 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempered Sigmoid Activations for Deep Learning with Differential Privacy
Jul 28, 2020



Because learning sometimes involves sensitive data, machine learning algorithms have been extended to offer privacy for training data. In practice, this has been mostly an afterthought, with privacy-preserving models obtained by re-running training with a different optimizer, but using the model architectures that already performed well in a non-privacy-preserving setting. This approach leads to less than ideal privacy/utility tradeoffs, as we show here. Instead, we propose that model architectures are chosen ab initio explicitly for privacy-preserving training. To provide guarantees under the gold standard of differential privacy, one must bound as strictly as possible how individual training points can possibly affect model updates. In this paper, we are the first to observe that the choice of activation function is central to bounding the sensitivity of privacy-preserving deep learning. We demonstrate analytically and experimentally how a general family of bounded activation functions, the tempered sigmoids, consistently outperform unbounded activation functions like ReLU. Using this paradigm, we achieve new state-of-the-art accuracy on MNIST, FashionMNIST, and CIFAR10 without any modification of the learning procedure fundamentals or differential privacy analysis.
Distribution Density, Tails, and Outliers in Machine Learning: Metrics and Applications
Oct 29, 2019



We develop techniques to quantify the degree to which a given (training or testing) example is an outlier in the underlying distribution. We evaluate five methods to score examples in a dataset by how well-represented the examples are, for different plausible definitions of "well-represented", and apply these to four common datasets: MNIST, Fashion-MNIST, CIFAR-10, and ImageNet. Despite being independent approaches, we find all five are highly correlated, suggesting that the notion of being well-represented can be quantified. Among other uses, we find these methods can be combined to identify (a) prototypical examples (that match human expectations); (b) memorized training examples; and, (c) uncommon submodes of the dataset. Further, we show how we can utilize our metrics to determine an improved ordering for curriculum learning, and impact adversarial robustness. We release all metric values on training and test sets we studied.
That which we call private
Aug 08, 2019A casual reader of the study by Jayaraman and Evans in USENIX Security 2019 might conclude that "relaxed definitions of differential privacy" should be avoided, because they "increase the measured privacy leakage." This note clarifies that their study is consistent with a different interpretation. Namely, that the "relaxed definitions" are strict improvements which can improve the epsilon upper-bound guarantees by orders-of-magnitude without changing the actual privacy loss. Practitioners should be careful not to equate real-world privacy with epsilon values, without consideration of their context.
Amplification by Shuffling: From Local to Central Differential Privacy via Anonymity
Nov 29, 2018Sensitive statistics are often collected across sets of users, with repeated collection of reports done over time. For example, trends in users' private preferences or software usage may be monitored via such reports. We study the collection of such statistics in the local differential privacy (LDP) model, and describe an algorithm whose privacy cost is polylogarithmic in the number of changes to a user's value. More fundamentally---by building on anonymity of the users' reports---we also demonstrate how the privacy cost of our LDP algorithm can actually be much lower when viewed in the central model of differential privacy. We show, via a new and general privacy amplification technique, that any permutation-invariant algorithm satisfying $\varepsilon$-local differential privacy will satisfy $(O(\varepsilon \sqrt{\log(1/\delta)/n}), \delta)$-central differential privacy. By this, we explain how the high noise and $\sqrt{n}$ overhead of LDP protocols is a consequence of them being significantly more private in the central model. As a practical corollary, our results imply that several LDP-based industrial deployments may have much lower privacy cost than their advertised $\varepsilon$ would indicate---at least if reports are anonymized.
Scalable Private Learning with PATE
Feb 24, 2018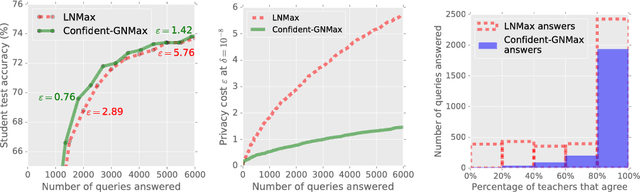
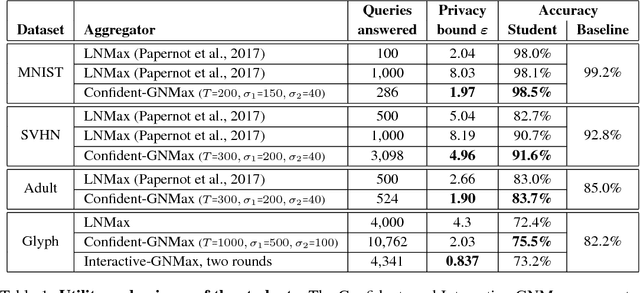
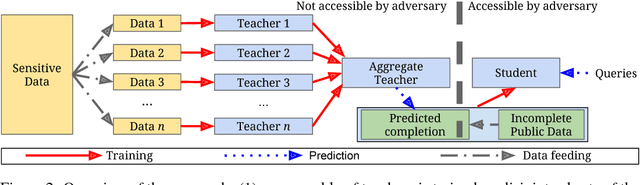
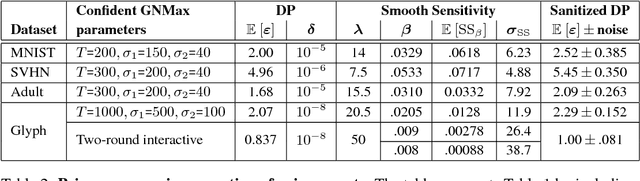
The rapid adoption of machine learning has increased concerns about the privacy implications of machine learning models trained on sensitive data, such as medical records or other personal information. To address those concerns, one promising approach is Private Aggregation of Teacher Ensembles, or PATE, which transfers to a "student" model the knowledge of an ensemble of "teacher" models, with intuitive privacy provided by training teachers on disjoint data and strong privacy guaranteed by noisy aggregation of teachers' answers. However, PATE has so far been evaluated only on simple classification tasks like MNIST, leaving unclear its utility when applied to larger-scale learning tasks and real-world datasets. In this work, we show how PATE can scale to learning tasks with large numbers of output classes and uncurated, imbalanced training data with errors. For this, we introduce new noisy aggregation mechanisms for teacher ensembles that are more selective and add less noise, and prove their tighter differential-privacy guarantees. Our new mechanisms build on two insights: the chance of teacher consensus is increased by using more concentrated noise and, lacking consensus, no answer need be given to a student. The consensus answers used are more likely to be correct, offer better intuitive privacy, and incur lower-differential privacy cost. Our evaluation shows our mechanisms improve on the original PATE on all measures, and scale to larger tasks with both high utility and very strong privacy ($\varepsilon$ < 1.0).
The Secret Sharer: Measuring Unintended Neural Network Memorization & Extracting Secrets
Feb 22, 2018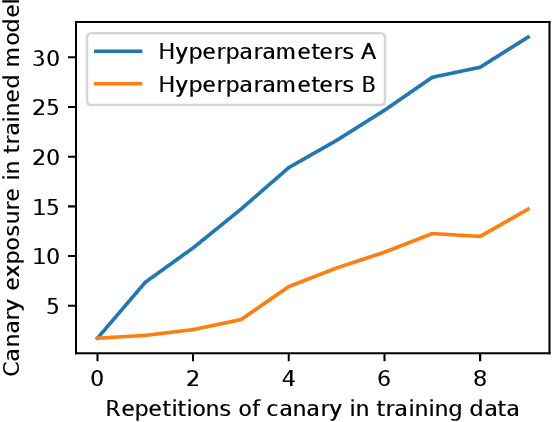

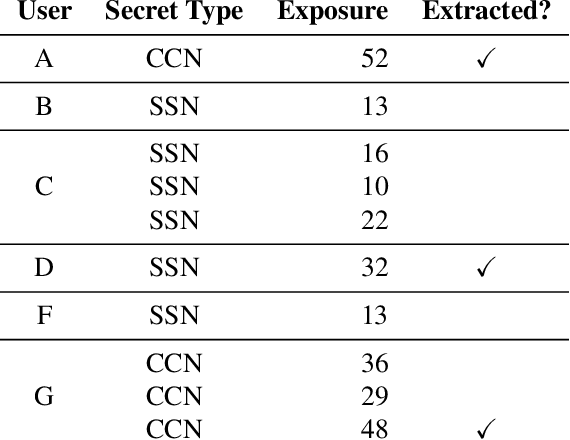
Machine learning models based on neural networks and deep learning are being rapidly adopted for many purposes. What those models learn, and what they may share, is a significant concern when the training data may contain secrets and the models are public -- e.g., when a model helps users compose text messages using models trained on all users' messages. This paper presents exposure: a simple-to-compute metric that can be applied to any deep learning model for measuring the memorization of secrets. Using this metric, we show how to extract those secrets efficiently using black-box API access. Further, we show that unintended memorization occurs early, is not due to over-fitting, and is a persistent issue across different types of models, hyperparameters, and training strategies. We experiment with both real-world models (e.g., a state-of-the-art translation model) and datasets (e.g., the Enron email dataset, which contains users' credit card numbers) to demonstrate both the utility of measuring exposure and the ability to extract secrets. Finally, we consider many defenses, finding some ineffective (like regularization), and others to lack guarantees. However, by instantiating our own differentially-private recurrent model, we validate that by appropriately investing in the use of state-of-the-art techniques, the problem can be resolved, with high utility.
On the Protection of Private Information in Machine Learning Systems: Two Recent Approaches
Aug 26, 2017The recent, remarkable growth of machine learning has led to intense interest in the privacy of the data on which machine learning relies, and to new techniques for preserving privacy. However, older ideas about privacy may well remain valid and useful. This note reviews two recent works on privacy in the light of the wisdom of some of the early literature, in particular the principles distilled by Saltzer and Schroeder in the 1970s.
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
Mar 03, 2017

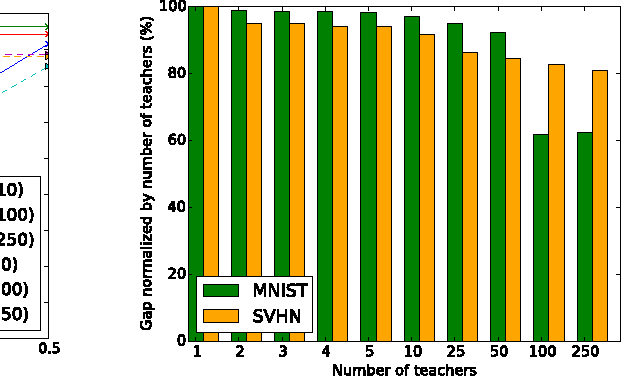

Some machine learning applications involve training data that is sensitive, such as the medical histories of patients in a clinical trial. A model may inadvertently and implicitly store some of its training data; careful analysis of the model may therefore reveal sensitive information. To address this problem, we demonstrate a generally applicable approach to providing strong privacy guarantees for training data: Private Aggregation of Teacher Ensembles (PATE). The approach combines, in a black-box fashion, multiple models trained with disjoint datasets, such as records from different subsets of users. Because they rely directly on sensitive data, these models are not published, but instead used as "teachers" for a "student" model. The student learns to predict an output chosen by noisy voting among all of the teachers, and cannot directly access an individual teacher or the underlying data or parameters. The student's privacy properties can be understood both intuitively (since no single teacher and thus no single dataset dictates the student's training) and formally, in terms of differential privacy. These properties hold even if an adversary can not only query the student but also inspect its internal workings. Compared with previous work, the approach imposes only weak assumptions on how teachers are trained: it applies to any model, including non-convex models like DNNs. We achieve state-of-the-art privacy/utility trade-offs on MNIST and SVHN thanks to an improved privacy analysis and semi-supervised learning.