 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Generative Meta-Model of LLM Activations
Feb 06, 2026Existing approaches for analyzing neural network activations, such as PCA and sparse autoencoders, rely on strong structural assumptions. Generative models offer an alternative: they can uncover structure without such assumptions and act as priors that improve intervention fidelity. We explore this direction by training diffusion models on one billion residual stream activations, creating "meta-models" that learn the distribution of a network's internal states. We find that diffusion loss decreases smoothly with compute and reliably predicts downstream utility. In particular, applying the meta-model's learned prior to steering interventions improves fluency, with larger gains as loss decreases. Moreover, the meta-model's neurons increasingly isolate concepts into individual units, with sparse probing scores that scale as loss decreases. These results suggest generative meta-models offer a scalable path toward interpretability without restrictive structural assumptions. Project page: https://generative-latent-prior.github.io.
Extractive Structures Learned in Pretraining Enable Generalization on Finetuned Facts
Dec 05, 2024Pretrained language models (LMs) can generalize to implications of facts that they are finetuned on. For example, if finetuned on ``John Doe lives in Tokyo," LMs can correctly answer ``What language do the people in John Doe's city speak?'' with ``Japanese''. However, little is known about the mechanisms that enable this generalization or how they are learned during pretraining. We introduce extractive structures as a framework for describing how components in LMs (e.g., MLPs or attention heads) coordinate to enable this generalization. The structures consist of informative components that store training facts as weight changes, and upstream and downstream extractive components that query and process the stored information to produce the correct implication. We hypothesize that extractive structures are learned during pretraining when encountering implications of previously known facts. This yields two predictions: a data ordering effect where extractive structures can be learned only if facts precede their implications, and a weight grafting effect where extractive structures can be transferred to predict counterfactual implications. We empirically demonstrate these phenomena in the OLMo-7b, Llama 3-8b, Gemma 2-9b, and Qwen 2-7b models. Of independent interest, our results also indicate that fact learning can occur at both early and late layers, which lead to different forms of generalization.
Monitoring Latent World States in Language Models with Propositional Probes
Jun 27, 2024Language models are susceptible to bias, sycophancy, backdoors, and other tendencies that lead to unfaithful responses to the input context. Interpreting internal states of language models could help monitor and correct unfaithful behavior. We hypothesize that language models represent their input contexts in a latent world model, and seek to extract this latent world state from the activations. We do so with 'propositional probes', which compositionally probe tokens for lexical information and bind them into logical propositions representing the world state. For example, given the input context ''Greg is a nurse. Laura is a physicist.'', we decode the propositions ''WorksAs(Greg, nurse)'' and ''WorksAs(Laura, physicist)'' from the model's activations. Key to this is identifying a 'binding subspace' in which bound tokens have high similarity (''Greg'' and ''nurse'') but unbound ones do not (''Greg'' and ''physicist''). We validate propositional probes in a closed-world setting with finitely many predicates and properties. Despite being trained on simple templated contexts, propositional probes generalize to contexts rewritten as short stories and translated to Spanish. Moreover, we find that in three settings where language models respond unfaithfully to the input context -- prompt injections, backdoor attacks, and gender bias -- the decoded propositions remain faithful. This suggests that language models often encode a faithful world model but decode it unfaithfully, which motivates the search for better interpretability tools for monitoring LMs.
Learning adaptive planning representations with natural language guidance
Dec 13, 2023



Effective planning in the real world requires not only world knowledge, but the ability to leverage that knowledge to build the right representation of the task at hand. Decades of hierarchical planning techniques have used domain-specific temporal action abstractions to support efficient and accurate planning, almost always relying on human priors and domain knowledge to decompose hard tasks into smaller subproblems appropriate for a goal or set of goals. This paper describes Ada (Action Domain Acquisition), a framework for automatically constructing task-specific planning representations using task-general background knowledge from language models (LMs). Starting with a general-purpose hierarchical planner and a low-level goal-conditioned policy, Ada interactively learns a library of planner-compatible high-level action abstractions and low-level controllers adapted to a particular domain of planning tasks. On two language-guided interactive planning benchmarks (Mini Minecraft and ALFRED Household Tasks), Ada strongly outperforms other approaches that use LMs for sequential decision-making, offering more accurate plans and better generalization to complex tasks.
How do Language Models Bind Entities in Context?
Oct 26, 2023To correctly use in-context information, language models (LMs) must bind entities to their attributes. For example, given a context describing a "green square" and a "blue circle", LMs must bind the shapes to their respective colors. We analyze LM representations and identify the binding ID mechanism: a general mechanism for solving the binding problem, which we observe in every sufficiently large model from the Pythia and LLaMA families. Using causal interventions, we show that LMs' internal activations represent binding information by attaching binding ID vectors to corresponding entities and attributes. We further show that binding ID vectors form a continuous subspace, in which distances between binding ID vectors reflect their discernability. Overall, our results uncover interpretable strategies in LMs for representing symbolic knowledge in-context, providing a step towards understanding general in-context reasoning in large-scale LMs.
Structured, flexible, and robust: benchmarking and improving large language models towards more human-like behavior in out-of-distribution reasoning tasks
May 11, 2022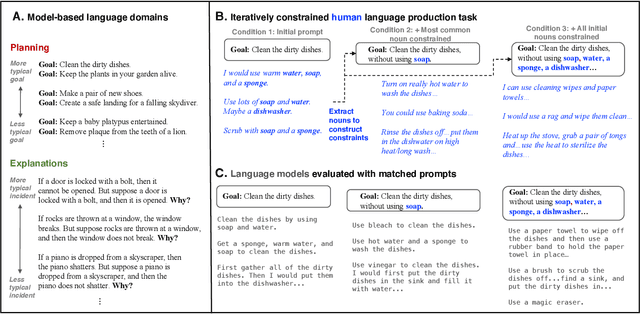

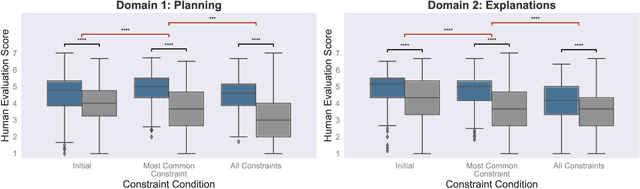
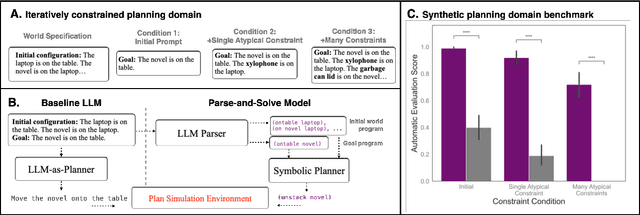
Human language offers a powerful window into our thoughts -- we tell stories, give explanations, and express our beliefs and goals through words. Abundant evidence also suggests that language plays a developmental role in structuring our learning. Here, we ask: how much of human-like thinking can be captured by learning statistical patterns in language alone? We first contribute a new challenge benchmark for comparing humans and distributional large language models (LLMs). Our benchmark contains two problem-solving domains (planning and explanation generation) and is designed to require generalization to new, out-of-distribution problems expressed in language. We find that humans are far more robust than LLMs on this benchmark. Next, we propose a hybrid Parse-and-Solve model, which augments distributional LLMs with a structured symbolic reasoning module. We find that this model shows more robust adaptation to out-of-distribution planning problems, demonstrating the promise of hybrid AI models for more human-like reasoning.
AI Feynman 2.0: Pareto-optimal symbolic regression exploiting graph modularity
Jun 18, 2020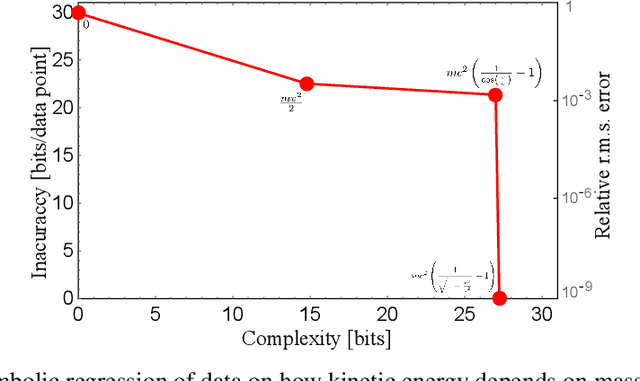

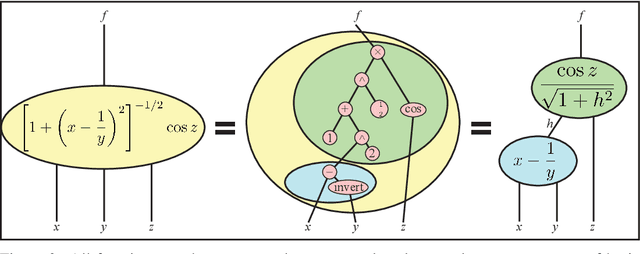

We present an improved method for symbolic regression that seeks to fit data to formulas that are Pareto-optimal, in the sense of having the best accuracy for a given complexity. It improves on the previous state-of-the-art by typically being orders of magnitude more robust toward noise and bad data, and also by discovering many formulas that stumped previous methods. We develop a method for discovering generalized symmetries (arbitrary modularity in the computational graph of a formula) from gradient properties of a neural network fit. We use normalizing flows to generalize our symbolic regression method to probability distributions from which we only have samples, and employ statistical hypothesis testing to accelerate robust brute-force search.