 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Mitigate Externalities: the Coase Theorem with Hindsight Rationality
Jul 03, 2024In economic theory, the concept of externality refers to any indirect effect resulting from an interaction between players that affects the social welfare. Most of the models within which externality has been studied assume that agents have perfect knowledge of their environment and preferences. This is a major hindrance to the practical implementation of many proposed solutions. To address this issue, we consider a two-player bandit setting where the actions of one of the players affect the other player and we extend the Coase theorem [Coase, 1960]. This result shows that the optimal approach for maximizing the social welfare in the presence of externality is to establish property rights, i.e., enable transfers and bargaining between the players. Our work removes the classical assumption that bargainers possess perfect knowledge of the underlying game. We first demonstrate that in the absence of property rights, the social welfare breaks down. We then design a policy for the players which allows them to learn a bargaining strategy which maximizes the total welfare, recovering the Coase theorem under uncertainty.
Automatically Adaptive Conformal Risk Control
Jun 25, 2024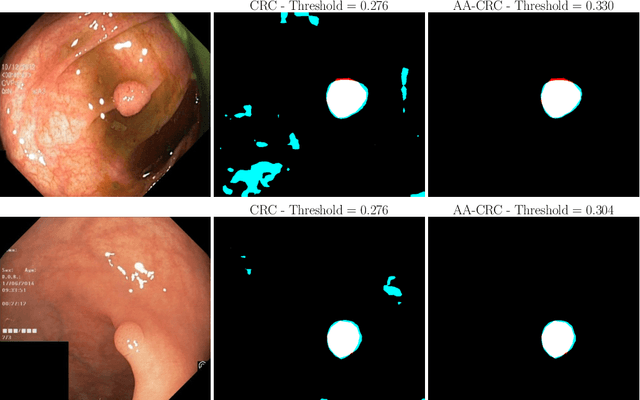

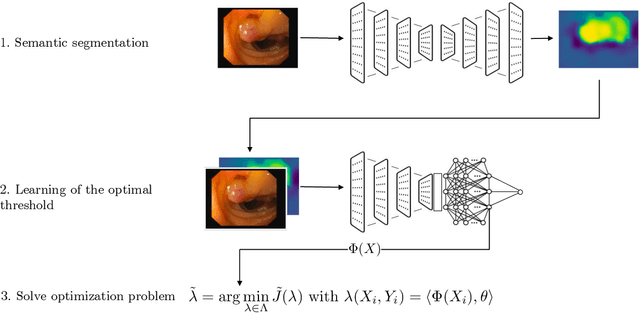
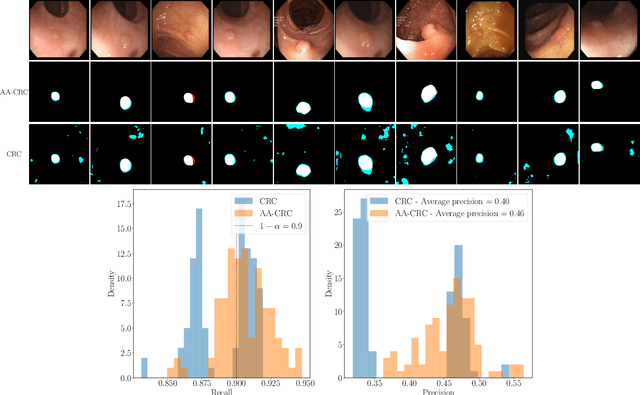
Science and technology have a growing need for effective mechanisms that ensure reliable, controlled performance from black-box machine learning algorithms. These performance guarantees should ideally hold conditionally on the input-that is the performance guarantees should hold, at least approximately, no matter what the input. However, beyond stylized discrete groupings such as ethnicity and gender, the right notion of conditioning can be difficult to define. For example, in problems such as image segmentation, we want the uncertainty to reflect the intrinsic difficulty of the test sample, but this may be difficult to capture via a conditioning event. Building on the recent work of Gibbs et al. [2023], we propose a methodology for achieving approximate conditional control of statistical risks-the expected value of loss functions-by adapting to the difficulty of test samples. Our framework goes beyond traditional conditional risk control based on user-provided conditioning events to the algorithmic, data-driven determination of appropriate function classes for conditioning. We apply this framework to various regression and segmentation tasks, enabling finer-grained control over model performance and demonstrating that by continuously monitoring and adjusting these parameters, we can achieve superior precision compared to conventional risk-control methods.
Image-to-Image Regression with Distribution-Free Uncertainty Quantification and Applications in Imaging
Feb 10, 2022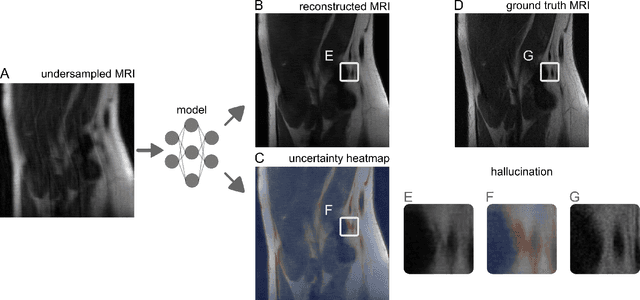
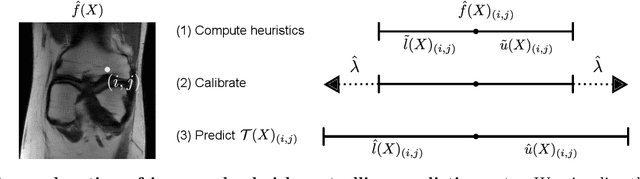
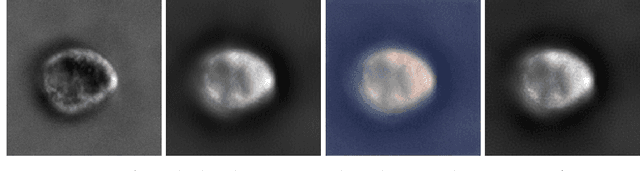
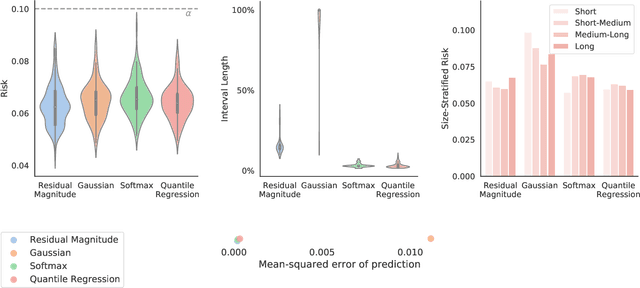
Image-to-image regression is an important learning task, used frequently in biological imaging. Current algorithms, however, do not generally offer statistical guarantees that protect against a model's mistakes and hallucinations. To address this, we develop uncertainty quantification techniques with rigorous statistical guarantees for image-to-image regression problems. In particular, we show how to derive uncertainty intervals around each pixel that are guaranteed to contain the true value with a user-specified confidence probability. Our methods work in conjunction with any base machine learning model, such as a neural network, and endow it with formal mathematical guarantees -- regardless of the true unknown data distribution or choice of model. Furthermore, they are simple to implement and computationally inexpensive. We evaluate our procedure on three image-to-image regression tasks: quantitative phase microscopy, accelerated magnetic resonance imaging, and super-resolution transmission electron microscopy of a Drosophila melanogaster brain.
Online Learning Demands in Max-min Fairness
Dec 15, 2020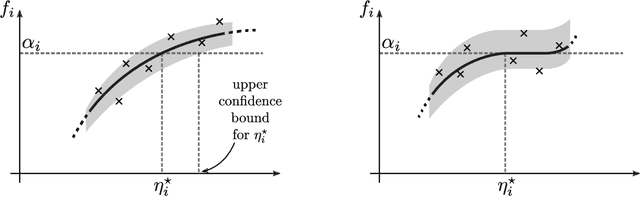

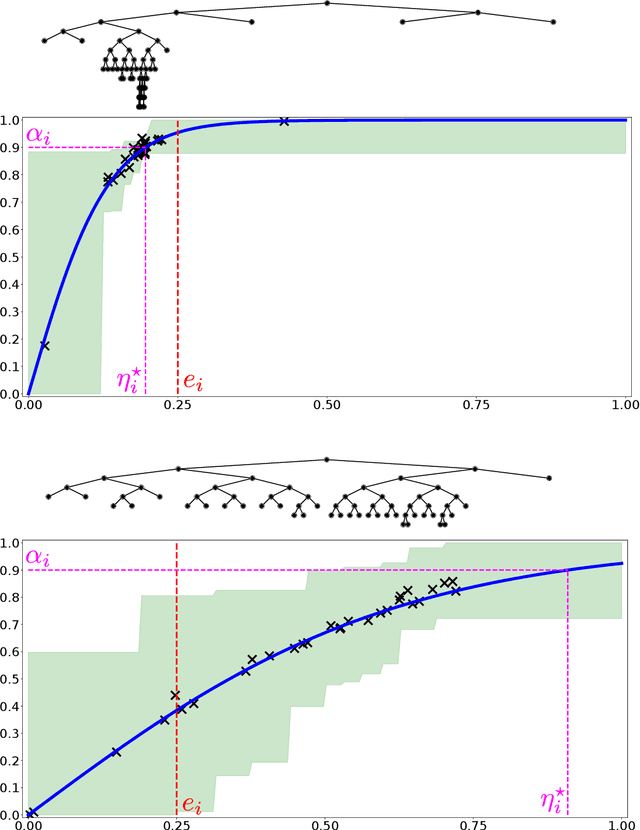
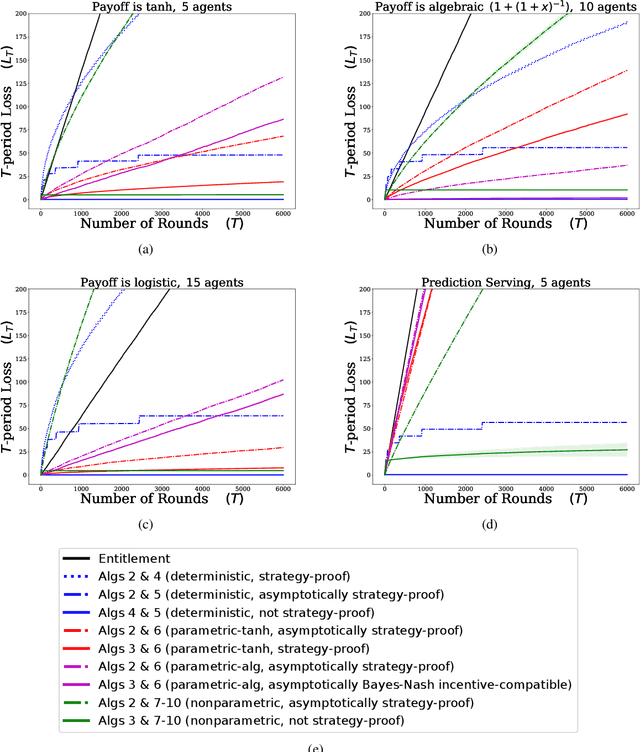
We describe mechanisms for the allocation of a scarce resource among multiple users in a way that is efficient, fair, and strategy-proof, but when users do not know their resource requirements. The mechanism is repeated for multiple rounds and a user's requirements can change on each round. At the end of each round, users provide feedback about the allocation they received, enabling the mechanism to learn user preferences over time. Such situations are common in the shared usage of a compute cluster among many users in an organisation, where all teams may not precisely know the amount of resources needed to execute their jobs. By understating their requirements, users will receive less than they need and consequently not achieve their goals. By overstating them, they may siphon away precious resources that could be useful to others in the organisation. We formalise this task of online learning in fair division via notions of efficiency, fairness, and strategy-proofness applicable to this setting, and study this problem under three types of feedback: when the users' observations are deterministic, when they are stochastic and follow a parametric model, and when they are stochastic and nonparametric. We derive mechanisms inspired by the classical max-min fairness procedure that achieve these requisites, and quantify the extent to which they are achieved via asymptotic rates. We corroborate these insights with an experimental evaluation on synthetic problems and a web-serving task.