 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Lotteries Are Made Equal
Jun 16, 2022

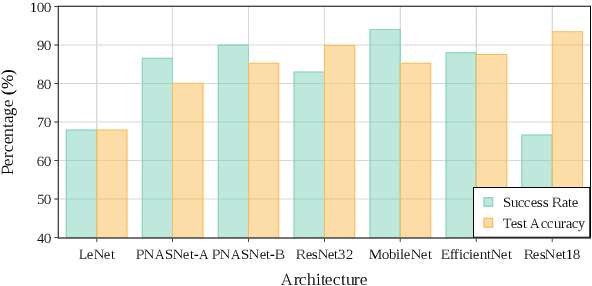
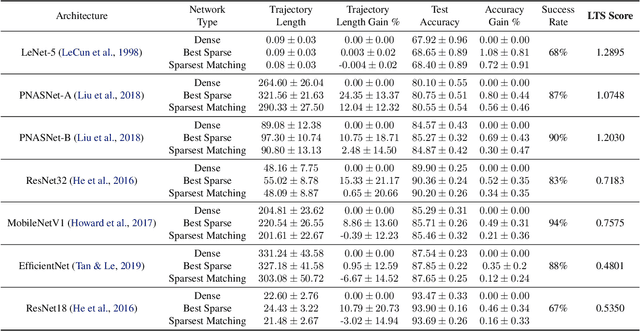
The Lottery Ticket Hypothesis (LTH) states that for a reasonably sized neural network, a sub-network within the same network yields no less performance than the dense counterpart when trained from the same initialization. This work investigates the relation between model size and the ease of finding these sparse sub-networks. We show through experiments that, surprisingly, under a finite budget, smaller models benefit more from Ticket Search (TS).
Global-Reasoned Multi-Task Learning Model for Surgical Scene Understanding
Jan 28, 2022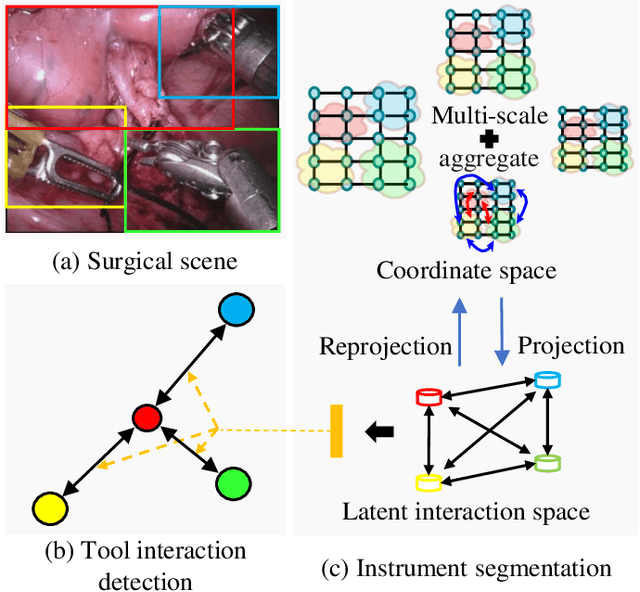
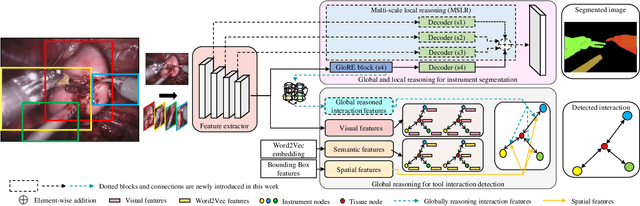
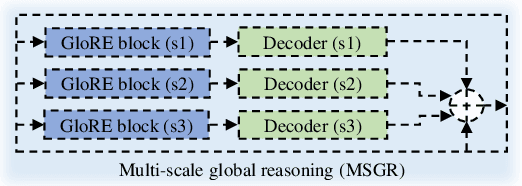
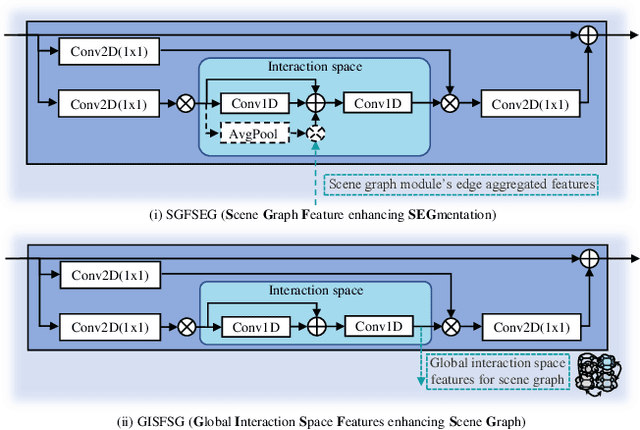
Global and local relational reasoning enable scene understanding models to perform human-like scene analysis and understanding. Scene understanding enables better semantic segmentation and object-to-object interaction detection. In the medical domain, a robust surgical scene understanding model allows the automation of surgical skill evaluation, real-time monitoring of surgeon's performance and post-surgical analysis. This paper introduces a globally-reasoned multi-task surgical scene understanding model capable of performing instrument segmentation and tool-tissue interaction detection. Here, we incorporate global relational reasoning in the latent interaction space and introduce multi-scale local (neighborhood) reasoning in the coordinate space to improve segmentation. Utilizing the multi-task model setup, the performance of the visual-semantic graph attention network in interaction detection is further enhanced through global reasoning. The global interaction space features from the segmentation module are introduced into the graph network, allowing it to detect interactions based on both node-to-node and global interaction reasoning. Our model reduces the computation cost compared to running two independent single-task models by sharing common modules, which is indispensable for practical applications. Using a sequential optimization technique, the proposed multi-task model outperforms other state-of-the-art single-task models on the MICCAI endoscopic vision challenge 2018 dataset. Additionally, we also observe the performance of the multi-task model when trained using the knowledge distillation technique. The official code implementation is made available in GitHub.
Audiomer: A Convolutional Transformer for Keyword Spotting
Sep 21, 2021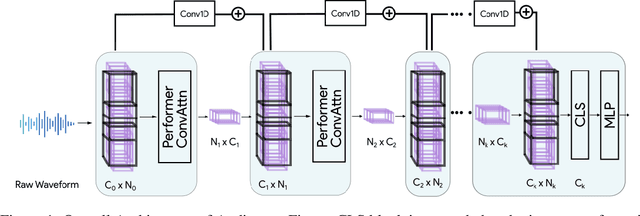

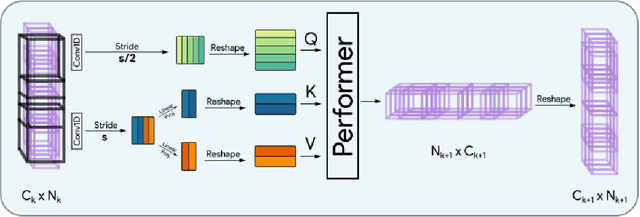
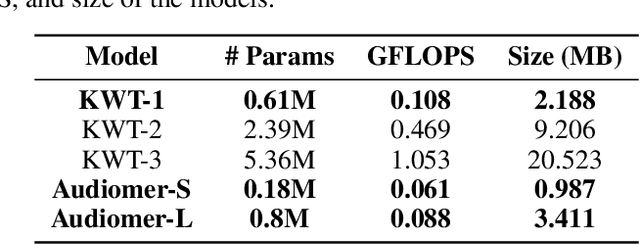
Transformers have seen an unprecedented rise in Natural Language Processing and Computer Vision tasks. However, in audio tasks, they are either infeasible to train due to extremely large sequence length of audio waveforms or reach competitive performance after feature extraction through Fourier-based methods, incurring a loss-floor. In this work, we introduce an architecture, Audiomer, where we combine 1D Residual Networks with Performer Attention to achieve state-of-the-art performance in Keyword Spotting with raw audio waveforms, out-performing all previous methods while also being computationally cheaper, much more parameter and data-efficient. Audiomer allows for deployment in compute-constrained devices and training on smaller datasets.
'CADSketchNet' -- An Annotated Sketch dataset for 3D CAD Model Retrieval with Deep Neural Networks
Jul 20, 2021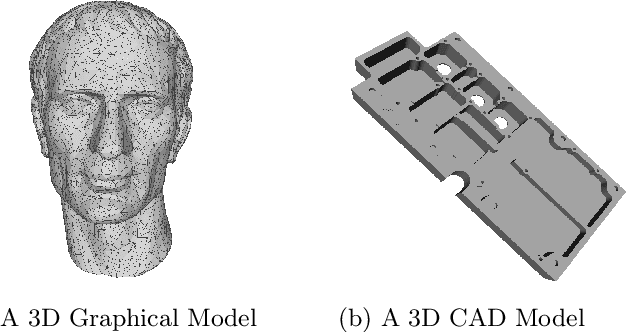

Ongoing advancements in the fields of 3D modelling and digital archiving have led to an outburst in the amount of data stored digitally. Consequently, several retrieval systems have been developed depending on the type of data stored in these databases. However, unlike text data or images, performing a search for 3D models is non-trivial. Among 3D models, retrieving 3D Engineering/CAD models or mechanical components is even more challenging due to the presence of holes, volumetric features, presence of sharp edges etc., which make CAD a domain unto itself. The research work presented in this paper aims at developing a dataset suitable for building a retrieval system for 3D CAD models based on deep learning. 3D CAD models from the available CAD databases are collected, and a dataset of computer-generated sketch data, termed 'CADSketchNet', has been prepared. Additionally, hand-drawn sketches of the components are also added to CADSketchNet. Using the sketch images from this dataset, the paper also aims at evaluating the performance of various retrieval system or a search engine for 3D CAD models that accepts a sketch image as the input query. Many experimental models are constructed and tested on CADSketchNet. These experiments, along with the model architecture, choice of similarity metrics are reported along with the search results.
* Computers & Graphics Journal, Special Section on 3DOR 2021
Improved Representation Learning for Session-based Recommendation
Jul 04, 2021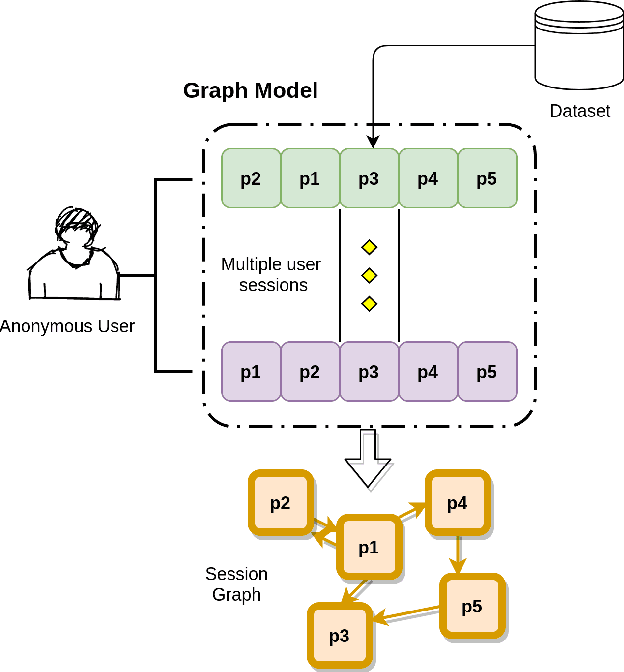

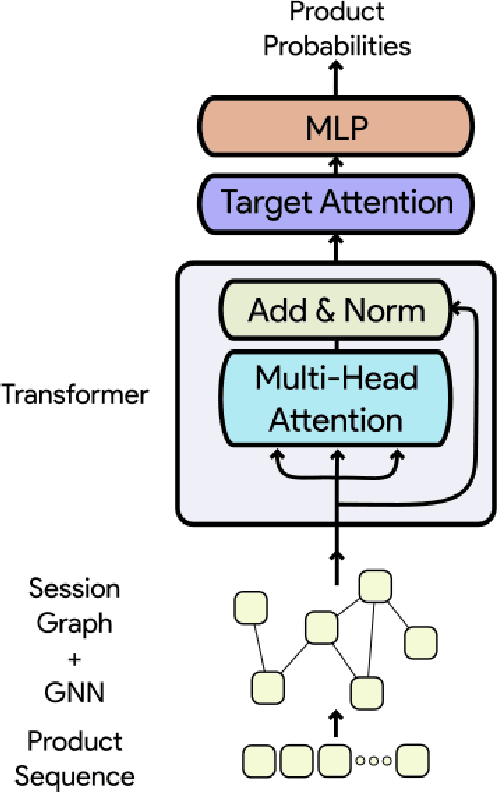
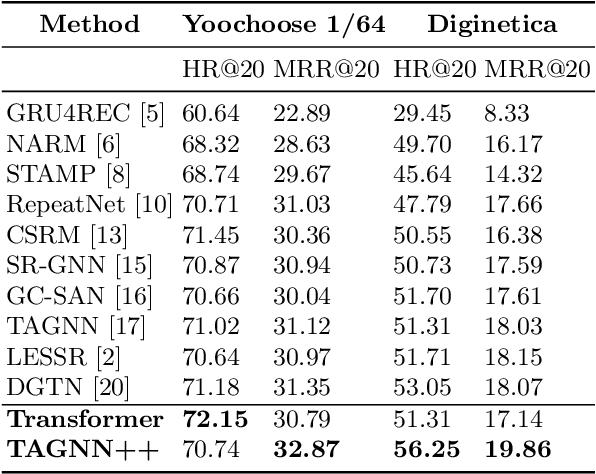
Session-based recommendation systems suggest relevant items to users by modeling user behavior and preferences using short-term anonymous sessions. Existing methods leverage Graph Neural Networks (GNNs) that propagate and aggregate information from neighboring nodes i.e., local message passing. Such graph-based architectures have representational limits, as a single sub-graph is susceptible to overfit the sequential dependencies instead of accounting for complex transitions between items in different sessions. We propose using a Transformer in combination with a target attentive GNN, which allows richer Representation Learning. Our experimental results and ablation show that our proposed method outperforms the existing methods on real-world benchmark datasets.