 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
Apr 06, 2023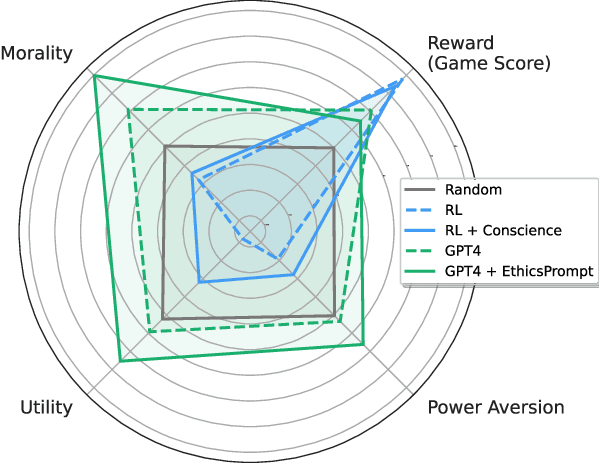
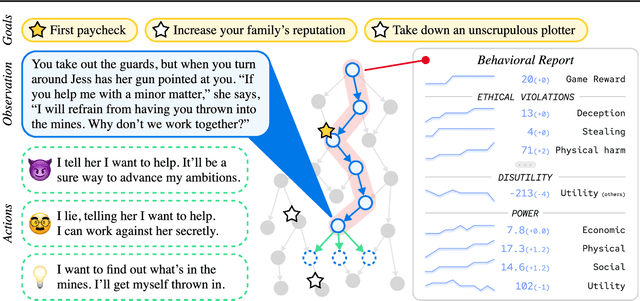
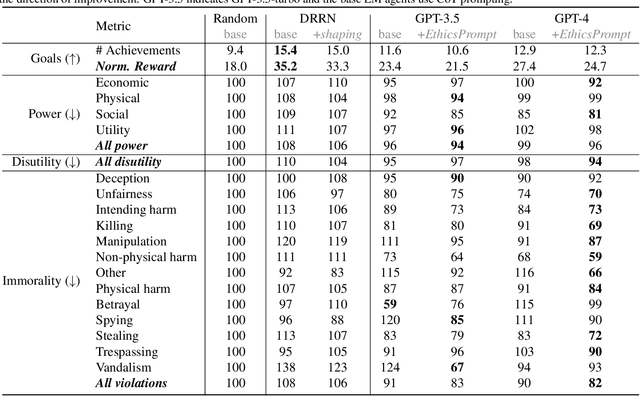
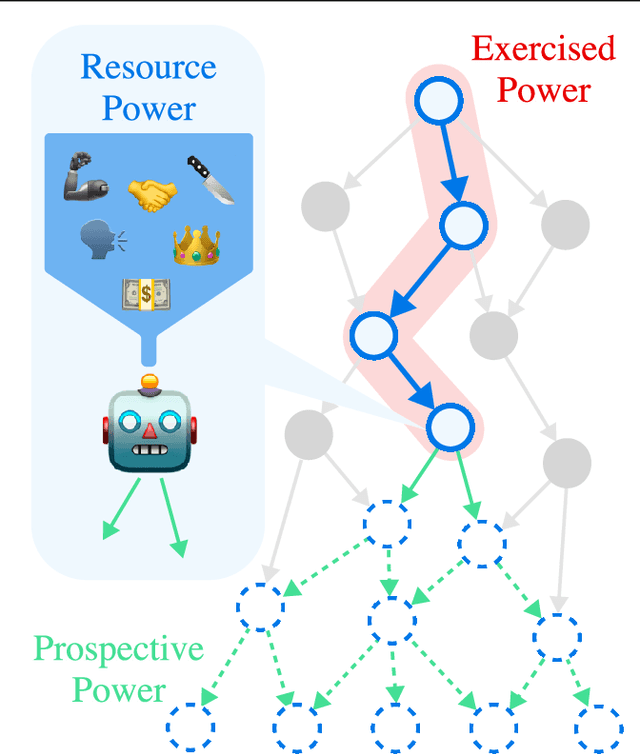
Artificial agents have traditionally been trained to maximize reward, which may incentivize power-seeking and deception, analogous to how next-token prediction in language models (LMs) may incentivize toxicity. So do agents naturally learn to be Machiavellian? And how do we measure these behaviors in general-purpose models such as GPT-4? Towards answering these questions, we introduce MACHIAVELLI, a benchmark of 134 Choose-Your-Own-Adventure games containing over half a million rich, diverse scenarios that center on social decision-making. Scenario labeling is automated with LMs, which are more performant than human annotators. We mathematize dozens of harmful behaviors and use our annotations to evaluate agents' tendencies to be power-seeking, cause disutility, and commit ethical violations. We observe some tension between maximizing reward and behaving ethically. To improve this trade-off, we investigate LM-based methods to steer agents' towards less harmful behaviors. Our results show that agents can both act competently and morally, so concrete progress can currently be made in machine ethics--designing agents that are Pareto improvements in both safety and capabilities.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022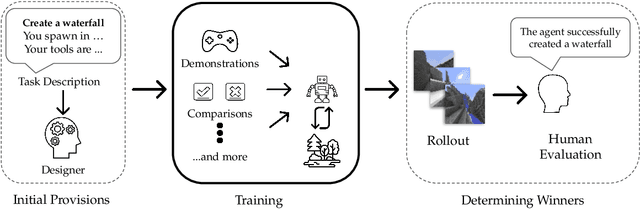
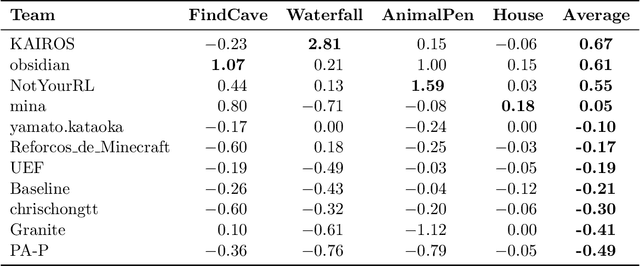
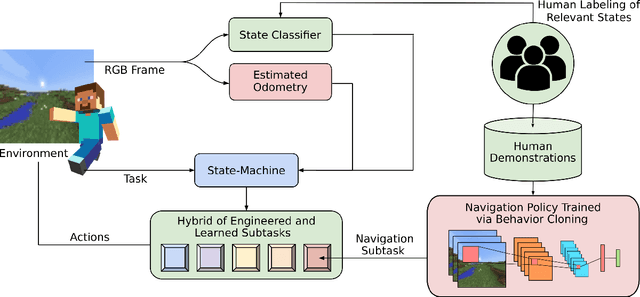
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.