Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into adversarial attacks on deep policies
Paper and Code
May 18, 2017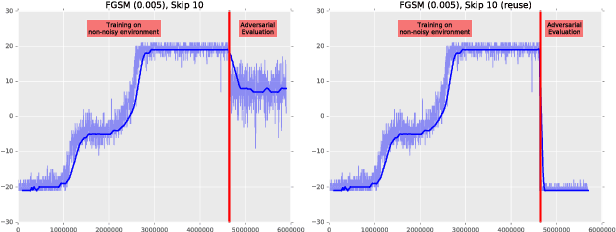
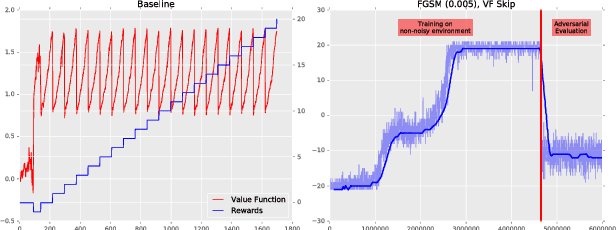
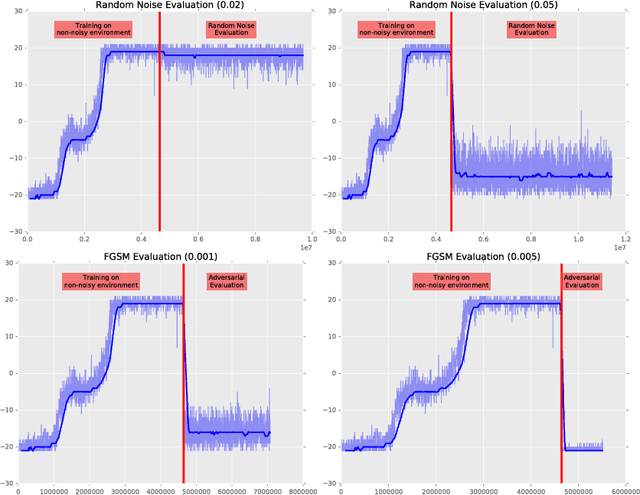
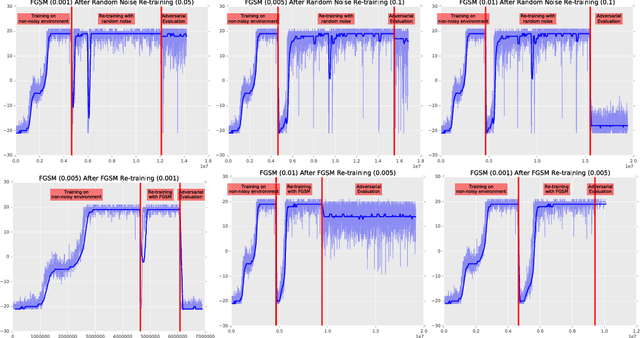
Adversarial examples have been shown to exist for a variety of deep learning architectures. Deep reinforcement learning has shown promising results on training agent policies directly on raw inputs such as image pixels. In this paper we present a novel study into adversarial attacks on deep reinforcement learning polices. We compare the effectiveness of the attacks using adversarial examples vs. random noise. We present a novel method for reducing the number of times adversarial examples need to be injected for a successful attack, based on the value function. We further explore how re-training on random noise and FGSM perturbations affects the resilience against adversarial examples.
* ICLR 2017 Workshop
View paper on