 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDIGO: Intrinsic Multimodality for Domain Generalization
Paper and Code
Jun 13, 2022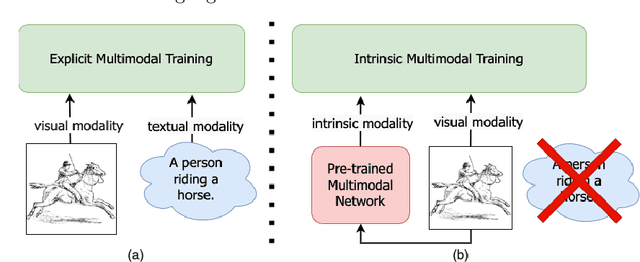
For models to generalize under unseen domains (a.k.a domain generalization), it is crucial to learn feature representations that are domain-agnostic and capture the underlying semantics that makes up an object category. Recent advances towards weakly supervised vision-language models that learn holistic representations from cheap weakly supervised noisy text annotations have shown their ability on semantic understanding by capturing object characteristics that generalize under different domains. However, when multiple source domains are involved, the cost of curating textual annotations for every image in the dataset can blow up several times, depending on their number. This makes the process tedious and infeasible, hindering us from directly using these supervised vision-language approaches to achieve the best generalization on an unseen domain. Motivated from this, we study how multimodal information from existing pre-trained multimodal networks can be leveraged in an "intrinsic" way to make systems generalize under unseen domains. To this end, we propose IntriNsic multimodality for DomaIn GeneralizatiOn (INDIGO), a simple and elegant way of leveraging the intrinsic modality present in these pre-trained multimodal networks along with the visual modality to enhance generalization to unseen domains at test-time. We experiment on several Domain Generalization settings (ClosedDG, OpenDG, and Limited sources) and show state-of-the-art generalization performance on unseen domains. Further, we provide a thorough analysis to develop a holistic understanding of INDIGO.