 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adaptive Data Analysis over Dense Distributions
Feb 07, 2026Modern data workflows are inherently adaptive, repeatedly querying the same dataset to refine and validate sequential decisions, but such adaptivity can lead to overfitting and invalid statistical inference. Adaptive Data Analysis (ADA) mechanisms address this challenge; however, there is a fundamental tension between computational efficiency and sample complexity. For $T$ rounds of adaptive analysis, computationally efficient algorithms typically incur suboptimal $O(\sqrt{T})$ sample complexity, whereas statistically optimal $O(\log T)$ algorithms are computationally intractable under standard cryptographic assumptions. In this work, we shed light on this trade-off by identifying a natural class of data distributions under which both computational efficiency and optimal sample complexity are achievable. We propose a computationally efficient ADA mechanism that attains optimal $O(\log T)$ sample complexity when the data distribution is dense with respect to a known prior. This setting includes, in particular, feature--label data distributions arising in distribution-specific learning. As a consequence, our mechanism also yields a sample-efficient (i.e., $O(\log T)$ samples) statistical query oracle in the distribution-specific setting. Moreover, although our algorithm is not based on differential privacy, it satisfies a relaxed privacy notion known as Predicate Singling Out (PSO) security (Cohen and Nissim, 2020). Our results thus reveal an inherent connection between adaptive data analysis and privacy beyond differential privacy.
Learning to Price Homogeneous Data
Jul 07, 2024


We study a data pricing problem, where a seller has access to $N$ homogeneous data points (e.g. drawn i.i.d. from some distribution). There are $m$ types of buyers in the market, where buyers of the same type $i$ have the same valuation curve $v_i:[N]\rightarrow [0,1]$, where $v_i(n)$ is the value for having $n$ data points. \textit{A priori}, the seller is unaware of the distribution of buyers, but can repeat the market for $T$ rounds so as to learn the revenue-optimal pricing curve $p:[N] \rightarrow [0, 1]$. To solve this online learning problem, we first develop novel discretization schemes to approximate any pricing curve. When compared to prior work, the size of our discretization schemes scales gracefully with the approximation parameter, which translates to better regret in online learning. Under assumptions like smoothness and diminishing returns which are satisfied by data, the discretization size can be reduced further. We then turn to the online learning problem, both in the stochastic and adversarial settings. On each round, the seller chooses an \emph{anonymous} pricing curve $p_t$. A new buyer appears and may choose to purchase some amount of data. She then reveals her type \emph{only if} she makes a purchase. Our online algorithms build on classical algorithms such as UCB and FTPL, but require novel ideas to account for the asymmetric nature of this feedback and to deal with the vastness of the space of pricing curves. Using the improved discretization schemes previously developed, we are able to achieve $\tilde{O}\left(m\sqrt{T}\right)$ regret in the stochastic setting and $\tilde{O}\left(m^{\frac{3}{2}}\sqrt{T}\right)$ regret in the adversarial setting.
Nash Incentive-compatible Online Mechanism Learning via Weakly Differentially Private Online Learning
Jul 06, 2024We study a multi-round mechanism design problem, where we interact with a set of agents over a sequence of rounds. We wish to design an incentive-compatible (IC) online learning scheme to maximize an application-specific objective within a given class of mechanisms, without prior knowledge of the agents' type distributions. Even if each mechanism in this class is IC in a single round, if an algorithm naively chooses from this class on each round, the entire learning process may not be IC against non-myopic buyers who appear over multiple rounds. On each round, our method randomly chooses between the recommendation of a weakly differentially private online learning algorithm (e.g., Hedge), and a commitment mechanism which penalizes non-truthful behavior. Our method is IC and achieves $O(T^{\frac{1+h}{2}})$ regret for the application-specific objective in an adversarial setting, where $h$ quantifies the long-sightedness of the agents. When compared to prior work, our approach is conceptually simpler,it applies to general mechanism design problems (beyond auctions), and its regret scales gracefully with the size of the mechanism class.
Bandit Profit-maximization for Targeted Marketing
Mar 03, 2024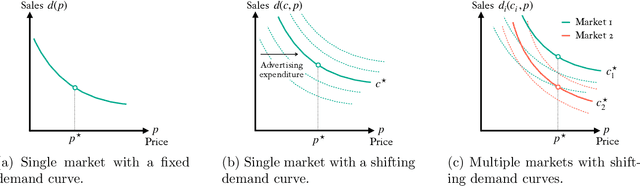


We study a sequential profit-maximization problem, optimizing for both price and ancillary variables like marketing expenditures. Specifically, we aim to maximize profit over an arbitrary sequence of multiple demand curves, each dependent on a distinct ancillary variable, but sharing the same price. A prototypical example is targeted marketing, where a firm (seller) wishes to sell a product over multiple markets. The firm may invest different marketing expenditures for different markets to optimize customer acquisition, but must maintain the same price across all markets. Moreover, markets may have heterogeneous demand curves, each responding to prices and marketing expenditures differently. The firm's objective is to maximize its gross profit, the total revenue minus marketing costs. Our results are near-optimal algorithms for this class of problems in an adversarial bandit setting, where demand curves are arbitrary non-adaptive sequences, and the firm observes only noisy evaluations of chosen points on the demand curves. We prove a regret upper bound of $\widetilde{\mathcal{O}}\big(nT^{3/4}\big)$ and a lower bound of $\Omega\big((nT)^{3/4}\big)$ for monotonic demand curves, and a regret bound of $\widetilde{\Theta}\big(nT^{2/3}\big)$ for demands curves that are monotonic in price and concave in the ancillary variables.
Differentially Private Online Item Pricing
May 19, 2023This work addresses the problem of revenue maximization in a repeated, unlimited supply item-pricing auction while preserving buyer privacy. We present a novel algorithm that provides differential privacy with respect to the buyer's input pair: item selection and bid. Notably, our algorithm is the first to offer a sublinear $O(\sqrt{T}\log{T})$ regret with a privacy guarantee. Our method is based on an exponential weights meta-algorithm, and we mitigate the issue of discontinuities in revenue functions via small random perturbations. As a result of its structural similarity to the exponential mechanism, our method inherently secures differential privacy. We also extend our algorithm to accommodate scenarios where buyers strategically bid over successive rounds. The inherent differential privacy allows us to adapt our algorithm with minimal modification to ensure a sublinear regret in this setting.
On the Power of Deep but Naive Partial Label Learning
Oct 22, 2020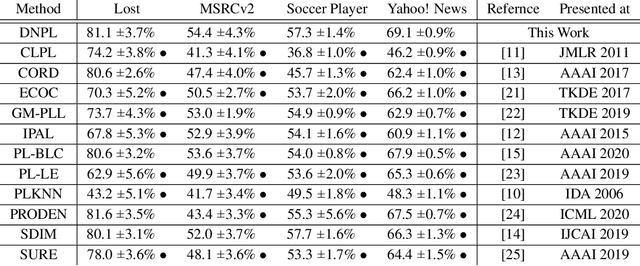

Partial label learning (PLL) is a class of weakly supervised learning where each training instance consists of a data and a set of candidate labels containing a unique ground truth label. To tackle this problem, a majority of current state-of-the-art methods employs either label disambiguation or averaging strategies. So far, PLL methods without such techniques have been considered impractical. In this paper, we challenge this view by revealing the hidden power of the oldest and naivest PLL method when it is instantiated with deep neural networks. Specifically, we show that, with deep neural networks, the naive model can achieve competitive performances against the other state-of-the-art methods, suggesting it as a strong baseline for PLL. We also address the question of how and why such a naive model works well with deep neural networks. Our empirical results indicate that deep neural networks trained on partially labeled examples generalize very well even in the over-parametrized regime and without label disambiguations or regularizations. We point out that existing learning theories on PLL are vacuous in the over-parametrized regime. Hence they cannot explain why the deep naive method works. We propose an alternative theory on how deep learning generalize in PLL problems.