 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHR-VILAGE-3K3M: A Human Respiratory Viral Immunization Longitudinal Gene Expression Dataset for Systems Immunity
May 19, 2025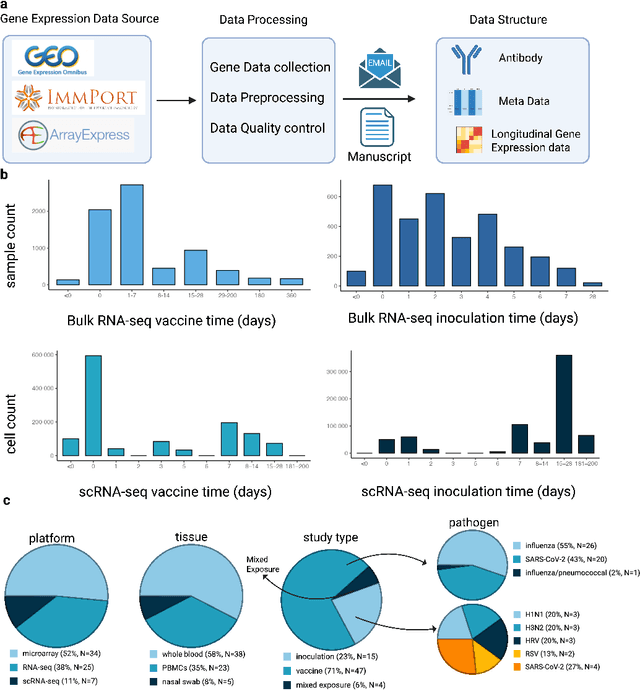



Respiratory viral infections pose a global health burden, yet the cellular immune responses driving protection or pathology remain unclear. Natural infection cohorts often lack pre-exposure baseline data and structured temporal sampling. In contrast, inoculation and vaccination trials generate insightful longitudinal transcriptomic data. However, the scattering of these datasets across platforms, along with inconsistent metadata and preprocessing procedure, hinders AI-driven discovery. To address these challenges, we developed the Human Respiratory Viral Immunization LongitudinAl Gene Expression (HR-VILAGE-3K3M) repository: an AI-ready, rigorously curated dataset that integrates 14,136 RNA-seq profiles from 3,178 subjects across 66 studies encompassing over 2.56 million cells. Spanning vaccination, inoculation, and mixed exposures, the dataset includes microarray, bulk RNA-seq, and single-cell RNA-seq from whole blood, PBMCs, and nasal swabs, sourced from GEO, ImmPort, and ArrayExpress. We harmonized subject-level metadata, standardized outcome measures, applied unified preprocessing pipelines with rigorous quality control, and aligned all data to official gene symbols. To demonstrate the utility of HR-VILAGE-3K3M, we performed predictive modeling of vaccine responders and evaluated batch-effect correction methods. Beyond these initial demonstrations, it supports diverse systems immunology applications and benchmarking of feature selection and transfer learning algorithms. Its scale and heterogeneity also make it ideal for pretraining foundation models of the human immune response and for advancing multimodal learning frameworks. As the largest longitudinal transcriptomic resource for human respiratory viral immunization, it provides an accessible platform for reproducible AI-driven research, accelerating systems immunology and vaccine development against emerging viral threats.
MANGO: A Benchmark for Evaluating Mapping and Navigation Abilities of Large Language Models
Mar 29, 2024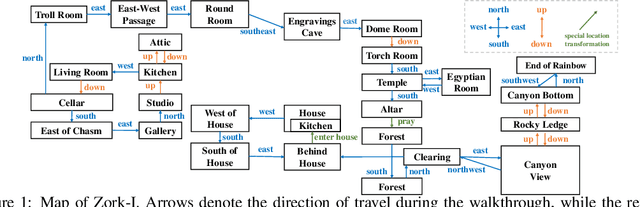
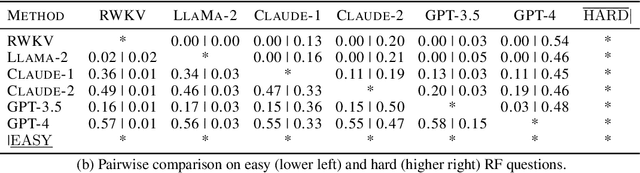
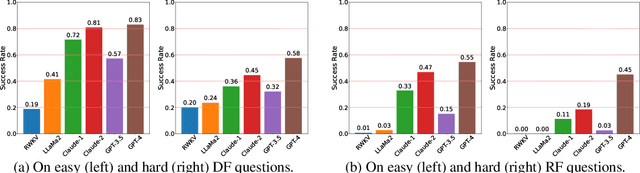
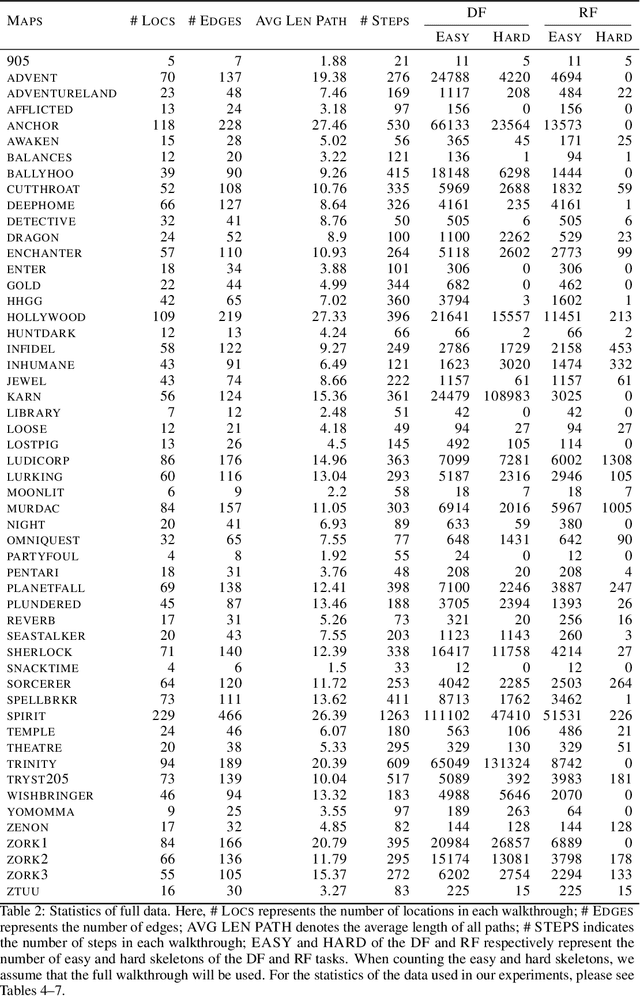
Large language models such as ChatGPT and GPT-4 have recently achieved astonishing performance on a variety of natural language processing tasks. In this paper, we propose MANGO, a benchmark to evaluate their capabilities to perform text-based mapping and navigation. Our benchmark includes 53 mazes taken from a suite of textgames: each maze is paired with a walkthrough that visits every location but does not cover all possible paths. The task is question-answering: for each maze, a large language model reads the walkthrough and answers hundreds of mapping and navigation questions such as "How should you go to Attic from West of House?" and "Where are we if we go north and east from Cellar?". Although these questions are easy to humans, it turns out that even GPT-4, the best-to-date language model, performs poorly at answering them. Further, our experiments suggest that a strong mapping and navigation ability would benefit large language models in performing relevant downstream tasks, such as playing textgames. Our MANGO benchmark will facilitate future research on methods that improve the mapping and navigation capabilities of language models. We host our leaderboard, data, code, and evaluation program at https://mango.ttic.edu and https://github.com/oaklight/mango/.
Personality Understanding of Fictional Characters during Book Reading
May 26, 2023



Comprehending characters' personalities is a crucial aspect of story reading. As readers engage with a story, their understanding of a character evolves based on new events and information; and multiple fine-grained aspects of personalities can be perceived. This leads to a natural problem of situated and fine-grained personality understanding. The problem has not been studied in the NLP field, primarily due to the lack of appropriate datasets mimicking the process of book reading. We present the first labeled dataset PersoNet for this problem. Our novel annotation strategy involves annotating user notes from online reading apps as a proxy for the original books. Experiments and human studies indicate that our dataset construction is both efficient and accurate; and our task heavily relies on long-term context to achieve accurate predictions for both machines and humans. The dataset is available at https://github.com/Gorov/personet_acl23.
DeepTree: Modeling Trees with Situated Latents
May 09, 2023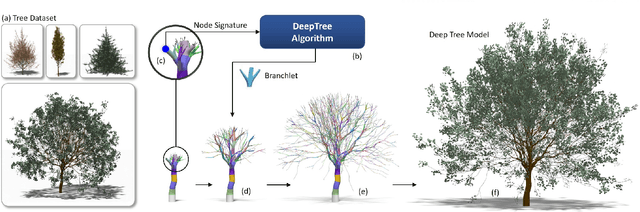
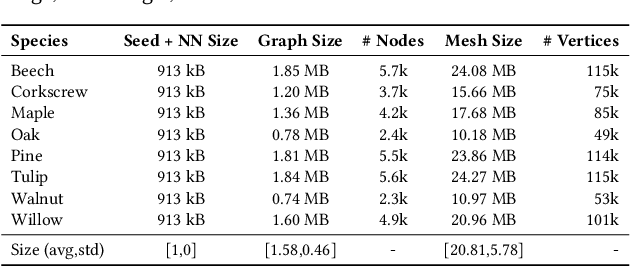
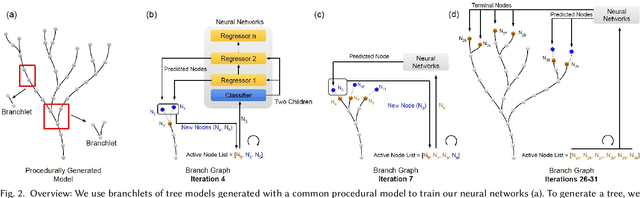
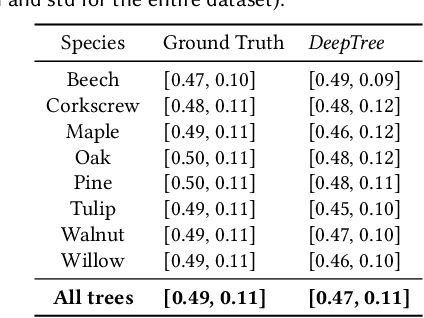
In this paper, we propose DeepTree, a novel method for modeling trees based on learning developmental rules for branching structures instead of manually defining them. We call our deep neural model situated latent because its behavior is determined by the intrinsic state -- encoded as a latent space of a deep neural model -- and by the extrinsic (environmental) data that is situated as the location in the 3D space and on the tree structure. We use a neural network pipeline to train a situated latent space that allows us to locally predict branch growth only based on a single node in the branch graph of a tree model. We use this representation to progressively develop new branch nodes, thereby mimicking the growth process of trees. Starting from a root node, a tree is generated by iteratively querying the neural network on the newly added nodes resulting in the branching structure of the whole tree. Our method enables generating a wide variety of tree shapes without the need to define intricate parameters that control their growth and behavior. Furthermore, we show that the situated latents can also be used to encode the environmental response of tree models, e.g., when trees grow next to obstacles. We validate the effectiveness of our method by measuring the similarity of our tree models and by procedurally generated ones based on a number of established metrics for tree form.
Can Large Language Models Play Text Games Well? Current State-of-the-Art and Open Questions
Apr 06, 2023Large language models (LLMs) such as ChatGPT and GPT-4 have recently demonstrated their remarkable abilities of communicating with human users. In this technical report, we take an initiative to investigate their capacities of playing text games, in which a player has to understand the environment and respond to situations by having dialogues with the game world. Our experiments show that ChatGPT performs competitively compared to all the existing systems but still exhibits a low level of intelligence. Precisely, ChatGPT can not construct the world model by playing the game or even reading the game manual; it may fail to leverage the world knowledge that it already has; it cannot infer the goal of each step as the game progresses. Our results open up new research questions at the intersection of artificial intelligence, machine learning, and natural language processing.