Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Lotteries Are Made Equal
Jun 16, 2022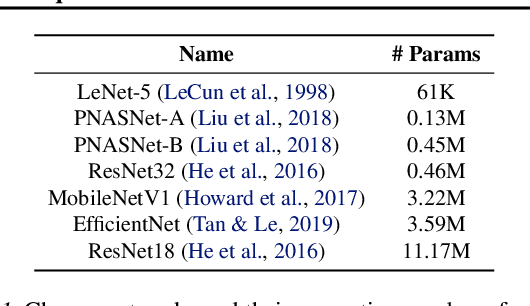

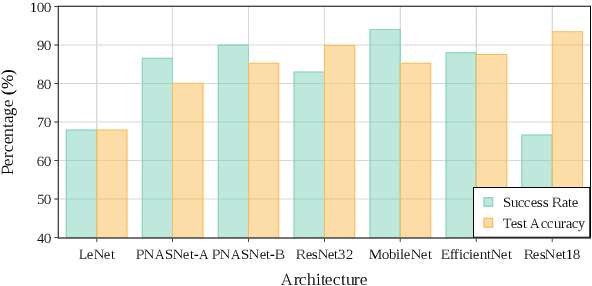
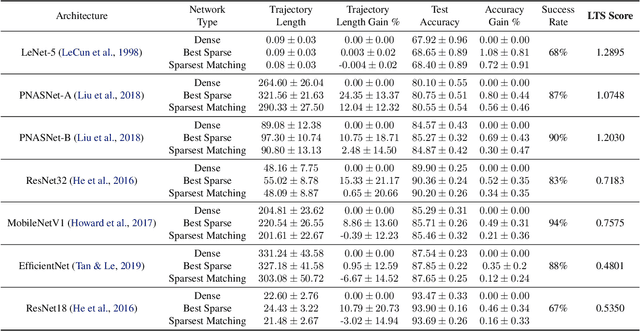
The Lottery Ticket Hypothesis (LTH) states that for a reasonably sized neural network, a sub-network within the same network yields no less performance than the dense counterpart when trained from the same initialization. This work investigates the relation between model size and the ease of finding these sparse sub-networks. We show through experiments that, surprisingly, under a finite budget, smaller models benefit more from Ticket Search (TS).
* Accepted at ICML 2022 HAET Workshop
Via