 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMFuse: Unified Multi View Fusion for Human Editing applications
Dec 01, 2022



The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.
VGFlow: Visibility guided Flow Network for Human Reposing
Nov 13, 2022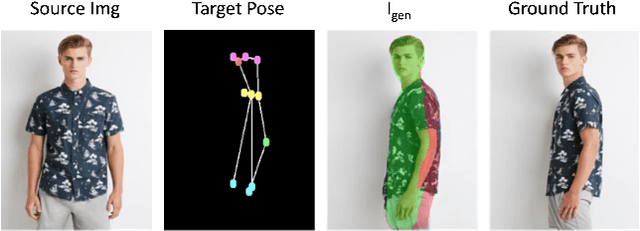



The task of human reposing involves generating a realistic image of a person standing in an arbitrary conceivable pose. There are multiple difficulties in generating perceptually accurate images, and existing methods suffer from limitations in preserving texture, maintaining pattern coherence, respecting cloth boundaries, handling occlusions, manipulating skin generation, etc. These difficulties are further exacerbated by the fact that the possible space of pose orientation for humans is large and variable, the nature of clothing items is highly non-rigid, and the diversity in body shape differs largely among the population. To alleviate these difficulties and synthesize perceptually accurate images, we propose VGFlow. Our model uses a visibility-guided flow module to disentangle the flow into visible and invisible parts of the target for simultaneous texture preservation and style manipulation. Furthermore, to tackle distinct body shapes and avoid network artifacts, we also incorporate a self-supervised patch-wise "realness" loss to improve the output. VGFlow achieves state-of-the-art results as observed qualitatively and quantitatively on different image quality metrics (SSIM, LPIPS, FID).