 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Benefits of Attributional Robustness
Paper and Code

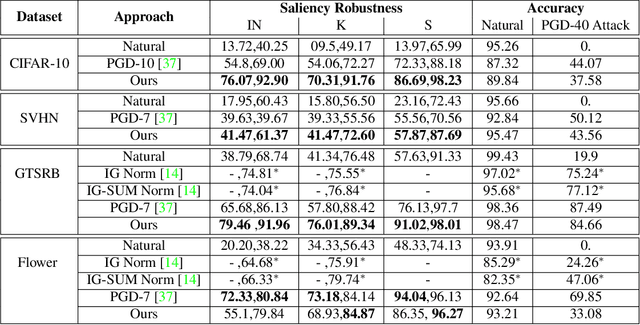
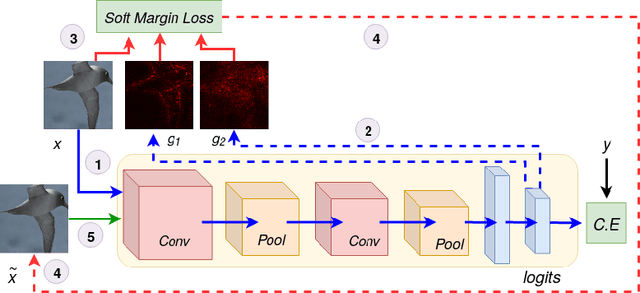
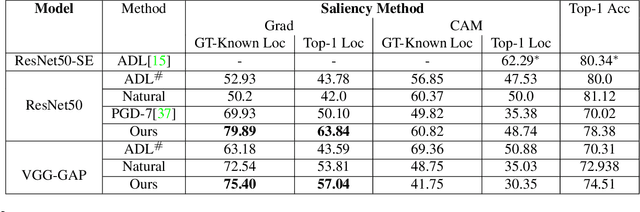
Interpretability is an emerging area of research in trustworthy machine learning. Safe deployment of machine learning system mandates that the prediction and its explanation be reliable and robust. Recently, it was shown that one could craft perturbations that produce perceptually indistinguishable inputs having the same prediction, yet very different interpretations. We tackle the problem of attributional robustness (i.e. models having robust explanations) by maximizing the alignment between the input image and its saliency map using soft-margin triplet loss. We propose a robust attribution training methodology that beats the state-of-the-art attributional robustness measure by a margin of approximately 6-18% on several standard datasets, ie. SVHN, CIFAR-10 and GTSRB. We further show the utility of the proposed robust model in the domain of weakly supervised object localization and segmentation. Our proposed robust model also achieves a new state-of-the-art object localization accuracy on the CUB-200 dataset.