 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Leakage in Embedding Models
Mar 31, 2020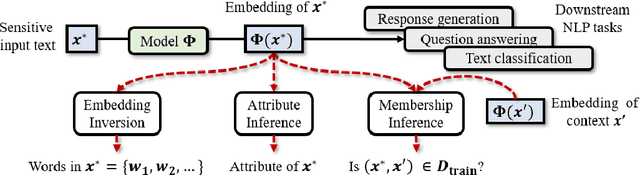
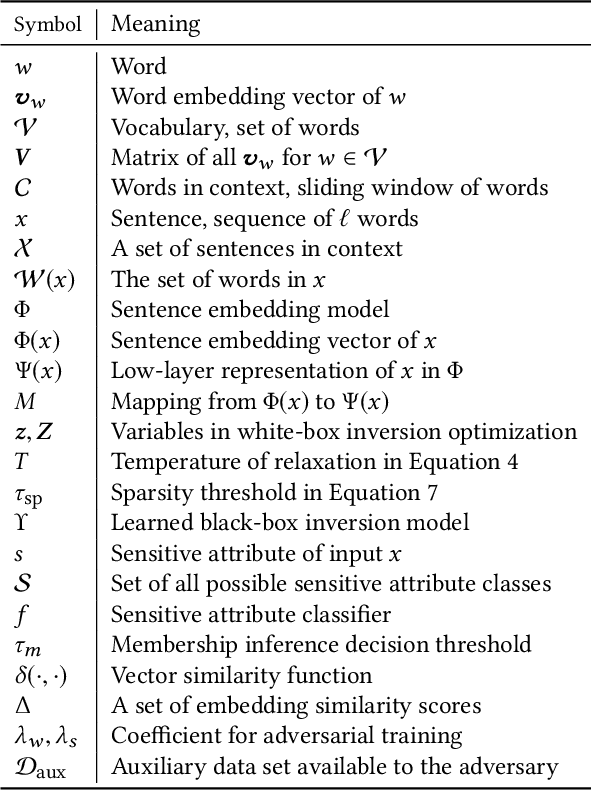
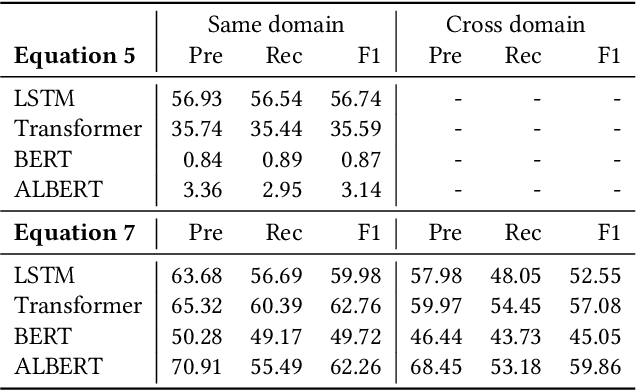
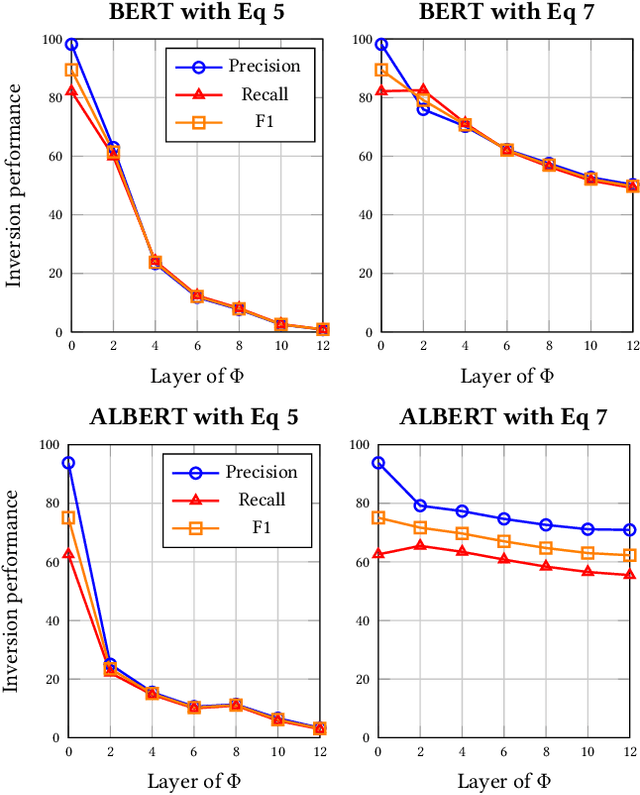
Embeddings are functions that map raw input data to low-dimensional vector representations, while preserving important semantic information about the inputs. Pre-training embeddings on a large amount of unlabeled data and fine-tuning them for downstream tasks is now a de facto standard in achieving state of the art learning in many domains. We demonstrate that embeddings, in addition to encoding generic semantics, often also present a vector that leaks sensitive information about the input data. We develop three classes of attacks to systematically study information that might be leaked by embeddings. First, embedding vectors can be inverted to partially recover some of the input data. As an example, we show that our attacks on popular sentence embeddings recover between 50\%--70\% of the input words (F1 scores of 0.5--0.7). Second, embeddings may reveal sensitive attributes inherent in inputs and independent of the underlying semantic task at hand. Attributes such as authorship of text can be easily extracted by training an inference model on just a handful of labeled embedding vectors. Third, embedding models leak moderate amount of membership information for infrequent training data inputs. We extensively evaluate our attacks on various state-of-the-art embedding models in the text domain. We also propose and evaluate defenses that can prevent the leakage to some extent at a minor cost in utility.
That which we call private
Aug 08, 2019A casual reader of the study by Jayaraman and Evans in USENIX Security 2019 might conclude that "relaxed definitions of differential privacy" should be avoided, because they "increase the measured privacy leakage." This note clarifies that their study is consistent with a different interpretation. Namely, that the "relaxed definitions" are strict improvements which can improve the epsilon upper-bound guarantees by orders-of-magnitude without changing the actual privacy loss. Practitioners should be careful not to equate real-world privacy with epsilon values, without consideration of their context.
Amplification by Shuffling: From Local to Central Differential Privacy via Anonymity
Nov 29, 2018Sensitive statistics are often collected across sets of users, with repeated collection of reports done over time. For example, trends in users' private preferences or software usage may be monitored via such reports. We study the collection of such statistics in the local differential privacy (LDP) model, and describe an algorithm whose privacy cost is polylogarithmic in the number of changes to a user's value. More fundamentally---by building on anonymity of the users' reports---we also demonstrate how the privacy cost of our LDP algorithm can actually be much lower when viewed in the central model of differential privacy. We show, via a new and general privacy amplification technique, that any permutation-invariant algorithm satisfying $\varepsilon$-local differential privacy will satisfy $(O(\varepsilon \sqrt{\log(1/\delta)/n}), \delta)$-central differential privacy. By this, we explain how the high noise and $\sqrt{n}$ overhead of LDP protocols is a consequence of them being significantly more private in the central model. As a practical corollary, our results imply that several LDP-based industrial deployments may have much lower privacy cost than their advertised $\varepsilon$ would indicate---at least if reports are anonymized.
Scalable Private Learning with PATE
Feb 24, 2018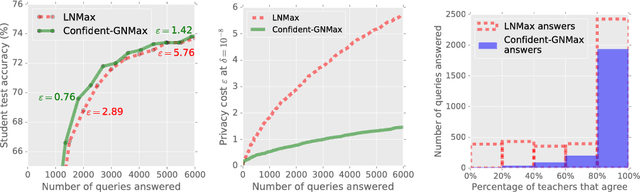
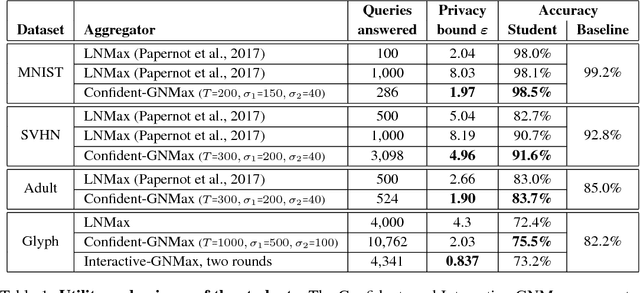
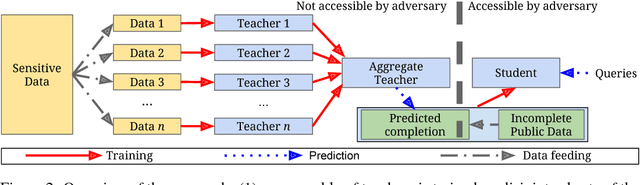
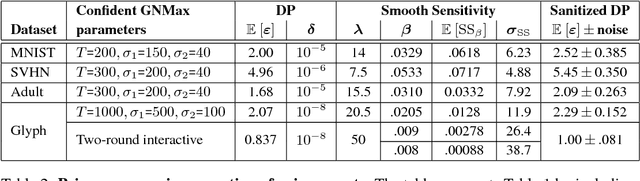
The rapid adoption of machine learning has increased concerns about the privacy implications of machine learning models trained on sensitive data, such as medical records or other personal information. To address those concerns, one promising approach is Private Aggregation of Teacher Ensembles, or PATE, which transfers to a "student" model the knowledge of an ensemble of "teacher" models, with intuitive privacy provided by training teachers on disjoint data and strong privacy guaranteed by noisy aggregation of teachers' answers. However, PATE has so far been evaluated only on simple classification tasks like MNIST, leaving unclear its utility when applied to larger-scale learning tasks and real-world datasets. In this work, we show how PATE can scale to learning tasks with large numbers of output classes and uncurated, imbalanced training data with errors. For this, we introduce new noisy aggregation mechanisms for teacher ensembles that are more selective and add less noise, and prove their tighter differential-privacy guarantees. Our new mechanisms build on two insights: the chance of teacher consensus is increased by using more concentrated noise and, lacking consensus, no answer need be given to a student. The consensus answers used are more likely to be correct, offer better intuitive privacy, and incur lower-differential privacy cost. Our evaluation shows our mechanisms improve on the original PATE on all measures, and scale to larger tasks with both high utility and very strong privacy ($\varepsilon$ < 1.0).