 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook here! A parametric learning based approach to redirect visual attention
Aug 12, 2020

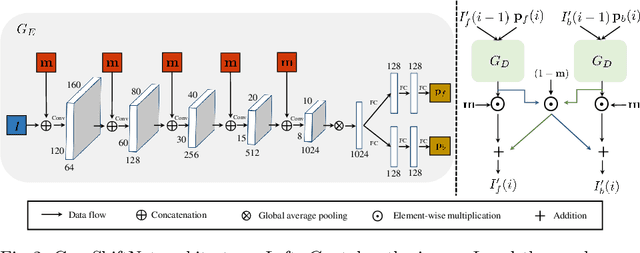
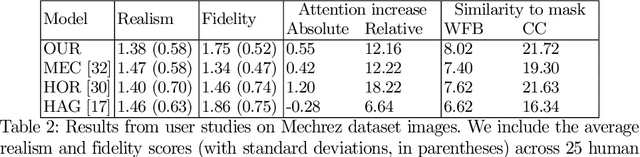
Across photography, marketing, and website design, being able to direct the viewer's attention is a powerful tool. Motivated by professional workflows, we introduce an automatic method to make an image region more attention-capturing via subtle image edits that maintain realism and fidelity to the original. From an input image and a user-provided mask, our GazeShiftNet model predicts a distinct set of global parametric transformations to be applied to the foreground and background image regions separately. We present the results of quantitative and qualitative experiments that demonstrate improvements over prior state-of-the-art. In contrast to existing attention shifting algorithms, our global parametric approach better preserves image semantics and avoids typical generative artifacts. Our edits enable inference at interactive rates on any image size, and easily generalize to videos. Extensions of our model allow for multi-style edits and the ability to both increase and attenuate attention in an image region. Furthermore, users can customize the edited images by dialing the edits up or down via interpolations in parameter space. This paper presents a practical tool that can simplify future image editing pipelines.
Generating Object Stamps
Jan 10, 2020
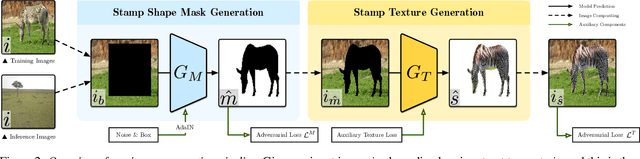
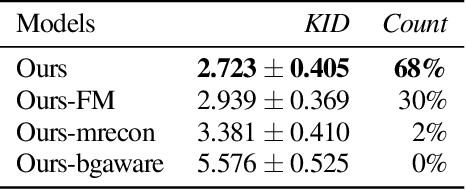
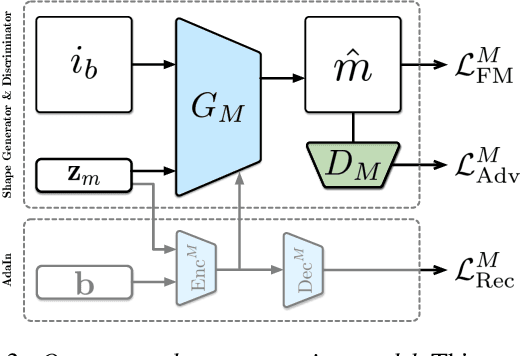
We present an algorithm to generate diverse foreground objects and composite them into background images using a GAN architecture. Given an object class, a user-provided bounding box, and a background image, we first use a mask generator to create an object shape, and then use a texture generator to fill the mask such that the texture integrates with the background. By separating the problem of object insertion into these two stages, we show that our model allows us to improve the realism of diverse object generation that also agrees with the provided background image. Our results on the challenging COCO dataset show improved overall quality and diversity compared to state-of-the-art object insertion approaches.