 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Reasoned Multi-Task Learning Model for Surgical Scene Understanding
Paper and Code
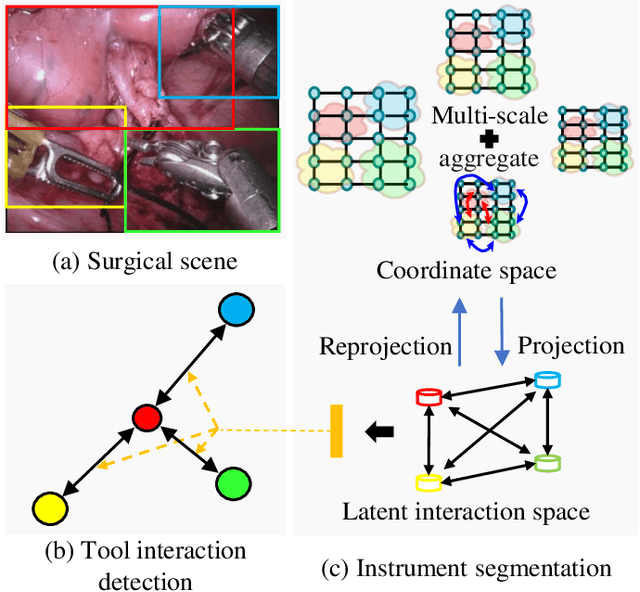
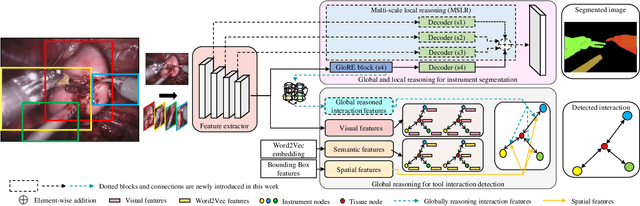
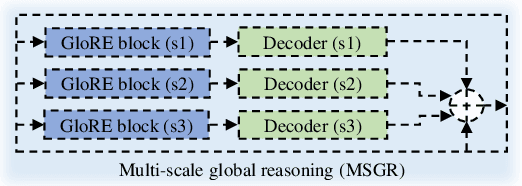
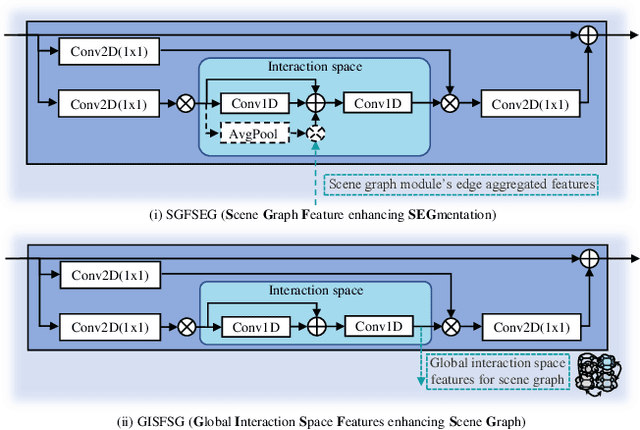
Global and local relational reasoning enable scene understanding models to perform human-like scene analysis and understanding. Scene understanding enables better semantic segmentation and object-to-object interaction detection. In the medical domain, a robust surgical scene understanding model allows the automation of surgical skill evaluation, real-time monitoring of surgeon's performance and post-surgical analysis. This paper introduces a globally-reasoned multi-task surgical scene understanding model capable of performing instrument segmentation and tool-tissue interaction detection. Here, we incorporate global relational reasoning in the latent interaction space and introduce multi-scale local (neighborhood) reasoning in the coordinate space to improve segmentation. Utilizing the multi-task model setup, the performance of the visual-semantic graph attention network in interaction detection is further enhanced through global reasoning. The global interaction space features from the segmentation module are introduced into the graph network, allowing it to detect interactions based on both node-to-node and global interaction reasoning. Our model reduces the computation cost compared to running two independent single-task models by sharing common modules, which is indispensable for practical applications. Using a sequential optimization technique, the proposed multi-task model outperforms other state-of-the-art single-task models on the MICCAI endoscopic vision challenge 2018 dataset. Additionally, we also observe the performance of the multi-task model when trained using the knowledge distillation technique. The official code implementation is made available in GitHub.