 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint multi-dimensional dynamic attention and transformer for general image restoration
Paper and Code
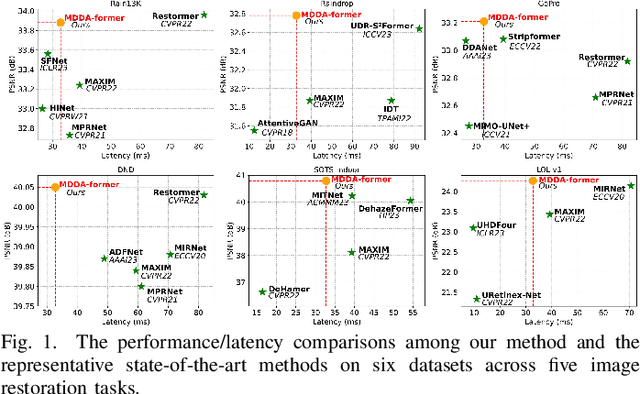



Outdoor images often suffer from severe degradation due to rain, haze, and noise, impairing image quality and challenging high-level tasks. Current image restoration methods struggle to handle complex degradation while maintaining efficiency. This paper introduces a novel image restoration architecture that combines multi-dimensional dynamic attention and self-attention within a U-Net framework. To leverage the global modeling capabilities of transformers and the local modeling capabilities of convolutions, we integrate sole CNNs in the encoder-decoder and sole transformers in the latent layer. Additionally, we design convolutional kernels with selected multi-dimensional dynamic attention to capture diverse degraded inputs efficiently. A transformer block with transposed self-attention further enhances global feature extraction while maintaining efficiency. Extensive experiments demonstrate that our method achieves a better balance between performance and computational complexity across five image restoration tasks: deraining, deblurring, denoising, dehazing, and enhancement, as well as superior performance for high-level vision tasks. The source code will be available at https://github.com/House-yuyu/MDDA-former.