 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Encoding Progressive Generative Adversarial Networks For 3D Multi Object Scenes
Mar 08, 2019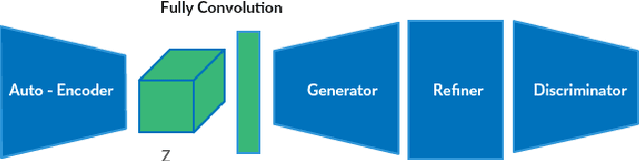
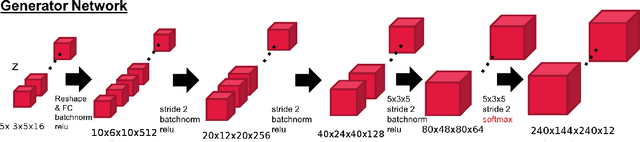
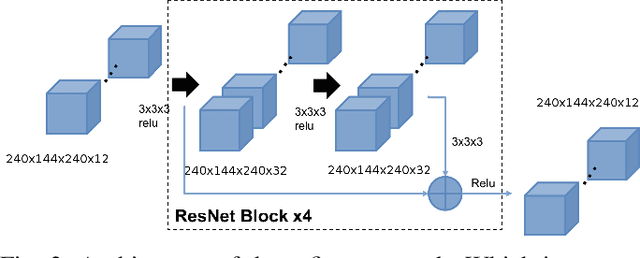

3D multi object generative models allow us to synthesize a large range of novel 3D multi object scenes and also identify objects, shapes, layouts and their positions. But multi object scenes are difficult to create because of the dataset being multimodal in nature. The conventional 3D generative adversarial models are not efficient in generating multi object scenes, they usually tend to generate either one object or generate fuzzy results of multiple objects. Auto-encoder models have much scope in feature extraction and representation learning using the unsupervised paradigm in probabilistic spaces. We try to make use of this property in our proposed model. In this paper we propose a novel architecture using 3DConvNets trained with the progressive training paradigm that has been able to generate realistic high resolution 3D scenes of rooms, bedrooms, offices etc. with various pieces of furniture and objects. We make use of the adversarial auto-encoder along with the WGAN-GP loss parameter in our discriminator loss function. Finally this new approach to multi object scene generation has also been able to generate more number of objects per scene.