 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Emergent Capabilities by Finetuning
Paper and Code
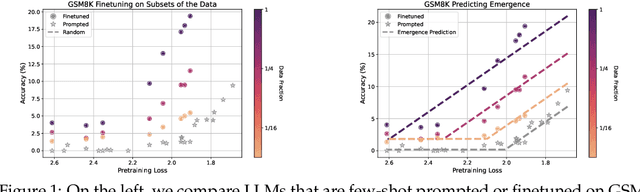

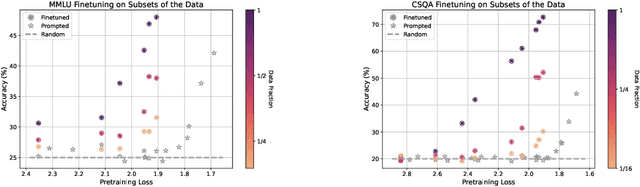
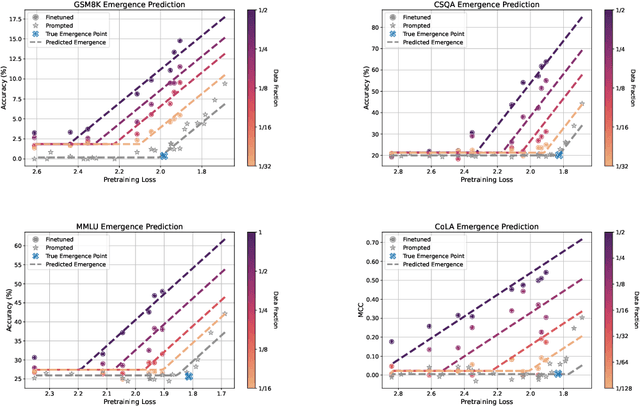
A fundamental open challenge in modern LLM scaling is the lack of understanding around emergent capabilities. In particular, language model pretraining loss is known to be highly predictable as a function of compute. However, downstream capabilities are far less predictable -- sometimes even exhibiting emergent jumps -- which makes it challenging to anticipate the capabilities of future models. In this work, we first pose the task of emergence prediction: given access to current LLMs that have random few-shot accuracy on a task, can we predict whether future models (GPT-N+1) will have non-trivial accuracy on that task? We then discover a simple insight for this problem: finetuning LLMs on a given task can shift the point in scaling at which emergence occurs towards less capable models. To operationalize this insight, we can finetune LLMs with varying amounts of data and fit a parametric function that predicts when emergence will occur (i.e., "emergence laws"). We validate this approach using four standard NLP benchmarks where large-scale open-source LLMs already demonstrate emergence (MMLU, GSM8K, CommonsenseQA, and CoLA). Using only small-scale LLMs, we find that, in some cases, we can accurately predict whether models trained with up to 4x more compute have emerged. Finally, we present a case study of two realistic uses for emergence prediction.