 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Datasets in Words: Statistical Models with Natural Language Parameters
Paper and Code
Sep 13, 2024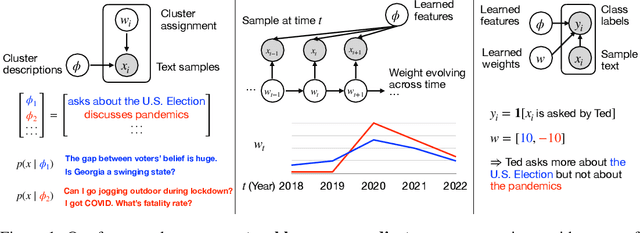


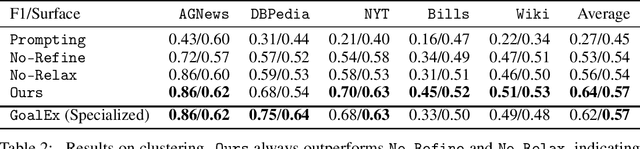
To make sense of massive data, we often fit simplified models and then interpret the parameters; for example, we cluster the text embeddings and then interpret the mean parameters of each cluster. However, these parameters are often high-dimensional and hard to interpret. To make model parameters directly interpretable, we introduce a family of statistical models -- including clustering, time series, and classification models -- parameterized by natural language predicates. For example, a cluster of text about COVID could be parameterized by the predicate "discusses COVID". To learn these statistical models effectively, we develop a model-agnostic algorithm that optimizes continuous relaxations of predicate parameters with gradient descent and discretizes them by prompting language models (LMs). Finally, we apply our framework to a wide range of problems: taxonomizing user chat dialogues, characterizing how they evolve across time, finding categories where one language model is better than the other, clustering math problems based on subareas, and explaining visual features in memorable images. Our framework is highly versatile, applicable to both textual and visual domains, can be easily steered to focus on specific properties (e.g. subareas), and explains sophisticated concepts that classical methods (e.g. n-gram analysis) struggle to produce.