 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Decision Transformer for Stochastic Driving Environments
Sep 28, 2023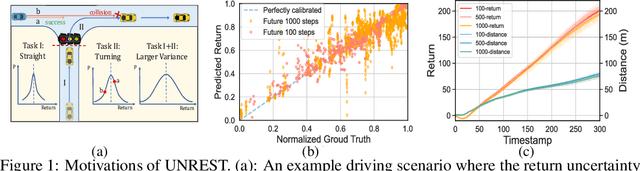
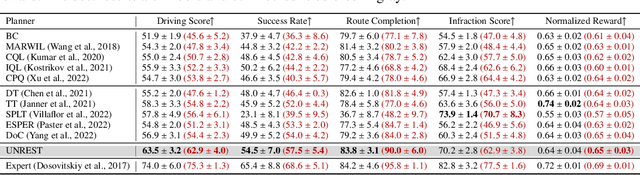
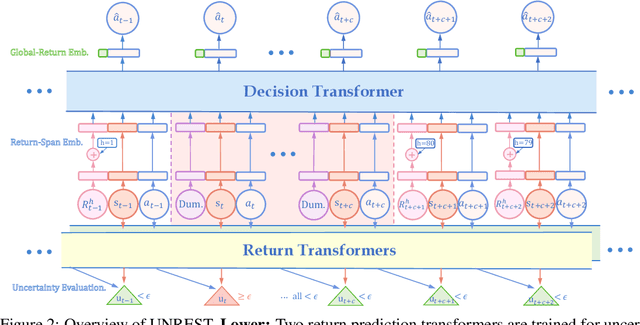
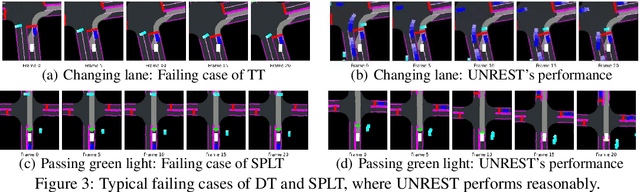
Offline Reinforcement Learning (RL) has emerged as a promising framework for learning policies without active interactions, making it especially appealing for autonomous driving tasks. Recent successes of Transformers inspire casting offline RL as sequence modeling, which performs well in long-horizon tasks. However, they are overly optimistic in stochastic environments with incorrect assumptions that the same goal can be consistently achieved by identical actions. In this paper, we introduce an UNcertainty-awaRE deciSion Transformer (UNREST) for planning in stochastic driving environments without introducing additional transition or complex generative models. Specifically, UNREST estimates state uncertainties by the conditional mutual information between transitions and returns, and segments sequences accordingly. Discovering the `uncertainty accumulation' and `temporal locality' properties of driving environments, UNREST replaces the global returns in decision transformers with less uncertain truncated returns, to learn from true outcomes of agent actions rather than environment transitions. We also dynamically evaluate environmental uncertainty during inference for cautious planning. Extensive experimental results demonstrate UNREST's superior performance in various driving scenarios and the power of our uncertainty estimation strategy.
Boosting Offline Reinforcement Learning for Autonomous Driving with Hierarchical Latent Skills
Sep 24, 2023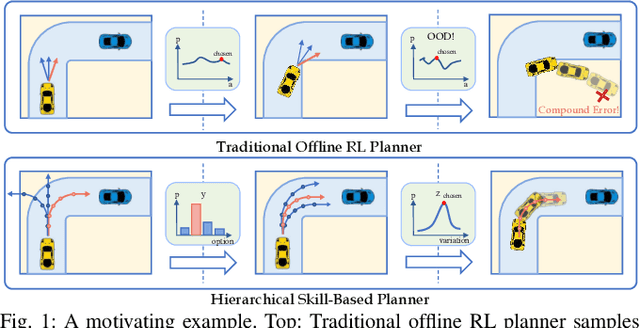
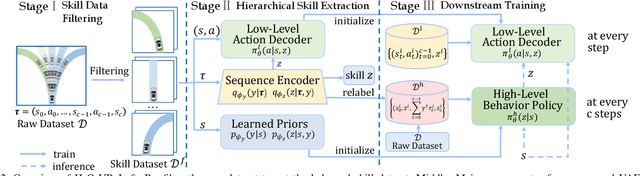
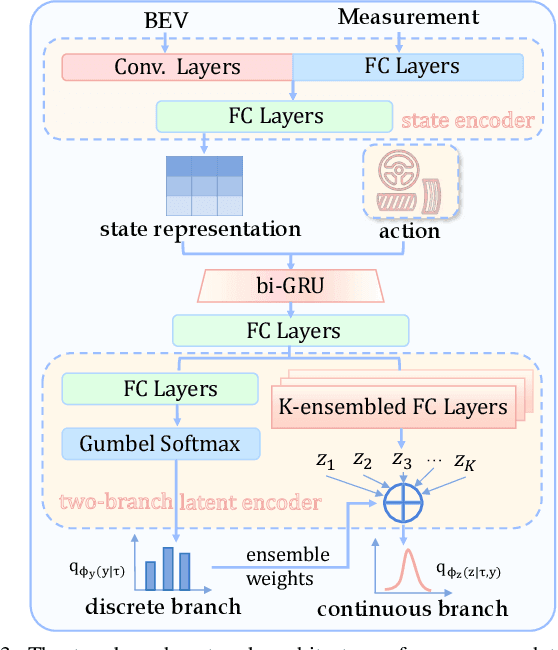
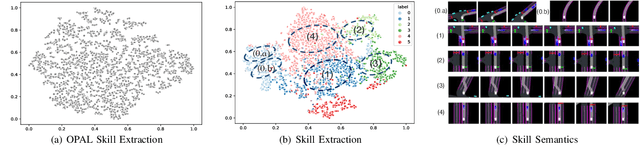
Learning-based vehicle planning is receiving increasing attention with the emergence of diverse driving simulators and large-scale driving datasets. While offline reinforcement learning (RL) is well suited for these safety-critical tasks, it still struggles to plan over extended periods. In this work, we present a skill-based framework that enhances offline RL to overcome the long-horizon vehicle planning challenge. Specifically, we design a variational autoencoder (VAE) to learn skills from offline demonstrations. To mitigate posterior collapse of common VAEs, we introduce a two-branch sequence encoder to capture both discrete options and continuous variations of the complex driving skills. The final policy treats learned skills as actions and can be trained by any off-the-shelf offline RL algorithms. This facilitates a shift in focus from per-step actions to temporally extended skills, thereby enabling long-term reasoning into the future. Extensive results on CARLA prove that our model consistently outperforms strong baselines at both training and new scenarios. Additional visualizations and experiments demonstrate the interpretability and transferability of extracted skills.
ProphNet: Efficient Agent-Centric Motion Forecasting with Anchor-Informed Proposals
Mar 21, 2023Motion forecasting is a key module in an autonomous driving system. Due to the heterogeneous nature of multi-sourced input, multimodality in agent behavior, and low latency required by onboard deployment, this task is notoriously challenging. To cope with these difficulties, this paper proposes a novel agent-centric model with anchor-informed proposals for efficient multimodal motion prediction. We design a modality-agnostic strategy to concisely encode the complex input in a unified manner. We generate diverse proposals, fused with anchors bearing goal-oriented scene context, to induce multimodal prediction that covers a wide range of future trajectories. Our network architecture is highly uniform and succinct, leading to an efficient model amenable for real-world driving deployment. Experiments reveal that our agent-centric network compares favorably with the state-of-the-art methods in prediction accuracy, while achieving scene-centric level inference latency.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Comprehensive Reactive Safety: No Need For A Trajectory If You Have A Strategy
Jul 11, 2022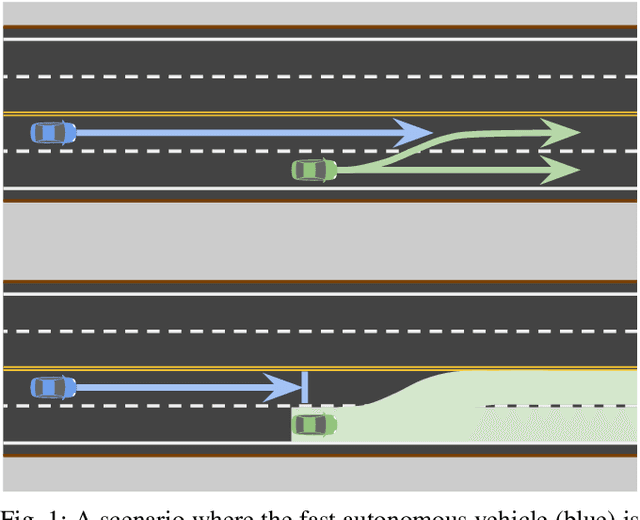
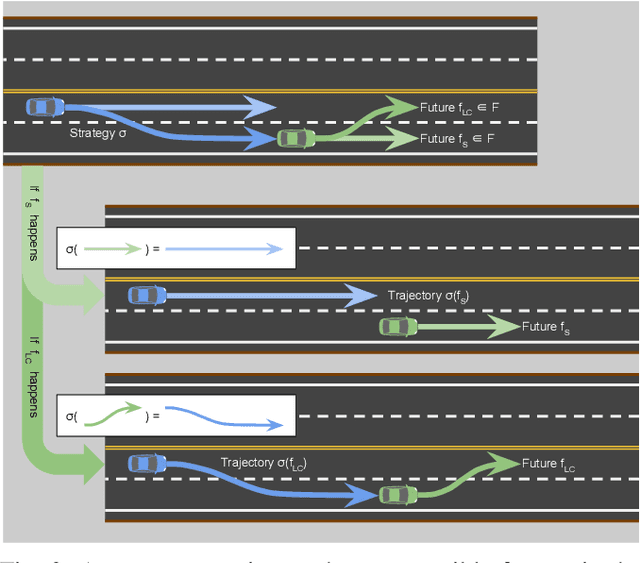
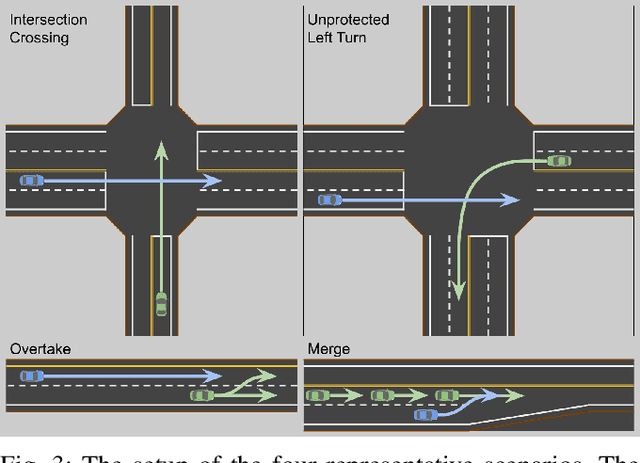

Safety guarantees in motion planning for autonomous driving typically involve certifying the trajectory to be collision-free under any motion of the uncontrollable participants in the environment, such as the human-driven vehicles on the road. As a result they usually employ a conservative bound on the behavior of such participants, such as reachability analysis. We point out that planning trajectories to rigorously avoid the entirety of the reachable regions is unnecessary and too restrictive, because observing the environment in the future will allow us to prune away most of them; disregarding this ability to react to future updates could prohibit solutions to scenarios that are easily navigated by human drivers. We propose to account for the autonomous vehicle's reactions to future environment changes by a novel safety framework, Comprehensive Reactive Safety. Validated in simulations in several urban driving scenarios such as unprotected left turns and lane merging, the resulting planning algorithm called Reactive ILQR demonstrates strong negotiation capabilities and better safety at the same time.
Path-Aware Graph Attention for HD Maps in Motion Prediction
Feb 23, 2022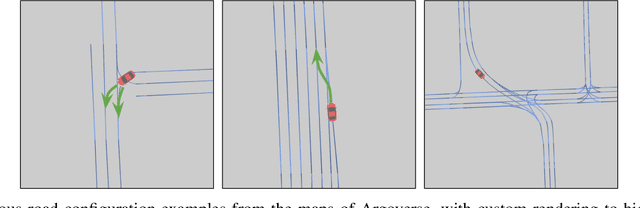
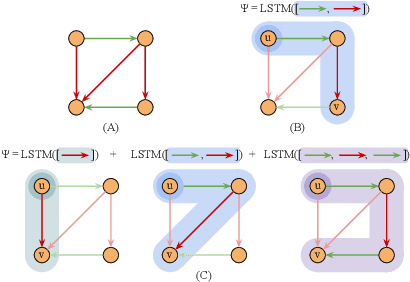
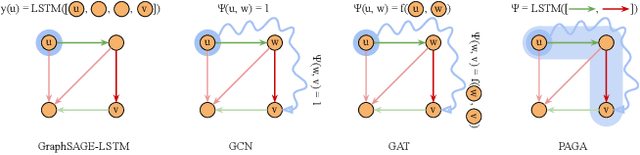
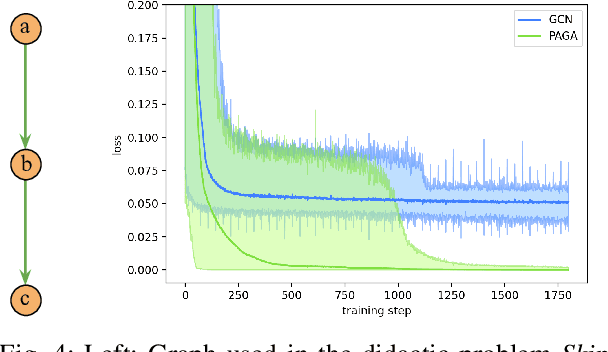
The success of motion prediction for autonomous driving relies on integration of information from the HD maps. As maps are naturally graph-structured, investigation on graph neural networks (GNNs) for encoding HD maps is burgeoning in recent years. However, unlike many other applications where GNNs have been straightforwardly deployed, HD maps are heterogeneous graphs where vertices (lanes) are connected by edges (lane-lane interaction relationships) of various nature, and most graph-based models are not designed to understand the variety of edge types which provide crucial cues for predicting how the agents would travel the lanes. To overcome this challenge, we propose Path-Aware Graph Attention, a novel attention architecture that infers the attention between two vertices by parsing the sequence of edges forming the paths that connect them. Our analysis illustrates how the proposed attention mechanism can facilitate learning in a didactic problem where existing graph networks like GCN struggle. By improving map encoding, the proposed model surpasses previous state of the art on the Argoverse Motion Forecasting dataset, and won the first place in the 2021 Argoverse Motion Forecasting Competition.