Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics
Paper and Code
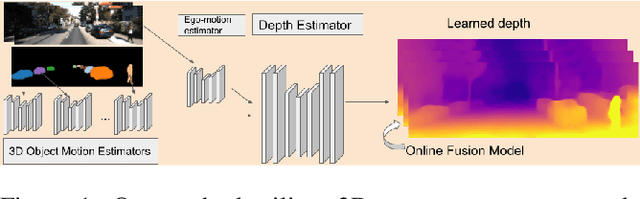
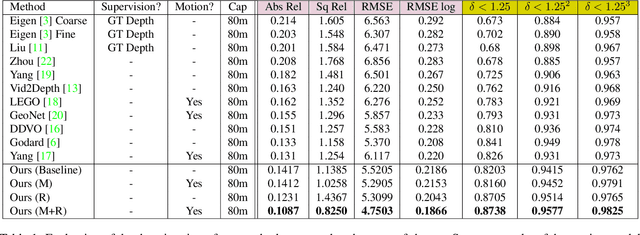
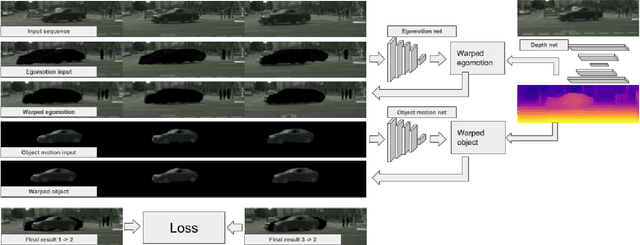

We present an approach which takes advantage of both structure and semantics for unsupervised monocular learning of depth and ego-motion. More specifically, we model the motion of individual objects and learn their 3D motion vector jointly with depth and ego-motion. We obtain more accurate results, especially for challenging dynamic scenes not addressed by previous approaches. This is an extended version of Casser et al. [AAAI'19]. Code and models have been open sourced at https://sites.google.com/corp/view/struct2depth.
* CVPR Workshop on Visual Odometry & Computer Vision Applications Based
on Location Clues (VOCVALC), 2019. This is an extension of arXiv:1811.06152:
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised
Learning from Monocular Videos. Thirty-Third AAAI Conference on Artificial
Intelligence (AAAI'19)
View paper on