 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoPTA: Improving Document Layout Analysis using Patch-Text Alignment
Dec 17, 2024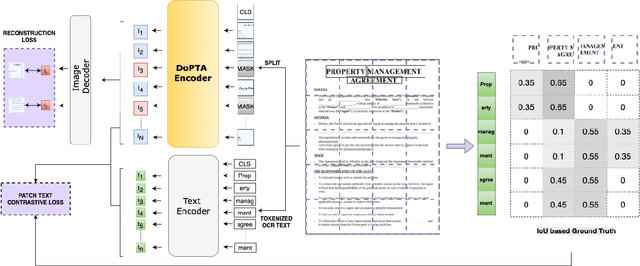
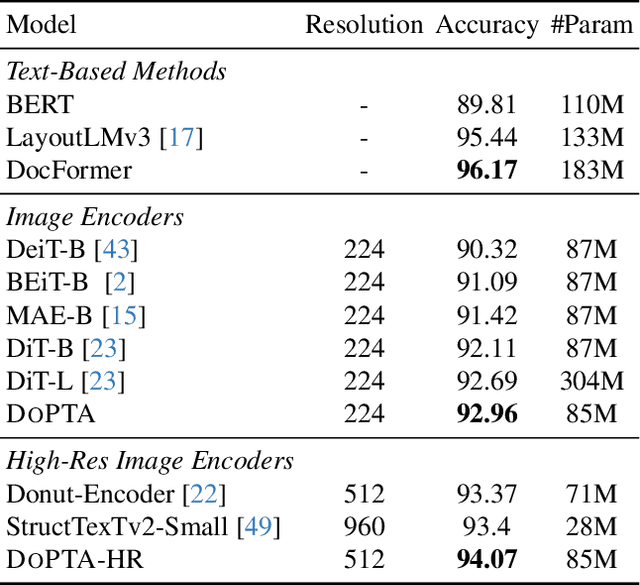

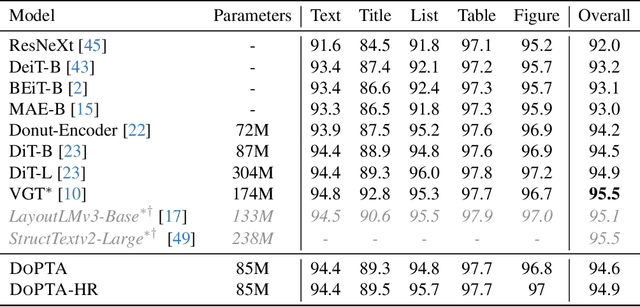
The advent of multimodal learning has brought a significant improvement in document AI. Documents are now treated as multimodal entities, incorporating both textual and visual information for downstream analysis. However, works in this space are often focused on the textual aspect, using the visual space as auxiliary information. While some works have explored pure vision based techniques for document image understanding, they require OCR identified text as input during inference, or do not align with text in their learning procedure. Therefore, we present a novel image-text alignment technique specially designed for leveraging the textual information in document images to improve performance on visual tasks. Our document encoder model DoPTA - trained with this technique demonstrates strong performance on a wide range of document image understanding tasks, without requiring OCR during inference. Combined with an auxiliary reconstruction objective, DoPTA consistently outperforms larger models, while using significantly lesser pre-training compute. DoPTA also sets new state-of-the art results on D4LA, and FUNSD, two challenging document visual analysis benchmarks.
Parameter Efficient Local Implicit Image Function Network for Face Segmentation
Mar 27, 2023Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.