 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Leakage in Embedding Models
Paper and Code
Mar 31, 2020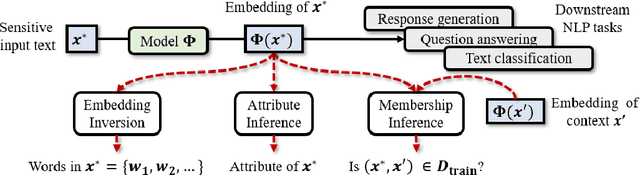
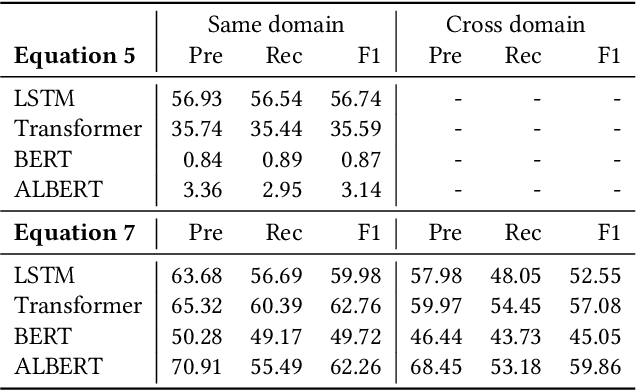
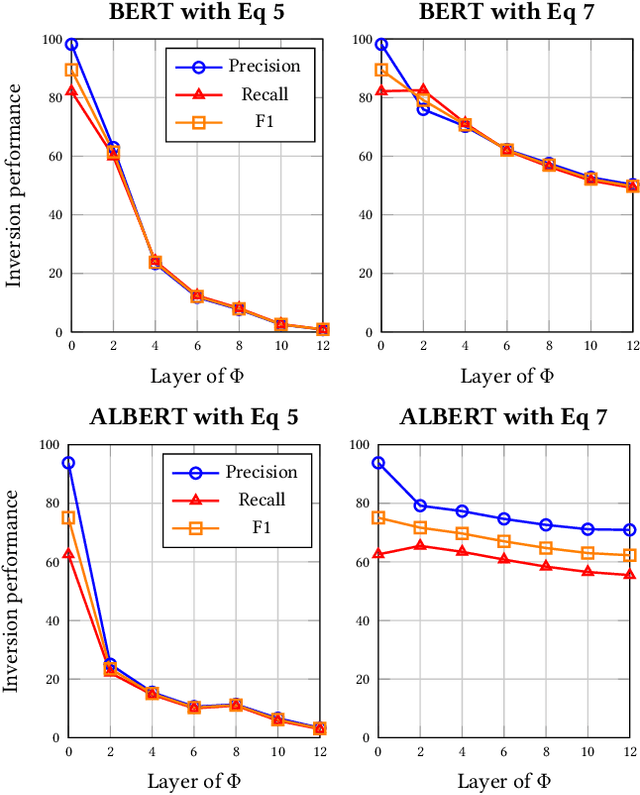
Embeddings are functions that map raw input data to low-dimensional vector representations, while preserving important semantic information about the inputs. Pre-training embeddings on a large amount of unlabeled data and fine-tuning them for downstream tasks is now a de facto standard in achieving state of the art learning in many domains. We demonstrate that embeddings, in addition to encoding generic semantics, often also present a vector that leaks sensitive information about the input data. We develop three classes of attacks to systematically study information that might be leaked by embeddings. First, embedding vectors can be inverted to partially recover some of the input data. As an example, we show that our attacks on popular sentence embeddings recover between 50\%--70\% of the input words (F1 scores of 0.5--0.7). Second, embeddings may reveal sensitive attributes inherent in inputs and independent of the underlying semantic task at hand. Attributes such as authorship of text can be easily extracted by training an inference model on just a handful of labeled embedding vectors. Third, embedding models leak moderate amount of membership information for infrequent training data inputs. We extensively evaluate our attacks on various state-of-the-art embedding models in the text domain. We also propose and evaluate defenses that can prevent the leakage to some extent at a minor cost in utility.