 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDIGO: Intrinsic Multimodality for Domain Generalization
Jun 13, 2022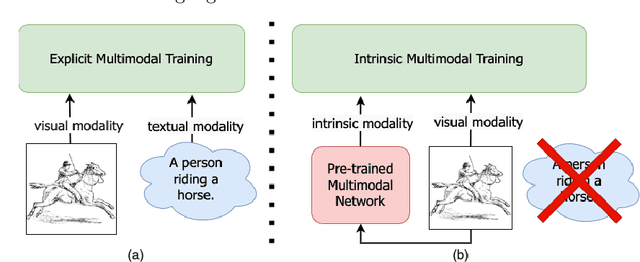
For models to generalize under unseen domains (a.k.a domain generalization), it is crucial to learn feature representations that are domain-agnostic and capture the underlying semantics that makes up an object category. Recent advances towards weakly supervised vision-language models that learn holistic representations from cheap weakly supervised noisy text annotations have shown their ability on semantic understanding by capturing object characteristics that generalize under different domains. However, when multiple source domains are involved, the cost of curating textual annotations for every image in the dataset can blow up several times, depending on their number. This makes the process tedious and infeasible, hindering us from directly using these supervised vision-language approaches to achieve the best generalization on an unseen domain. Motivated from this, we study how multimodal information from existing pre-trained multimodal networks can be leveraged in an "intrinsic" way to make systems generalize under unseen domains. To this end, we propose IntriNsic multimodality for DomaIn GeneralizatiOn (INDIGO), a simple and elegant way of leveraging the intrinsic modality present in these pre-trained multimodal networks along with the visual modality to enhance generalization to unseen domains at test-time. We experiment on several Domain Generalization settings (ClosedDG, OpenDG, and Limited sources) and show state-of-the-art generalization performance on unseen domains. Further, we provide a thorough analysis to develop a holistic understanding of INDIGO.
Context-Conditional Adaptation for Recognizing Unseen Classes in Unseen Domains
Jul 15, 2021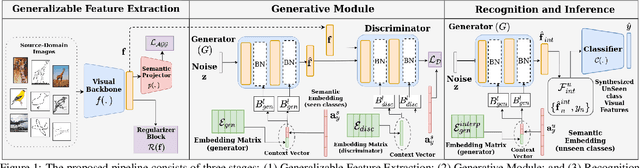
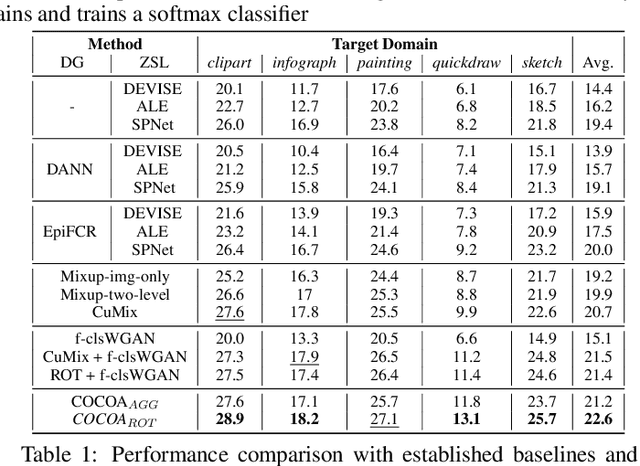
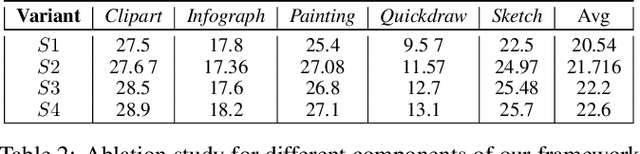
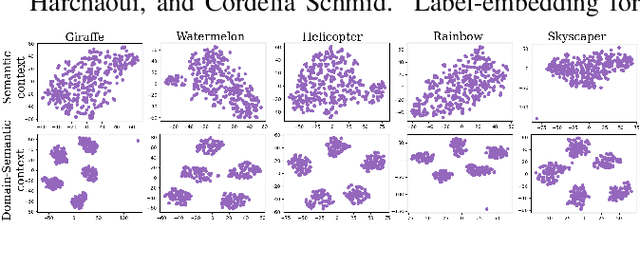
Recent progress towards designing models that can generalize to unseen domains (i.e domain generalization) or unseen classes (i.e zero-shot learning) has embarked interest towards building models that can tackle both domain-shift and semantic shift simultaneously (i.e zero-shot domain generalization). For models to generalize to unseen classes in unseen domains, it is crucial to learn feature representation that preserves class-level (domain-invariant) as well as domain-specific information. Motivated from the success of generative zero-shot approaches, we propose a feature generative framework integrated with a COntext COnditional Adaptive (COCOA) Batch-Normalization to seamlessly integrate class-level semantic and domain-specific information. The generated visual features better capture the underlying data distribution enabling us to generalize to unseen classes and domains at test-time. We thoroughly evaluate and analyse our approach on established large-scale benchmark - DomainNet and demonstrate promising performance over baselines and state-of-art methods.
Data Instance Prior for Transfer Learning in GANs
Dec 08, 2020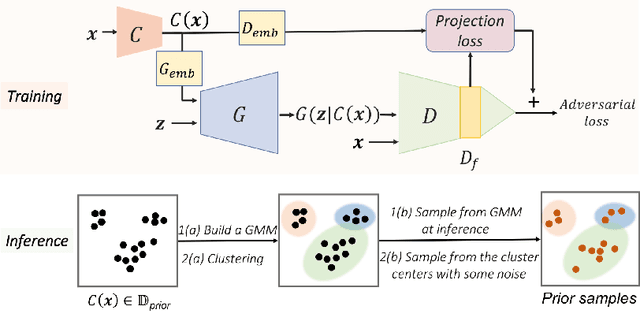
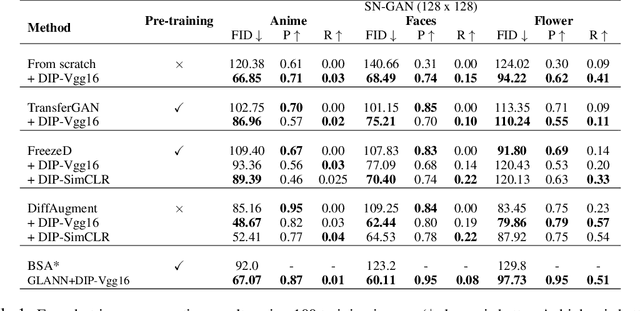
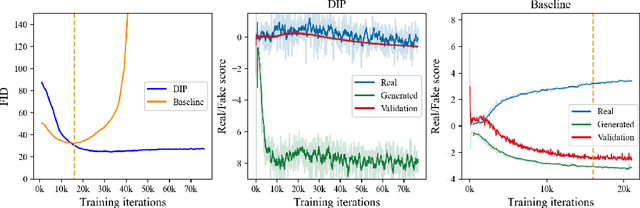
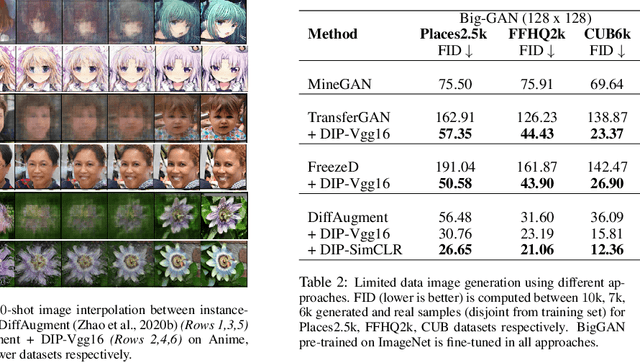
Recent advances in generative adversarial networks (GANs) have shown remarkable progress in generating high-quality images. However, this gain in performance depends on the availability of a large amount of training data. In limited data regimes, training typically diverges, and therefore the generated samples are of low quality and lack diversity. Previous works have addressed training in low data setting by leveraging transfer learning and data augmentation techniques. We propose a novel transfer learning method for GANs in the limited data domain by leveraging informative data prior derived from self-supervised/supervised pre-trained networks trained on a diverse source domain. We perform experiments on several standard vision datasets using various GAN architectures (BigGAN, SNGAN, StyleGAN2) to demonstrate that the proposed method effectively transfers knowledge to domains with few target images, outperforming existing state-of-the-art techniques in terms of image quality and diversity. We also show the utility of data instance prior in large-scale unconditional image generation and image editing tasks.
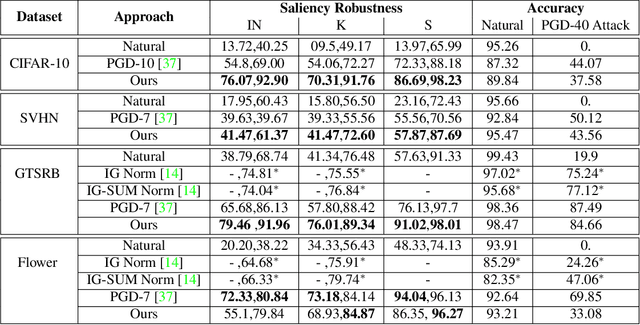
On Saliency Maps and Adversarial Robustness
Jul 13, 2020
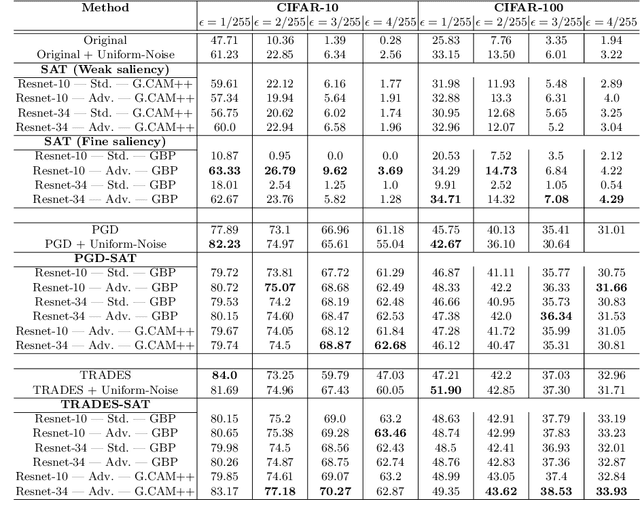
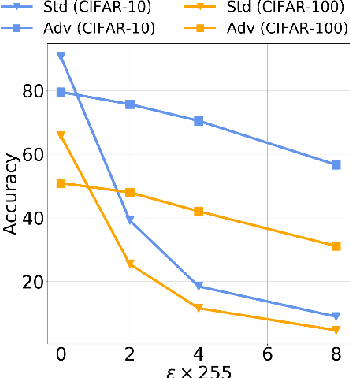
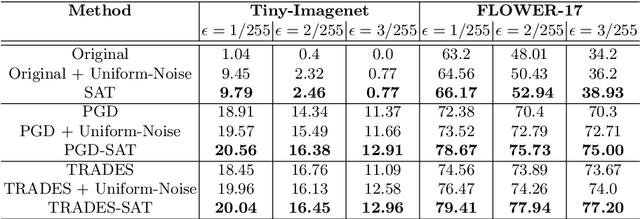
A Very recent trend has emerged to couple the notion of interpretability and adversarial robustness, unlike earlier efforts which solely focused on good interpretations or robustness against adversaries. Works have shown that adversarially trained models exhibit more interpretable saliency maps than their non-robust counterparts, and that this behavior can be quantified by considering the alignment between input image and saliency map. In this work, we provide a different perspective to this coupling, and provide a method, Saliency based Adversarial training (SAT), to use saliency maps to improve adversarial robustness of a model. In particular, we show that using annotations such as bounding boxes and segmentation masks, already provided with a dataset, as weak saliency maps, suffices to improve adversarial robustness with no additional effort to generate the perturbations themselves. Our empirical results on CIFAR-10, CIFAR-100, Tiny ImageNet and Flower-17 datasets consistently corroborate our claim, by showing improved adversarial robustness using our method. saliency maps. We also show how using finer and stronger saliency maps leads to more robust models, and how integrating SAT with existing adversarial training methods, further boosts performance of these existing methods.
VarMixup: Exploiting the Latent Space for Robust Training and Inference
Mar 14, 2020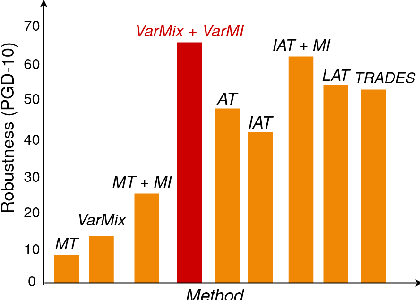

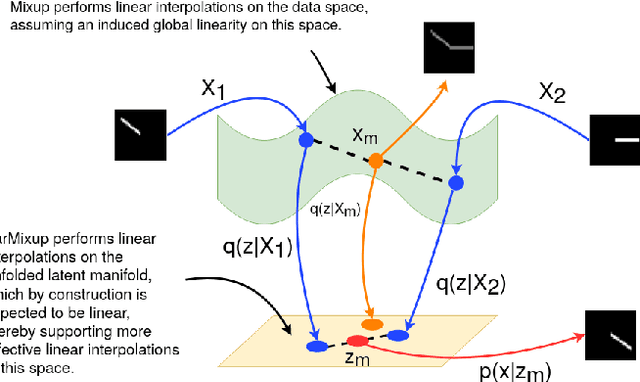
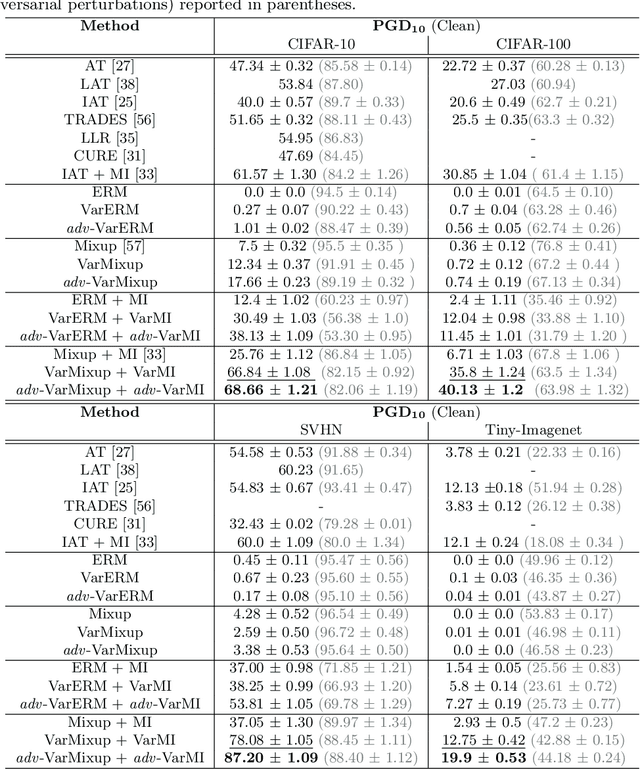
The vulnerability of Deep Neural Networks (DNNs) to adversarial attacks has led to the development of many defense approaches. Among them, Adversarial Training (AT) is a popular and widely used approach for training adversarially robust models. Mixup Training (MT), a recent popular training algorithm, improves the generalization performance of models by introducing globally linear behavior in between training examples. Although still in its early phase, we observe a shift in trend of exploiting Mixup from perspectives of generalisation to that of adversarial robustness. It has been shown that the Mixup trained models improves the robustness of models but only passively. A recent approach, Mixup Inference (MI), proposes an inference principle for Mixup trained models to counter adversarial examples at inference time by mixing the input with other random clean samples. In this work, we propose a new approach - \textit{VarMixup (Variational Mixup)} - to better sample mixup images by using the latent manifold underlying the data. Our experiments on CIFAR-10, CIFAR-100, SVHN and Tiny-Imagenet demonstrate that \textit{VarMixup} beats state-of-the-art AT techniques without training the model adversarially. Additionally, we also conduct ablations that show that models trained on \textit{VarMixup} samples are also robust to various input corruptions/perturbations, have low calibration error and are transferable.
On the Benefits of Attributional Robustness
Dec 10, 2019
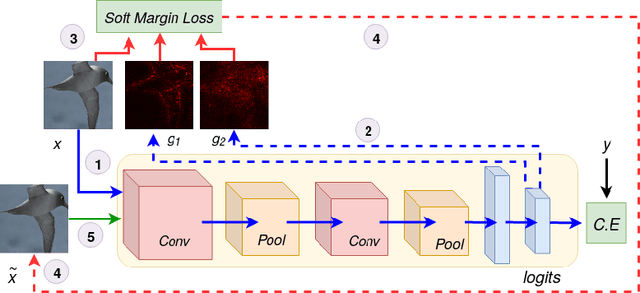
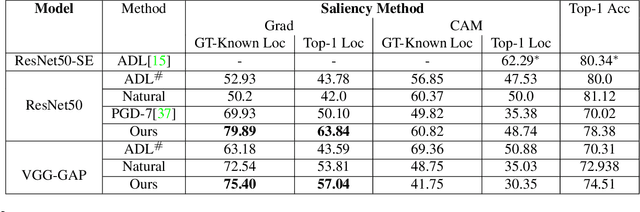
Interpretability is an emerging area of research in trustworthy machine learning. Safe deployment of machine learning system mandates that the prediction and its explanation be reliable and robust. Recently, it was shown that one could craft perturbations that produce perceptually indistinguishable inputs having the same prediction, yet very different interpretations. We tackle the problem of attributional robustness (i.e. models having robust explanations) by maximizing the alignment between the input image and its saliency map using soft-margin triplet loss. We propose a robust attribution training methodology that beats the state-of-the-art attributional robustness measure by a margin of approximately 6-18% on several standard datasets, ie. SVHN, CIFAR-10 and GTSRB. We further show the utility of the proposed robust model in the domain of weakly supervised object localization and segmentation. Our proposed robust model also achieves a new state-of-the-art object localization accuracy on the CUB-200 dataset.
Charting the Right Manifold: Manifold Mixup for Few-shot Learning
Aug 07, 2019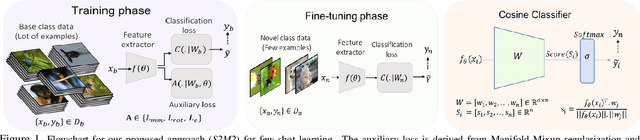
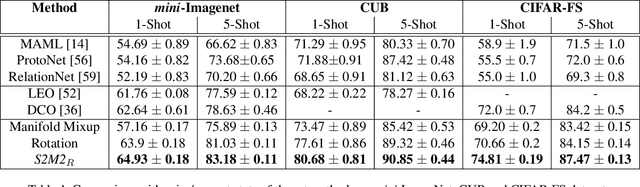
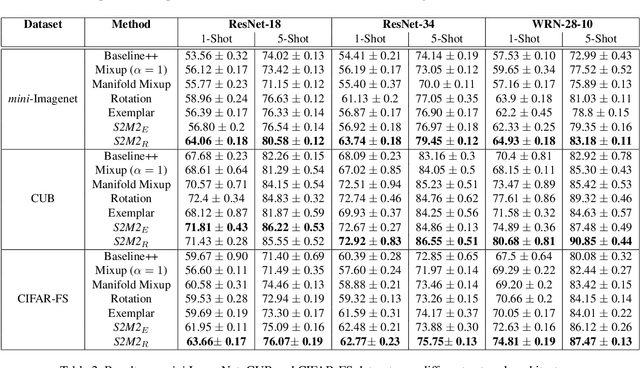
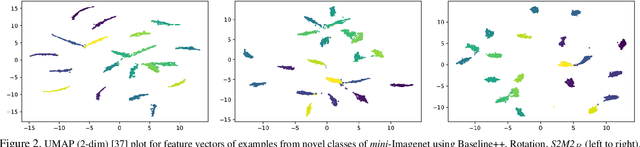
Few-shot learning algorithms aim to learn model parameters capable of adapting to unseen classes with the help of only a few labeled examples. A recent regularization technique - Manifold Mixup focuses on learning a general-purpose representation, robust to small changes in the data distribution. Since the goal of few-shot learning is closely linked to robust representation learning, we study Manifold Mixup in this problem setting. Self-supervised learning is another technique that learns semantically meaningful features, using only the inherent structure of the data. This work investigates the role of learning relevant feature manifold for few-shot tasks using self-supervision and regularization techniques. We observe that regularizing the feature manifold, enriched via self-supervised techniques, with Manifold Mixup significantly improves few-shot learning performance. We show that our proposed method S2M2 beats the current state-of-the-art accuracy on standard few-shot learning datasets like CIFAR-FS, CUB and mini-ImageNet by 3-8%. Through extensive experimentation, we show that the features learned using our approach generalize to complex few-shot evaluation tasks, cross-domain scenarios and are robust against slight changes to data distribution.
AdvGAN++ : Harnessing latent layers for adversary generation
Aug 02, 2019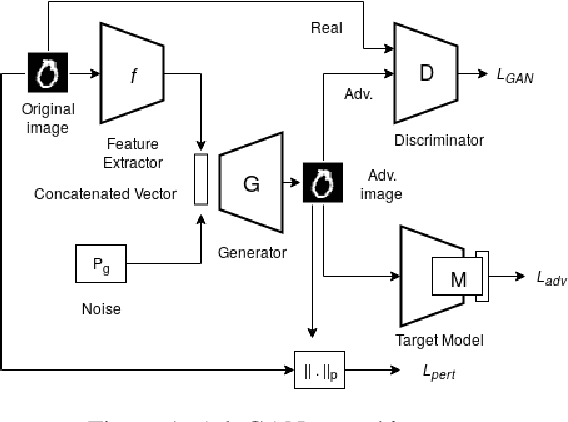
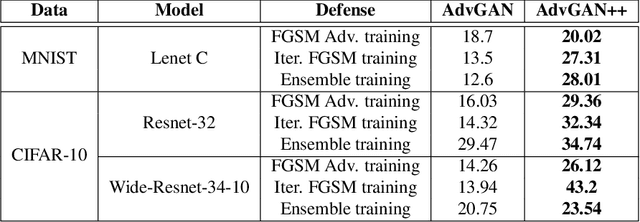
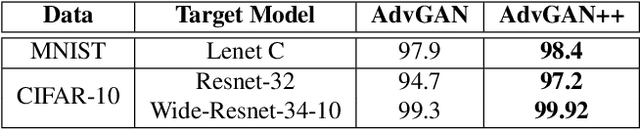

Adversarial examples are fabricated examples, indistinguishable from the original image that mislead neural networks and drastically lower their performance. Recently proposed AdvGAN, a GAN based approach, takes input image as a prior for generating adversaries to target a model. In this work, we show how latent features can serve as better priors than input images for adversary generation by proposing AdvGAN++, a version of AdvGAN that achieves higher attack rates than AdvGAN and at the same time generates perceptually realistic images on MNIST and CIFAR-10 datasets.