 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Generative Adversarial Binary Networks for Music Generation
Mar 12, 2019
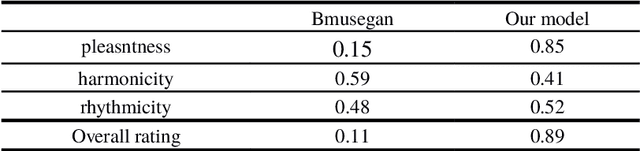
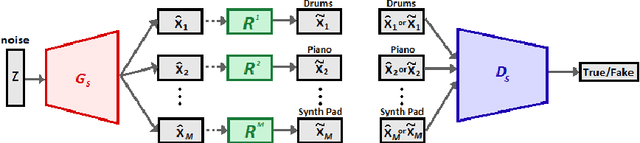

Recent improvements in generative adversarial network (GAN) training techniques prove that progressively training a GAN drastically stabilizes the training and improves the quality of outputs produced. Adding layers after the previous ones have converged has proven to help in better overall convergence and stability of the model as well as reducing the training time by a sufficient amount. Thus we use this training technique to train the model progressively in the time and pitch domain i.e. starting from a very small time value and pitch range we gradually expand the matrix sizes until the end result is a completely trained model giving outputs having tensor sizes [4 (bar) x 96 (time steps) x 84 (pitch values) x 8 (tracks)]. As proven in previously proposed models deterministic binary neurons also help in improving the results. Thus we make use of a layer of deterministic binary neurons at the end of the generator to get binary valued outputs instead of fractional values existing between 0 and 1.
Auto-Encoding Progressive Generative Adversarial Networks For 3D Multi Object Scenes
Mar 08, 2019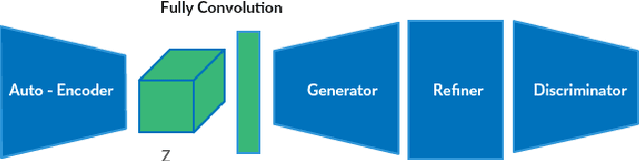
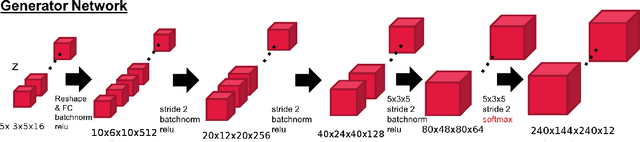
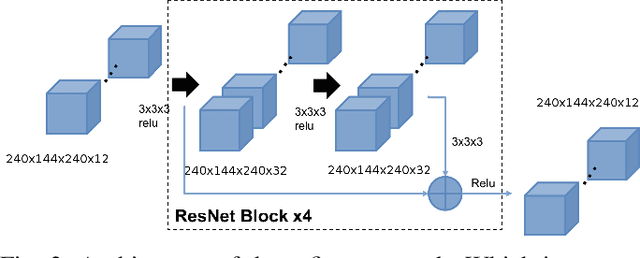

3D multi object generative models allow us to synthesize a large range of novel 3D multi object scenes and also identify objects, shapes, layouts and their positions. But multi object scenes are difficult to create because of the dataset being multimodal in nature. The conventional 3D generative adversarial models are not efficient in generating multi object scenes, they usually tend to generate either one object or generate fuzzy results of multiple objects. Auto-encoder models have much scope in feature extraction and representation learning using the unsupervised paradigm in probabilistic spaces. We try to make use of this property in our proposed model. In this paper we propose a novel architecture using 3DConvNets trained with the progressive training paradigm that has been able to generate realistic high resolution 3D scenes of rooms, bedrooms, offices etc. with various pieces of furniture and objects. We make use of the adversarial auto-encoder along with the WGAN-GP loss parameter in our discriminator loss function. Finally this new approach to multi object scene generation has also been able to generate more number of objects per scene.
MREAK : Morphological Retina Keypoint Descriptor
Jan 24, 2019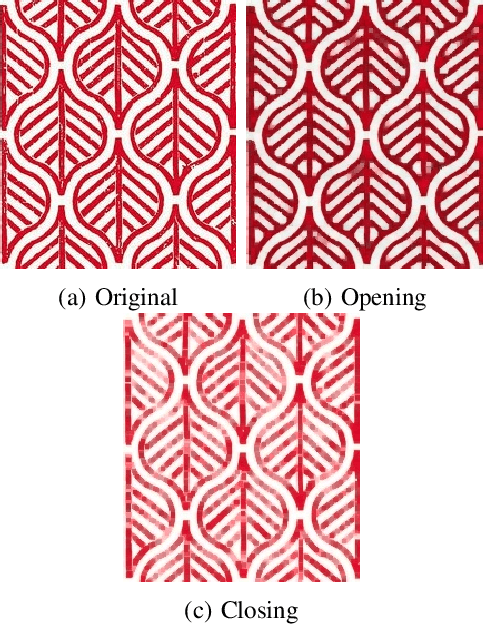
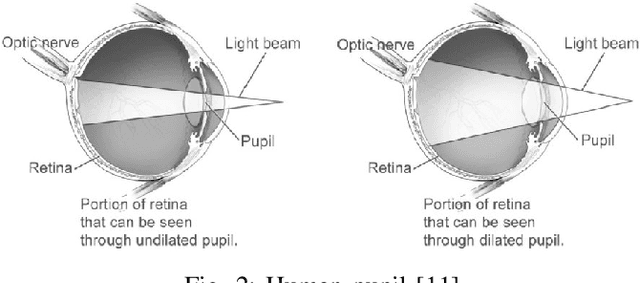
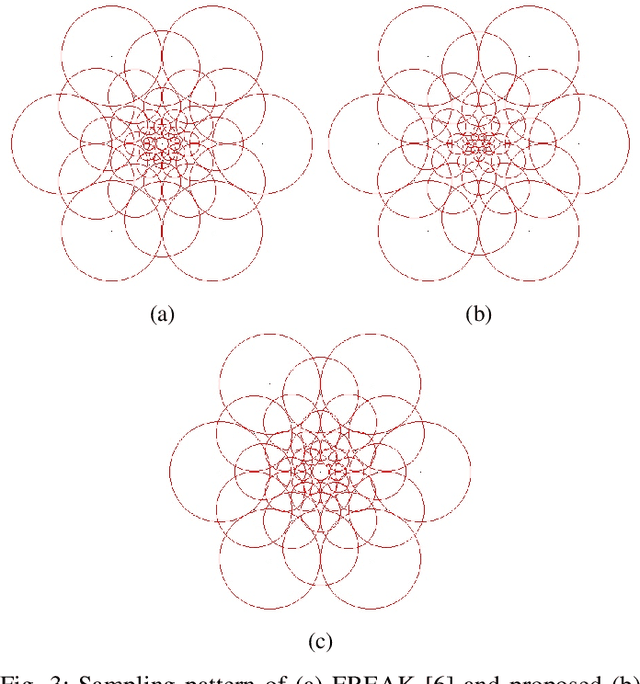
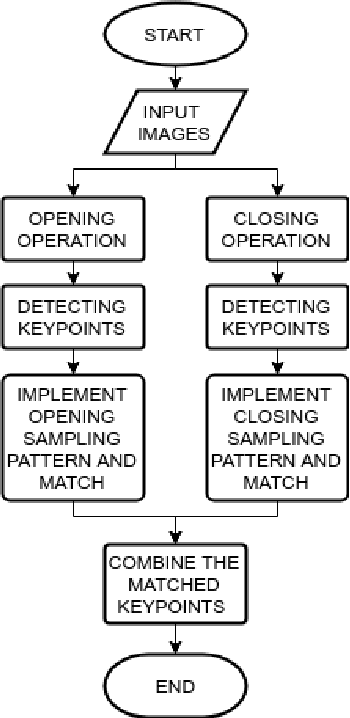
A variety of computer vision applications depend on the efficiency of image matching algorithms used. Various descriptors are designed to detect and match features in images. Deployment of this algorithms in mobile applications creates a need for low computation time. Binary descriptors requires less computation time than float-point based descriptors because of the intensity comparison between pairs of sample points and comparing after creating a binary string. In order to decrease time complexity, quality of keypoints matched is often compromised. We propose a keypoint descriptor named Morphological Retina Keypoint Descriptor (MREAK) inspired by the function of human pupil which dilates and constricts responding to the amount of light. By using morphological operators of opening and closing and modifying the retinal sampling pattern accordingly, an increase in the number of accurately matched keypoints is observed. Our results show that matched keypoints are more efficient than FREAK descriptor and requires low computation time than various descriptors like SIFT, BRISK and SURF.
Semi-Supervised Image-to-Image Translation
Jan 24, 2019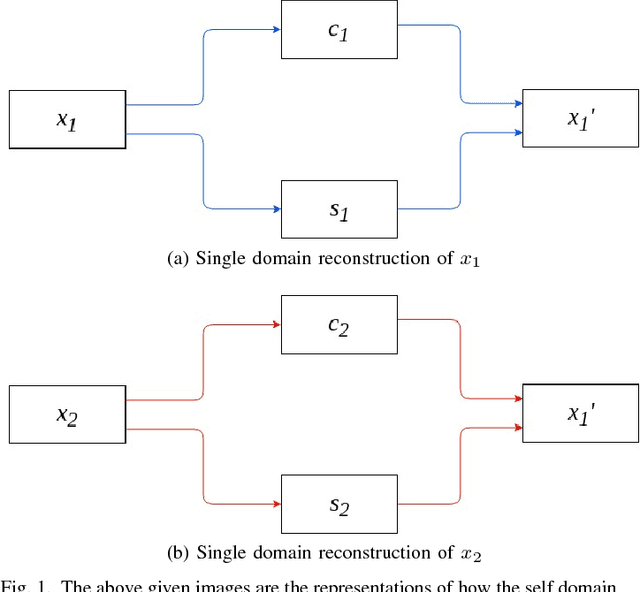
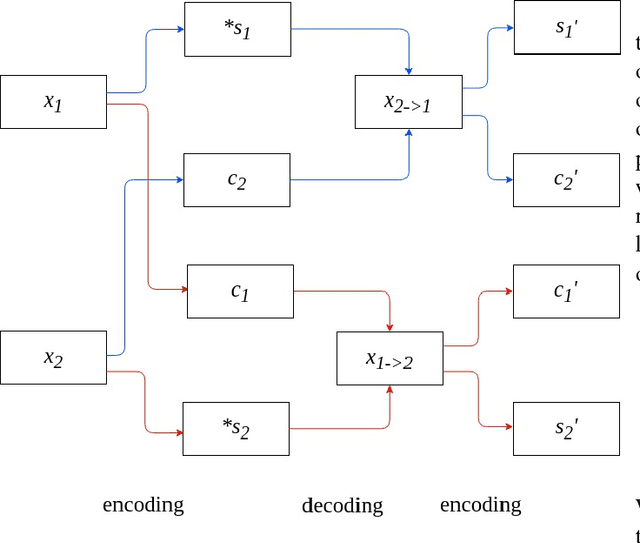
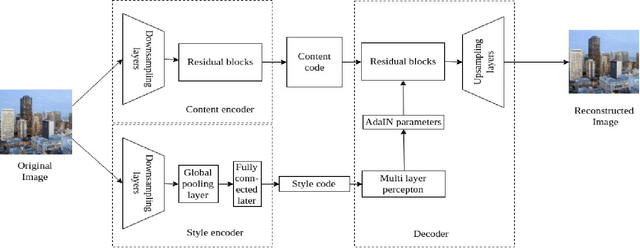

Image-to-image translation is a long-established and a difficult problem in computer vision. In this paper we propose an adversarial based model for image-to-image translation. The regular deep neural-network based methods perform the task of image-to-image translation by comparing gram matrices and using image segmentation which requires human intervention. Our generative adversarial network based model works on a conditional probability approach. This approach makes the image translation independent of any local, global and content or style features. In our approach we use a bidirectional reconstruction model appended with the affine transform factor that helps in conserving the content and photorealism as compared to other models. The advantage of using such an approach is that the image-to-image translation is semi-supervised, independant of image segmentation and inherits the properties of generative adversarial networks tending to produce realistic. This method has proven to produce better results than Multimodal Unsupervised Image-to-image translation.