 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Decision Transformer for Stochastic Driving Environments
Paper and Code
Sep 28, 2023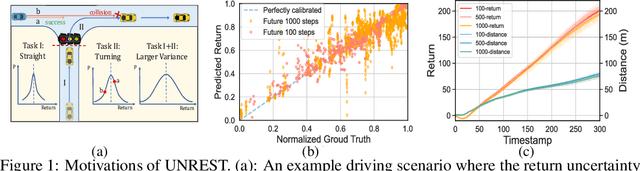
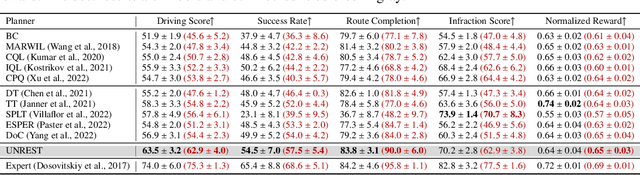
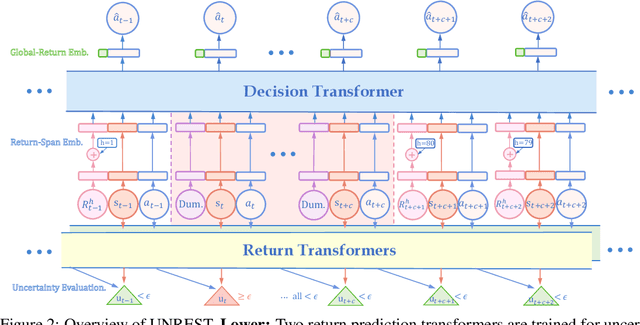
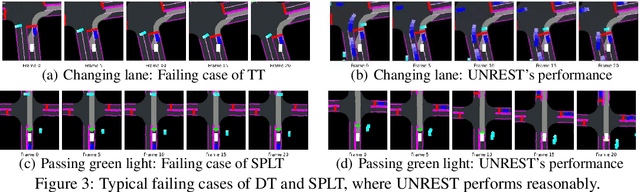
Offline Reinforcement Learning (RL) has emerged as a promising framework for learning policies without active interactions, making it especially appealing for autonomous driving tasks. Recent successes of Transformers inspire casting offline RL as sequence modeling, which performs well in long-horizon tasks. However, they are overly optimistic in stochastic environments with incorrect assumptions that the same goal can be consistently achieved by identical actions. In this paper, we introduce an UNcertainty-awaRE deciSion Transformer (UNREST) for planning in stochastic driving environments without introducing additional transition or complex generative models. Specifically, UNREST estimates state uncertainties by the conditional mutual information between transitions and returns, and segments sequences accordingly. Discovering the `uncertainty accumulation' and `temporal locality' properties of driving environments, UNREST replaces the global returns in decision transformers with less uncertain truncated returns, to learn from true outcomes of agent actions rather than environment transitions. We also dynamically evaluate environmental uncertainty during inference for cautious planning. Extensive experimental results demonstrate UNREST's superior performance in various driving scenarios and the power of our uncertainty estimation strategy.