 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskMix: Data Augmentation for Meta-Learning of Spoken Intent Understanding
Sep 26, 2022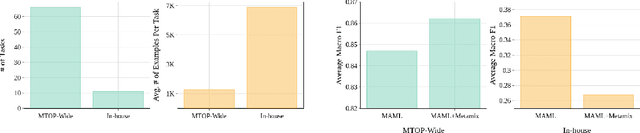
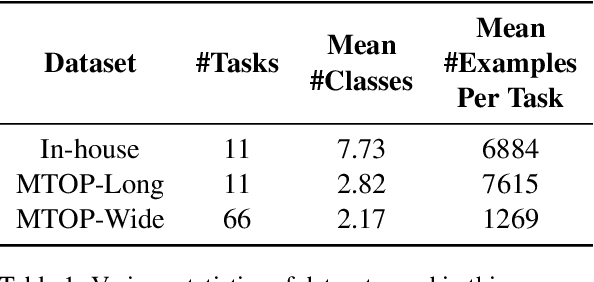
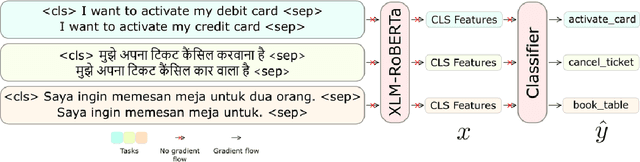
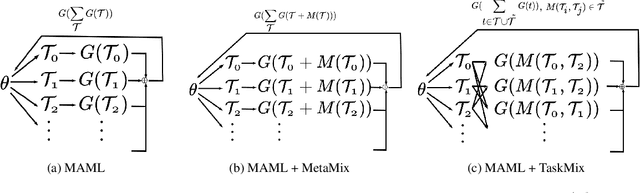
Meta-Learning has emerged as a research direction to better transfer knowledge from related tasks to unseen but related tasks. However, Meta-Learning requires many training tasks to learn representations that transfer well to unseen tasks; otherwise, it leads to overfitting, and the performance degenerates to worse than Multi-task Learning. We show that a state-of-the-art data augmentation method worsens this problem of overfitting when the task diversity is low. We propose a simple method, TaskMix, which synthesizes new tasks by linearly interpolating existing tasks. We compare TaskMix against many baselines on an in-house multilingual intent classification dataset of N-Best ASR hypotheses derived from real-life human-machine telephony utterances and two datasets derived from MTOP. We show that TaskMix outperforms baselines, alleviates overfitting when task diversity is low, and does not degrade performance even when it is high.
Not All Lotteries Are Made Equal
Jun 16, 2022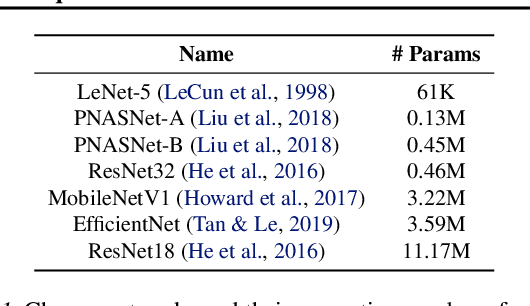

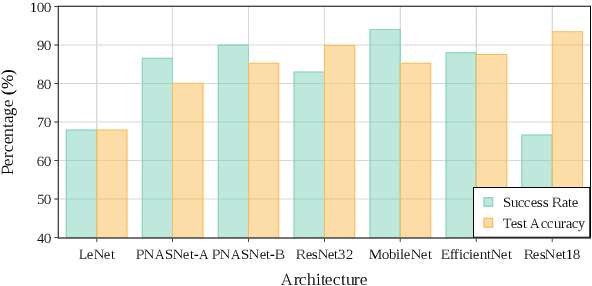
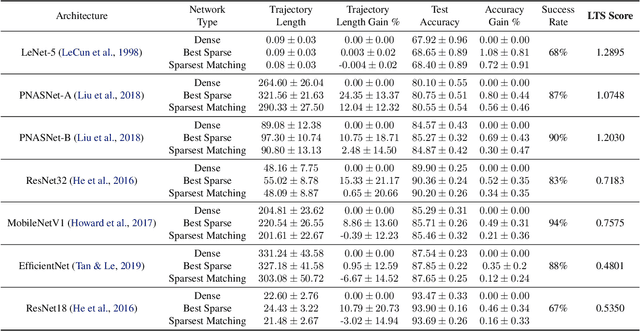
The Lottery Ticket Hypothesis (LTH) states that for a reasonably sized neural network, a sub-network within the same network yields no less performance than the dense counterpart when trained from the same initialization. This work investigates the relation between model size and the ease of finding these sparse sub-networks. We show through experiments that, surprisingly, under a finite budget, smaller models benefit more from Ticket Search (TS).
AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning
Dec 02, 2021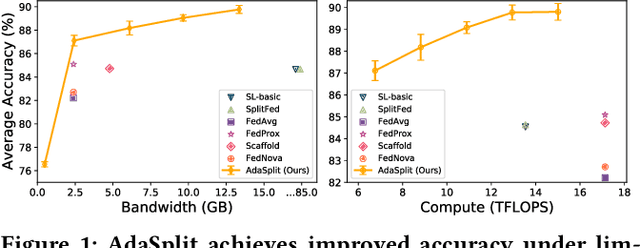
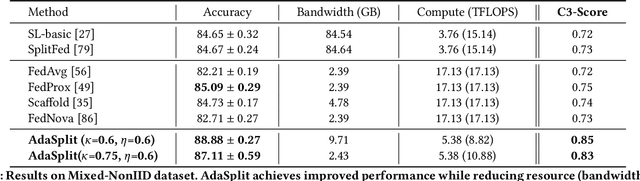
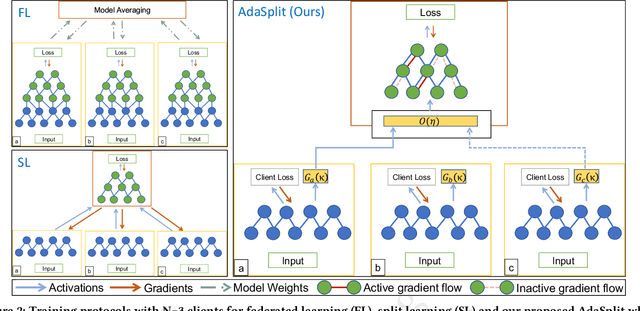
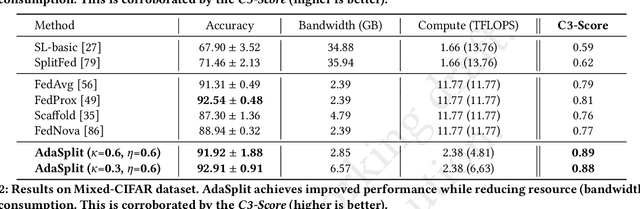
Distributed deep learning frameworks like federated learning (FL) and its variants are enabling personalized experiences across a wide range of web clients and mobile/IoT devices. However, FL-based frameworks are constrained by computational resources at clients due to the exploding growth of model parameters (eg. billion parameter model). Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. To capture and benchmark this multi-dimensional nature of distributed deep learning, we also introduce C3-Score, a metric to evaluate performance under resource budgets. We validate the effectiveness of AdaSplit under limited resources through extensive experimental comparison with strong federated and split learning baselines. We also present a sensitivity analysis of key design choices in AdaSplit which validates the ability of AdaSplit to provide adaptive trade-offs across variable resource budgets.
Audiomer: A Convolutional Transformer for Keyword Spotting
Sep 21, 2021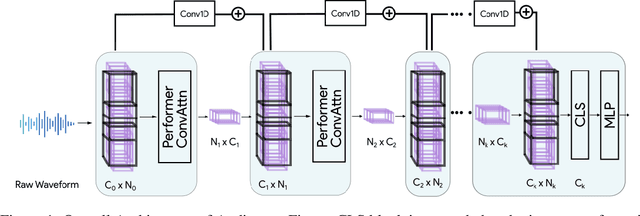

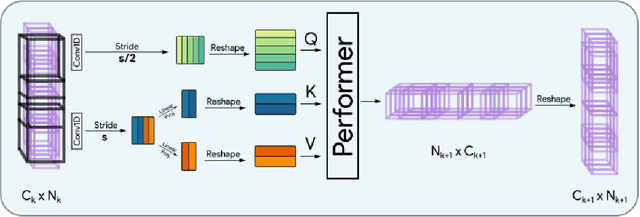
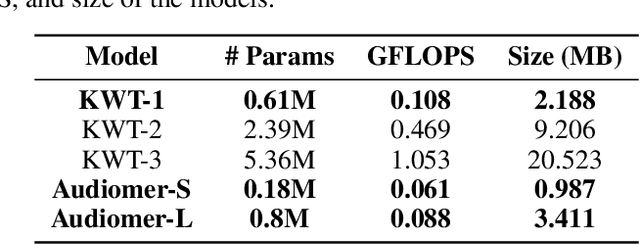
Transformers have seen an unprecedented rise in Natural Language Processing and Computer Vision tasks. However, in audio tasks, they are either infeasible to train due to extremely large sequence length of audio waveforms or reach competitive performance after feature extraction through Fourier-based methods, incurring a loss-floor. In this work, we introduce an architecture, Audiomer, where we combine 1D Residual Networks with Performer Attention to achieve state-of-the-art performance in Keyword Spotting with raw audio waveforms, out-performing all previous methods while also being computationally cheaper, much more parameter and data-efficient. Audiomer allows for deployment in compute-constrained devices and training on smaller datasets.
Improved Representation Learning for Session-based Recommendation
Jul 04, 2021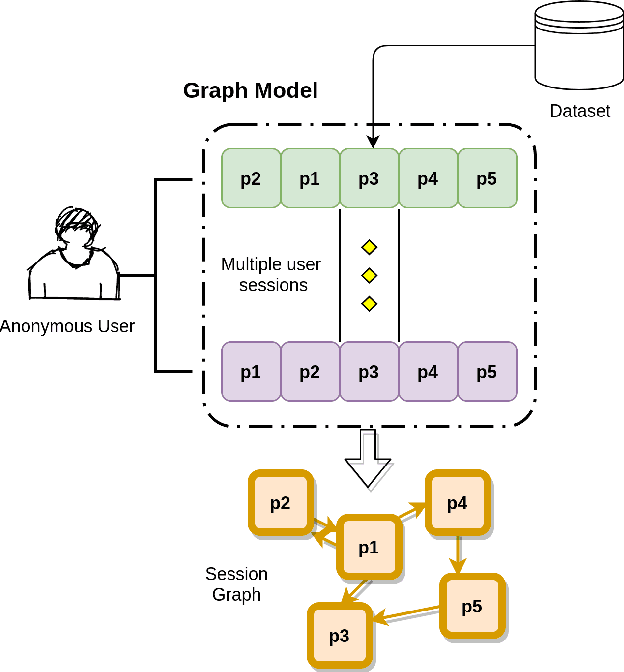

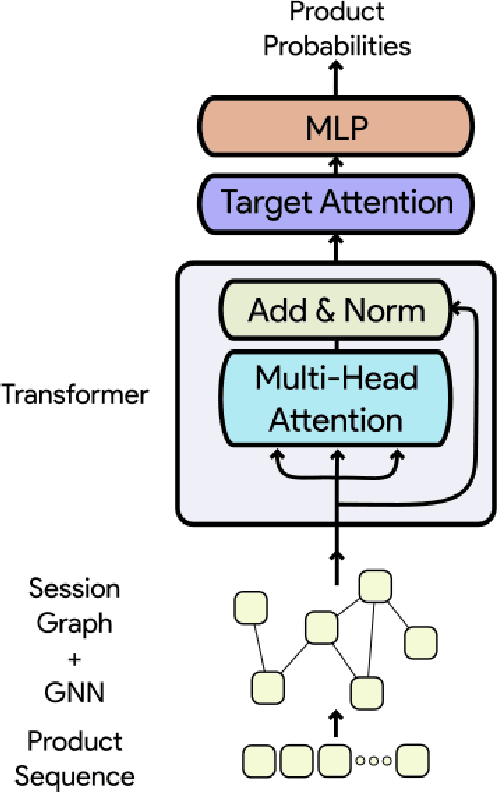
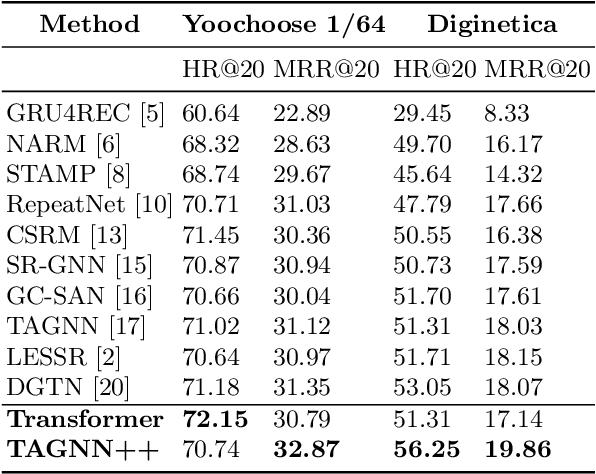
Session-based recommendation systems suggest relevant items to users by modeling user behavior and preferences using short-term anonymous sessions. Existing methods leverage Graph Neural Networks (GNNs) that propagate and aggregate information from neighboring nodes i.e., local message passing. Such graph-based architectures have representational limits, as a single sub-graph is susceptible to overfit the sequential dependencies instead of accounting for complex transitions between items in different sessions. We propose using a Transformer in combination with a target attentive GNN, which allows richer Representation Learning. Our experimental results and ablation show that our proposed method outperforms the existing methods on real-world benchmark datasets.
On The Connection of Benford's Law and Neural Networks
Feb 05, 2021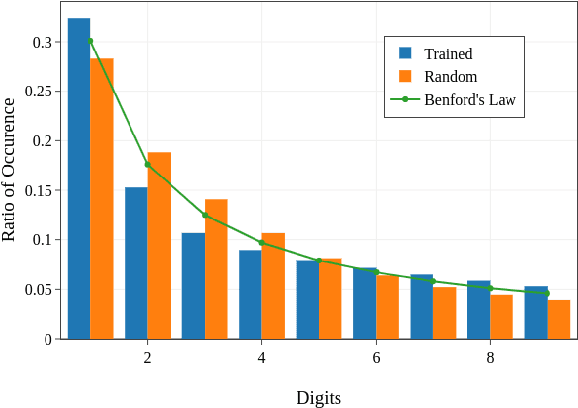
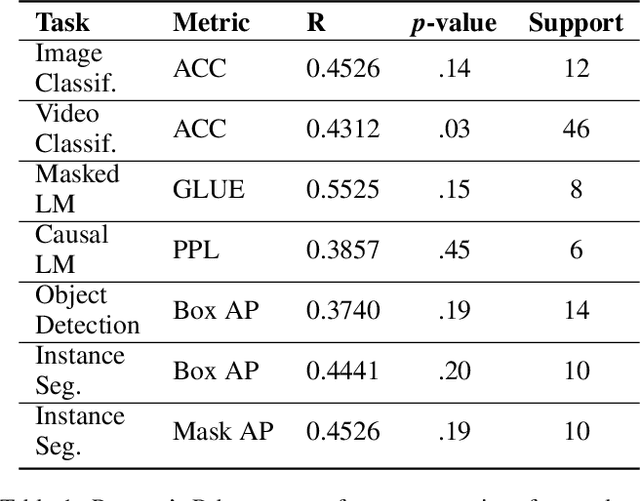
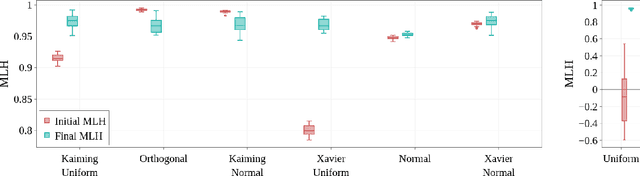
Benford's law, also called Significant Digit Law, is observed in many naturally occurring data-sets. For instance, the physical constants such as Gravitational, Coulomb's Constant, etc., follow this law. In this paper, we define a score, $MLH$, for how closely a Neural Network's Weights match Benford's law. We show that Neural Network Weights follow Benford's Law regardless of the initialization method. We make a striking connection between Generalization and the $MLH$ of the network. We provide evidence that several architectures from AlexNet to ResNeXt trained on ImageNet, Transformers (BERT, Electra, etc.), and other pre-trained models on a wide variety of tasks have a strong correlation between their test performance and the $MLH$. We also investigate the influence of Data in the Weights to explain why NNs possibly follow Benford's Law. With repeated experiments on multiple datasets using MLPs, CNNs, and LSTMs, we provide empirical evidence that there is a connection between $MLH$ while training, overfitting. Understanding this connection between Benford's Law and Neural Networks promises a better comprehension of the latter.