 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Generalization in Deep Reinforcement Learning
Oct 29, 2018


Deep reinforcement learning (RL) has achieved breakthrough results on many tasks, but has been shown to be sensitive to system changes at test time. As a result, building deep RL agents that generalize has become an active research area. Our aim is to catalyze and streamline community-wide progress on this problem by providing the first benchmark and a common experimental protocol for investigating generalization in RL. Our benchmark contains a diverse set of environments and our evaluation methodology covers both in-distribution and out-of-distribution generalization. To provide a set of baselines for future research, we conduct a systematic evaluation of deep RL algorithms, including those that specifically tackle the problem of generalization.
The Secret Sharer: Measuring Unintended Neural Network Memorization & Extracting Secrets
Feb 22, 2018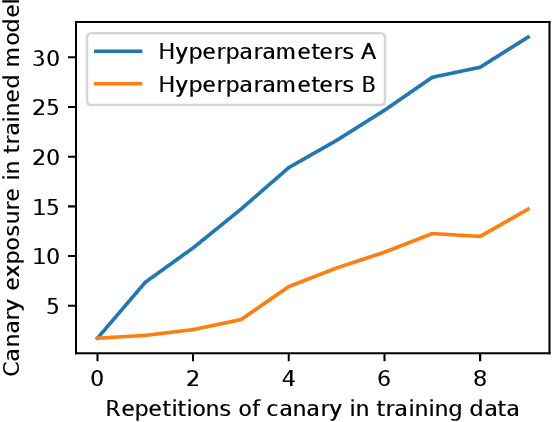

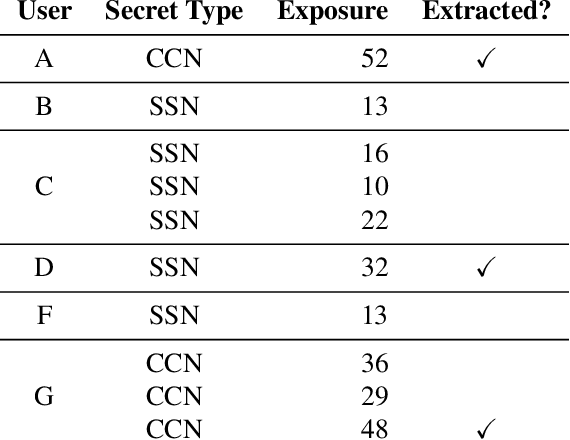
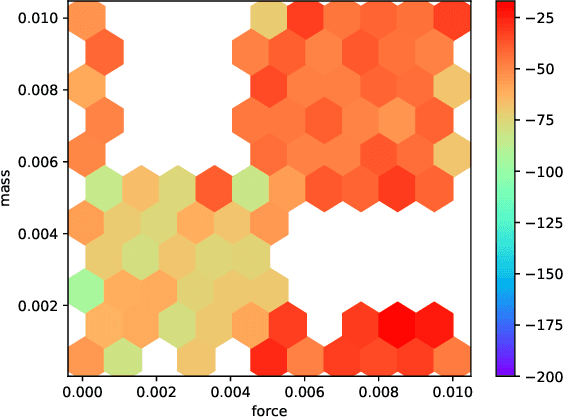
Machine learning models based on neural networks and deep learning are being rapidly adopted for many purposes. What those models learn, and what they may share, is a significant concern when the training data may contain secrets and the models are public -- e.g., when a model helps users compose text messages using models trained on all users' messages. This paper presents exposure: a simple-to-compute metric that can be applied to any deep learning model for measuring the memorization of secrets. Using this metric, we show how to extract those secrets efficiently using black-box API access. Further, we show that unintended memorization occurs early, is not due to over-fitting, and is a persistent issue across different types of models, hyperparameters, and training strategies. We experiment with both real-world models (e.g., a state-of-the-art translation model) and datasets (e.g., the Enron email dataset, which contains users' credit card numbers) to demonstrate both the utility of measuring exposure and the ability to extract secrets. Finally, we consider many defenses, finding some ineffective (like regularization), and others to lack guarantees. However, by instantiating our own differentially-private recurrent model, we validate that by appropriately investing in the use of state-of-the-art techniques, the problem can be resolved, with high utility.
Delving into adversarial attacks on deep policies
May 18, 2017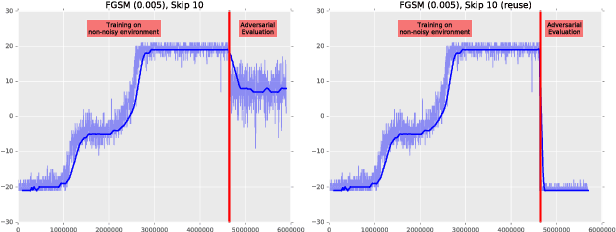
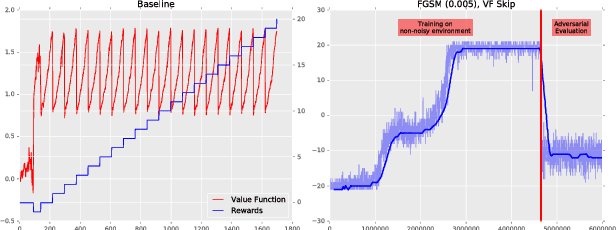
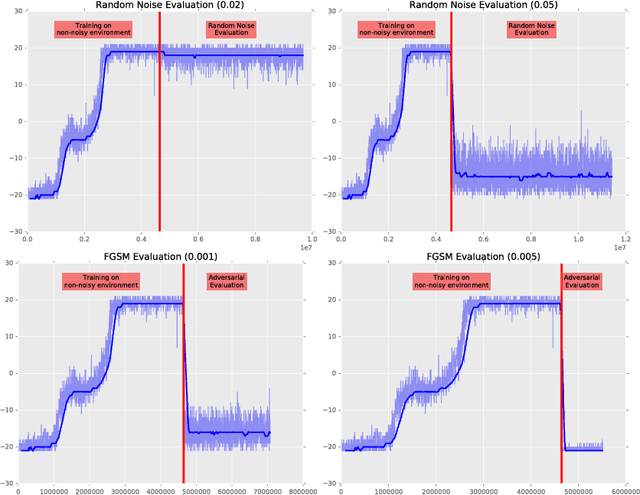
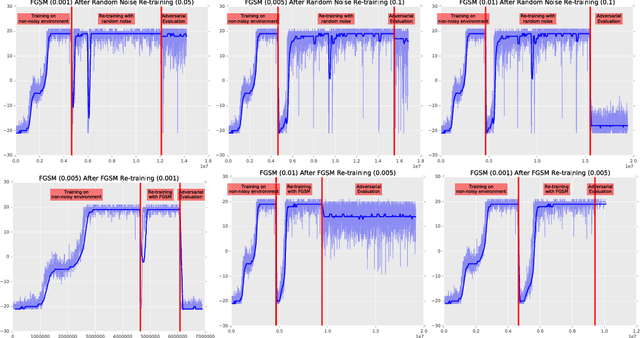
Adversarial examples have been shown to exist for a variety of deep learning architectures. Deep reinforcement learning has shown promising results on training agent policies directly on raw inputs such as image pixels. In this paper we present a novel study into adversarial attacks on deep reinforcement learning polices. We compare the effectiveness of the attacks using adversarial examples vs. random noise. We present a novel method for reducing the number of times adversarial examples need to be injected for a successful attack, based on the value function. We further explore how re-training on random noise and FGSM perturbations affects the resilience against adversarial examples.
Adversarial examples for generative models
Feb 22, 2017


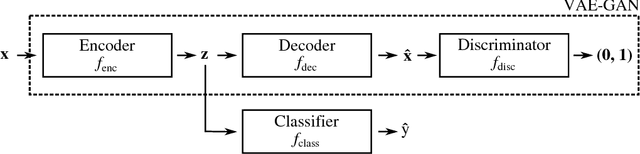
We explore methods of producing adversarial examples on deep generative models such as the variational autoencoder (VAE) and the VAE-GAN. Deep learning architectures are known to be vulnerable to adversarial examples, but previous work has focused on the application of adversarial examples to classification tasks. Deep generative models have recently become popular due to their ability to model input data distributions and generate realistic examples from those distributions. We present three classes of attacks on the VAE and VAE-GAN architectures and demonstrate them against networks trained on MNIST, SVHN and CelebA. Our first attack leverages classification-based adversaries by attaching a classifier to the trained encoder of the target generative model, which can then be used to indirectly manipulate the latent representation. Our second attack directly uses the VAE loss function to generate a target reconstruction image from the adversarial example. Our third attack moves beyond relying on classification or the standard loss for the gradient and directly optimizes against differences in source and target latent representations. We also motivate why an attacker might be interested in deploying such techniques against a target generative network.