 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Preserving Lip Sync via Audio-Aware Style Reference
Paper and Code
Aug 10, 2024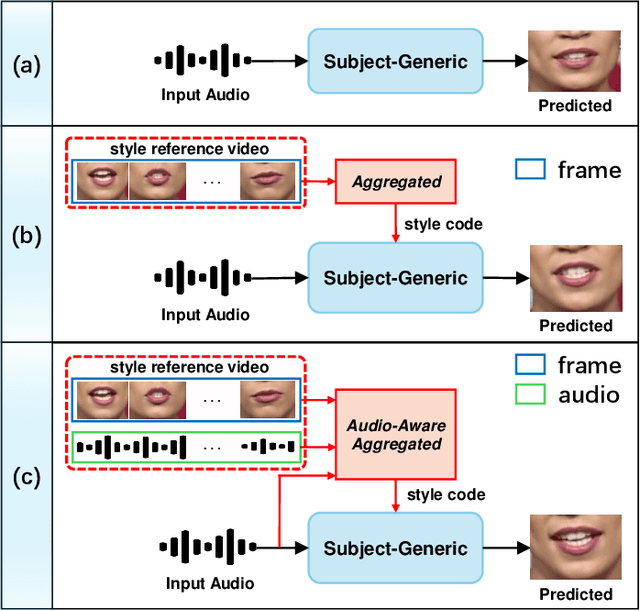
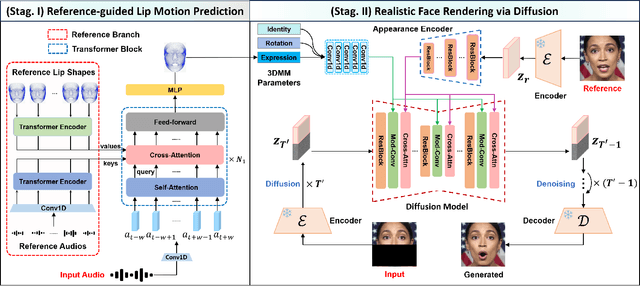

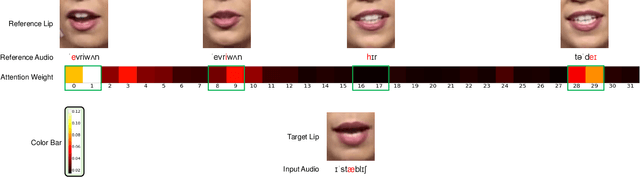
Audio-driven lip sync has recently drawn significant attention due to its widespread application in the multimedia domain. Individuals exhibit distinct lip shapes when speaking the same utterance, attributed to the unique speaking styles of individuals, posing a notable challenge for audio-driven lip sync. Earlier methods for such task often bypassed the modeling of personalized speaking styles, resulting in sub-optimal lip sync conforming to the general styles. Recent lip sync techniques attempt to guide the lip sync for arbitrary audio by aggregating information from a style reference video, yet they can not preserve the speaking styles well due to their inaccuracy in style aggregation. This work proposes an innovative audio-aware style reference scheme that effectively leverages the relationships between input audio and reference audio from style reference video to address the style-preserving audio-driven lip sync. Specifically, we first develop an advanced Transformer-based model adept at predicting lip motion corresponding to the input audio, augmented by the style information aggregated through cross-attention layers from style reference video. Afterwards, to better render the lip motion into realistic talking face video, we devise a conditional latent diffusion model, integrating lip motion through modulated convolutional layers and fusing reference facial images via spatial cross-attention layers. Extensive experiments validate the efficacy of the proposed approach in achieving precise lip sync, preserving speaking styles, and generating high-fidelity, realistic talking face videos.