 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Best Arm Identification with Tests for Feasibility
Nov 12, 2025Best arm identification (BAI) aims to identify the highest-performance arm among a set of $K$ arms by collecting stochastic samples from each arm. In real-world problems, the best arm needs to satisfy additional feasibility constraints. While there is limited prior work on BAI with feasibility constraints, they typically assume the performance and constraints are observed simultaneously on each pull of an arm. However, this assumption does not reflect most practical use cases, e.g., in drug discovery, we wish to find the most potent drug whose toxicity and solubility are below certain safety thresholds. These safety experiments can be conducted separately from the potency measurement. Thus, this requires designing BAI algorithms that not only decide which arm to pull but also decide whether to test for the arm's performance or feasibility. In this work, we study feasible BAI which allows a decision-maker to choose a tuple $(i,\ell)$, where $i\in [K]$ denotes an arm and $\ell$ denotes whether she wishes to test for its performance ($\ell=0$) or any of its $N$ feasibility constraints ($\ell\in[N]$). We focus on the fixed confidence setting, which is to identify the \textit{feasible} arm with the \textit{highest performance}, with a probability of at least $1-δ$. We propose an efficient algorithm and upper-bound its sample complexity, showing our algorithm can naturally adapt to the problem's difficulty and eliminate arms by worse performance or infeasibility, whichever is easier. We complement this upper bound with a lower bound showing that our algorithm is \textit{asymptotically ($δ\rightarrow 0$) optimal}. Finally, we empirically show that our algorithm outperforms other state-of-the-art BAI algorithms in both synthetic and real-world datasets.
A Cramér-von Mises Approach to Incentivizing Truthful Data Sharing
Jun 08, 2025
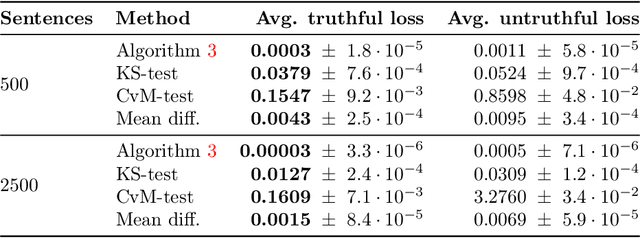

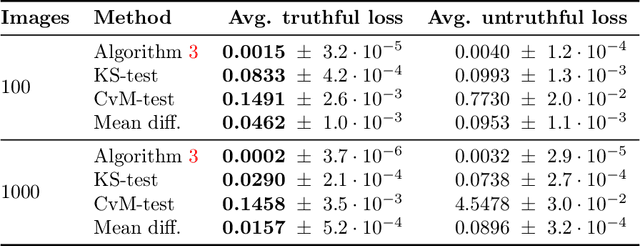
Modern data marketplaces and data sharing consortia increasingly rely on incentive mechanisms to encourage agents to contribute data. However, schemes that reward agents based on the quantity of submitted data are vulnerable to manipulation, as agents may submit fabricated or low-quality data to inflate their rewards. Prior work has proposed comparing each agent's data against others' to promote honesty: when others contribute genuine data, the best way to minimize discrepancy is to do the same. Yet prior implementations of this idea rely on very strong assumptions about the data distribution (e.g. Gaussian), limiting their applicability. In this work, we develop reward mechanisms based on a novel, two-sample test inspired by the Cram\'er-von Mises statistic. Our methods strictly incentivize agents to submit more genuine data, while disincentivizing data fabrication and other types of untruthful reporting. We establish that truthful reporting constitutes a (possibly approximate) Nash equilibrium in both Bayesian and prior-agnostic settings. We theoretically instantiate our method in three canonical data sharing problems and show that it relaxes key assumptions made by prior work. Empirically, we demonstrate that our mechanism incentivizes truthful data sharing via simulations and on real-world language and image data.
Balancing Performance and Costs in Best Arm Identification
May 26, 2025


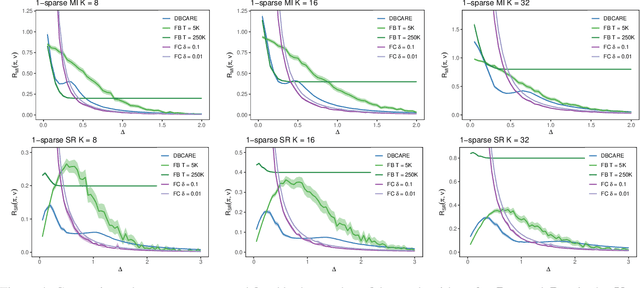
We consider the problem of identifying the best arm in a multi-armed bandit model. Despite a wealth of literature in the traditional fixed budget and fixed confidence regimes of the best arm identification problem, it still remains a mystery to most practitioners as to how to choose an approach and corresponding budget or confidence parameter. We propose a new formalism to avoid this dilemma altogether by minimizing a risk functional which explicitly balances the performance of the recommended arm and the cost incurred by learning this arm. In this framework, a cost is incurred for each observation during the sampling phase, and upon recommending an arm, a performance penalty is incurred for identifying a suboptimal arm. The learner's goal is to minimize the sum of the penalty and cost. This new regime mirrors the priorities of many practitioners, e.g. maximizing profit in an A/B testing framework, better than classical fixed budget or confidence settings. We derive theoretical lower bounds for the risk of each of two choices for the performance penalty, the probability of misidentification and the simple regret, and propose an algorithm called DBCARE to match these lower bounds up to polylog factors on nearly all problem instances. We then demonstrate the performance of DBCARE on a number of simulated models, comparing to fixed budget and confidence algorithms to show the shortfalls of existing BAI paradigms on this problem.
Data Sharing for Mean Estimation Among Heterogeneous Strategic Agents
Jul 20, 2024
We study a collaborative learning problem where $m$ agents estimate a vector $\mu\in\mathbb{R}^d$ by collecting samples from normal distributions, with each agent $i$ incurring a cost $c_{i,k} \in (0, \infty]$ to sample from the $k^{\text{th}}$ distribution $\mathcal{N}(\mu_k, \sigma^2)$. Instead of working on their own, agents can collect data that is cheap to them, and share it with others in exchange for data that is expensive or even inaccessible to them, thereby simultaneously reducing data collection costs and estimation error. However, when agents have different collection costs, we need to first decide how to fairly divide the work of data collection so as to benefit all agents. Moreover, in naive sharing protocols, strategic agents may under-collect and/or fabricate data, leading to socially undesirable outcomes. Our mechanism addresses these challenges by combining ideas from cooperative and non-cooperative game theory. We use ideas from axiomatic bargaining to divide the cost of data collection. Given such a solution, we develop a Nash incentive-compatible (NIC) mechanism to enforce truthful reporting. We achieve a $\mathcal{O}(\sqrt{m})$ approximation to the minimum social penalty (sum of agent estimation errors and data collection costs) in the worst case, and a $\mathcal{O}(1)$ approximation under favorable conditions. We complement this with a hardness result, showing that $\Omega(\sqrt{m})$ is unavoidable in any NIC mechanism.
Learning to Price Homogeneous Data
Jul 07, 2024


We study a data pricing problem, where a seller has access to $N$ homogeneous data points (e.g. drawn i.i.d. from some distribution). There are $m$ types of buyers in the market, where buyers of the same type $i$ have the same valuation curve $v_i:[N]\rightarrow [0,1]$, where $v_i(n)$ is the value for having $n$ data points. \textit{A priori}, the seller is unaware of the distribution of buyers, but can repeat the market for $T$ rounds so as to learn the revenue-optimal pricing curve $p:[N] \rightarrow [0, 1]$. To solve this online learning problem, we first develop novel discretization schemes to approximate any pricing curve. When compared to prior work, the size of our discretization schemes scales gracefully with the approximation parameter, which translates to better regret in online learning. Under assumptions like smoothness and diminishing returns which are satisfied by data, the discretization size can be reduced further. We then turn to the online learning problem, both in the stochastic and adversarial settings. On each round, the seller chooses an \emph{anonymous} pricing curve $p_t$. A new buyer appears and may choose to purchase some amount of data. She then reveals her type \emph{only if} she makes a purchase. Our online algorithms build on classical algorithms such as UCB and FTPL, but require novel ideas to account for the asymmetric nature of this feedback and to deal with the vastness of the space of pricing curves. Using the improved discretization schemes previously developed, we are able to achieve $\tilde{O}\left(m\sqrt{T}\right)$ regret in the stochastic setting and $\tilde{O}\left(m^{\frac{3}{2}}\sqrt{T}\right)$ regret in the adversarial setting.
Nash Incentive-compatible Online Mechanism Learning via Weakly Differentially Private Online Learning
Jul 06, 2024We study a multi-round mechanism design problem, where we interact with a set of agents over a sequence of rounds. We wish to design an incentive-compatible (IC) online learning scheme to maximize an application-specific objective within a given class of mechanisms, without prior knowledge of the agents' type distributions. Even if each mechanism in this class is IC in a single round, if an algorithm naively chooses from this class on each round, the entire learning process may not be IC against non-myopic buyers who appear over multiple rounds. On each round, our method randomly chooses between the recommendation of a weakly differentially private online learning algorithm (e.g., Hedge), and a commitment mechanism which penalizes non-truthful behavior. Our method is IC and achieves $O(T^{\frac{1+h}{2}})$ regret for the application-specific objective in an adversarial setting, where $h$ quantifies the long-sightedness of the agents. When compared to prior work, our approach is conceptually simpler,it applies to general mechanism design problems (beyond auctions), and its regret scales gracefully with the size of the mechanism class.
Bandit Profit-maximization for Targeted Marketing
Mar 03, 2024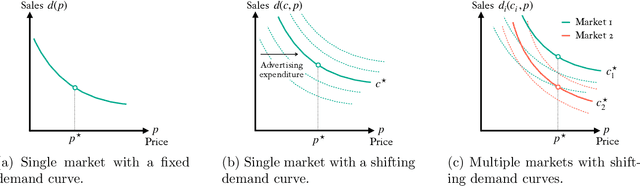


We study a sequential profit-maximization problem, optimizing for both price and ancillary variables like marketing expenditures. Specifically, we aim to maximize profit over an arbitrary sequence of multiple demand curves, each dependent on a distinct ancillary variable, but sharing the same price. A prototypical example is targeted marketing, where a firm (seller) wishes to sell a product over multiple markets. The firm may invest different marketing expenditures for different markets to optimize customer acquisition, but must maintain the same price across all markets. Moreover, markets may have heterogeneous demand curves, each responding to prices and marketing expenditures differently. The firm's objective is to maximize its gross profit, the total revenue minus marketing costs. Our results are near-optimal algorithms for this class of problems in an adversarial bandit setting, where demand curves are arbitrary non-adaptive sequences, and the firm observes only noisy evaluations of chosen points on the demand curves. We prove a regret upper bound of $\widetilde{\mathcal{O}}\big(nT^{3/4}\big)$ and a lower bound of $\Omega\big((nT)^{3/4}\big)$ for monotonic demand curves, and a regret bound of $\widetilde{\Theta}\big(nT^{2/3}\big)$ for demands curves that are monotonic in price and concave in the ancillary variables.
Active Cost-aware Labeling of Streaming Data
Apr 13, 2023



We study actively labeling streaming data, where an active learner is faced with a stream of data points and must carefully choose which of these points to label via an expensive experiment. Such problems frequently arise in applications such as healthcare and astronomy. We first study a setting when the data's inputs belong to one of $K$ discrete distributions and formalize this problem via a loss that captures the labeling cost and the prediction error. When the labeling cost is $B$, our algorithm, which chooses to label a point if the uncertainty is larger than a time and cost dependent threshold, achieves a worst-case upper bound of $O(B^{\frac{1}{3}} K^{\frac{1}{3}} T^{\frac{2}{3}})$ on the loss after $T$ rounds. We also provide a more nuanced upper bound which demonstrates that the algorithm can adapt to the arrival pattern, and achieves better performance when the arrival pattern is more favorable. We complement both upper bounds with matching lower bounds. We next study this problem when the inputs belong to a continuous domain and the output of the experiment is a smooth function with bounded RKHS norm. After $T$ rounds in $d$ dimensions, we show that the loss is bounded by $O(B^{\frac{1}{d+3}} T^{\frac{d+2}{d+3}})$ in an RKHS with a squared exponential kernel and by $O(B^{\frac{1}{2d+3}} T^{\frac{2d+2}{2d+3}})$ in an RKHS with a Mat\'ern kernel. Our empirical evaluation demonstrates that our method outperforms other baselines in several synthetic experiments and two real experiments in medicine and astronomy.
Leveraging Reviews: Learning to Price with Buyer and Seller Uncertainty
Feb 20, 2023
In online marketplaces, customers have access to hundreds of reviews for a single product. Buyers often use reviews from other customers that share their type -- such as height for clothing, skin type for skincare products, and location for outdoor furniture -- to estimate their values, which they may not know a priori. Customers with few relevant reviews may hesitate to make a purchase except at a low price, so for the seller, there is a tension between setting high prices and ensuring that there are enough reviews so that buyers can confidently estimate their values. Simultaneously, sellers may use reviews to gauge the demand for items they wish to sell. In this work, we study this pricing problem in an online setting where the seller interacts with a set of buyers of finitely-many types, one-by-one, over a series of $T$ rounds. At each round, the seller first sets a price. Then a buyer arrives and examines the reviews of the previous buyers with the same type, which reveal those buyers' ex-post values. Based on the reviews, the buyer decides to purchase if they have good reason to believe that their ex-ante utility is positive. Crucially, the seller does not know the buyer's type when setting the price, nor even the distribution over types. We provide a no-regret algorithm that the seller can use to obtain high revenue. When there are $d$ types, after $T$ rounds, our algorithm achieves a problem-independent $\tilde O(T^{2/3}d^{1/3})$ regret bound. However, when the smallest probability $q_{\text{min}}$ that any given type appears is large, specifically when $q_{\text{min}} \in \Omega(d^{-2/3}T^{-1/3})$, then the same algorithm achieves a $\tilde O(T^{1/2}q_{\text{min}}^{-1/2})$ regret bound. We complement these upper bounds with matching lower bounds in both regimes, showing that our algorithm is minimax optimal up to lower order terms.
Online Learning of Competitive Equilibria in Exchange Economies
Jun 11, 2021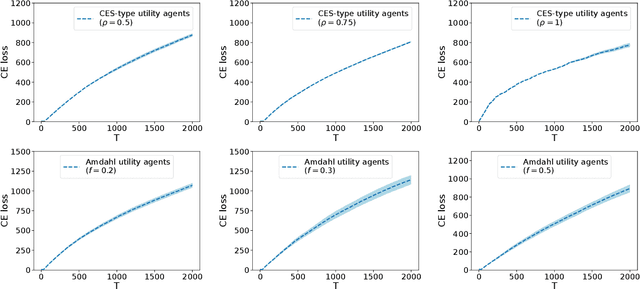
The sharing of scarce resources among multiple rational agents is one of the classical problems in economics. In exchange economies, which are used to model such situations, agents begin with an initial endowment of resources and exchange them in a way that is mutually beneficial until they reach a competitive equilibrium (CE). CE allocations are Pareto efficient and fair. Consequently, they are used widely in designing mechanisms for fair division. However, computing CEs requires the knowledge of agent preferences which are unknown in several applications of interest. In this work, we explore a new online learning mechanism, which, on each round, allocates resources to the agents and collects stochastic feedback on their experience in using that allocation. Its goal is to learn the agent utilities via this feedback and imitate the allocations at a CE in the long run. We quantify CE behavior via two losses and propose a randomized algorithm which achieves $\bigOtilde(\sqrt{T})$ loss after $T$ rounds under both criteria. Empirically, we demonstrate the effectiveness of this mechanism through numerical simulations.