detector detects the facial landmarks, which is based on a cascaded deep convolution neural network (DCNN). Next, the face bounding box in the current frame is estimated and validated after the facial landmarks in the previous frame are tracked based on the median flow. Finally, the facial landmarks in the current frame are exactly detected from the validated face bounding box via the landmark detector. Experimental results indicate that the proposed framework can detect the facial landmarks in the video sequence more effectively and with lower consuming time compared to the frame-by-frame method via the DCNN.