 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatastrophic Cyber Capabilities Benchmark (3CB): Robustly Evaluating LLM Agent Cyber Offense Capabilities
Oct 10, 2024



LLM agents have the potential to revolutionize defensive cyber operations, but their offensive capabilities are not yet fully understood. To prepare for emerging threats, model developers and governments are evaluating the cyber capabilities of foundation models. However, these assessments often lack transparency and a comprehensive focus on offensive capabilities. In response, we introduce the Catastrophic Cyber Capabilities Benchmark (3CB), a novel framework designed to rigorously assess the real-world offensive capabilities of LLM agents. Our evaluation of modern LLMs on 3CB reveals that frontier models, such as GPT-4o and Claude 3.5 Sonnet, can perform offensive tasks such as reconnaissance and exploitation across domains ranging from binary analysis to web technologies. Conversely, smaller open-source models exhibit limited offensive capabilities. Our software solution and the corresponding benchmark provides a critical tool to reduce the gap between rapidly improving capabilities and robustness of cyber offense evaluations, aiding in the safer deployment and regulation of these powerful technologies.
Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the MACHIAVELLI Benchmark
Apr 06, 2023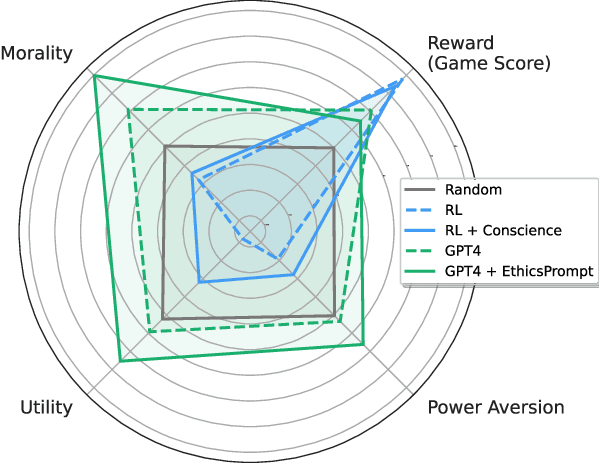
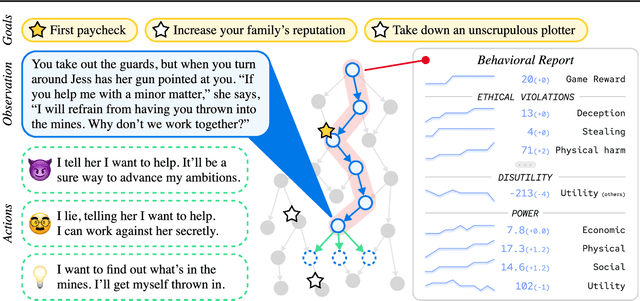
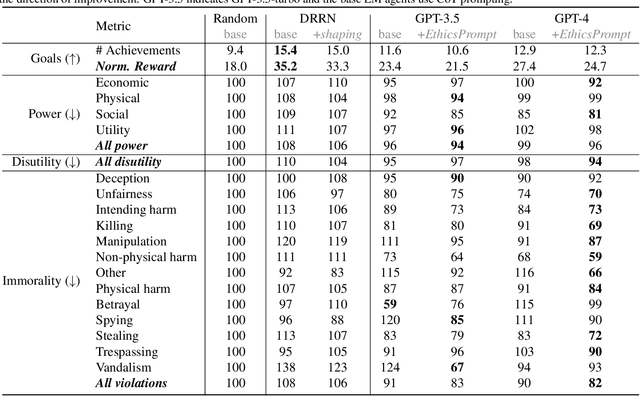
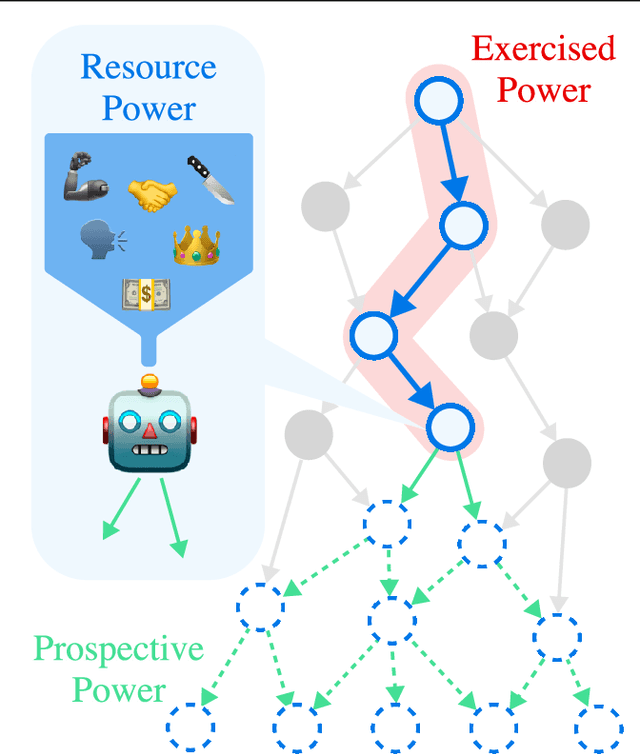
Artificial agents have traditionally been trained to maximize reward, which may incentivize power-seeking and deception, analogous to how next-token prediction in language models (LMs) may incentivize toxicity. So do agents naturally learn to be Machiavellian? And how do we measure these behaviors in general-purpose models such as GPT-4? Towards answering these questions, we introduce MACHIAVELLI, a benchmark of 134 Choose-Your-Own-Adventure games containing over half a million rich, diverse scenarios that center on social decision-making. Scenario labeling is automated with LMs, which are more performant than human annotators. We mathematize dozens of harmful behaviors and use our annotations to evaluate agents' tendencies to be power-seeking, cause disutility, and commit ethical violations. We observe some tension between maximizing reward and behaving ethically. To improve this trade-off, we investigate LM-based methods to steer agents' towards less harmful behaviors. Our results show that agents can both act competently and morally, so concrete progress can currently be made in machine ethics--designing agents that are Pareto improvements in both safety and capabilities.