 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskMix: Data Augmentation for Meta-Learning of Spoken Intent Understanding
Paper and Code
Sep 26, 2022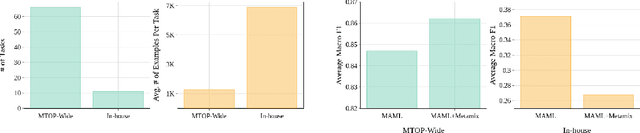
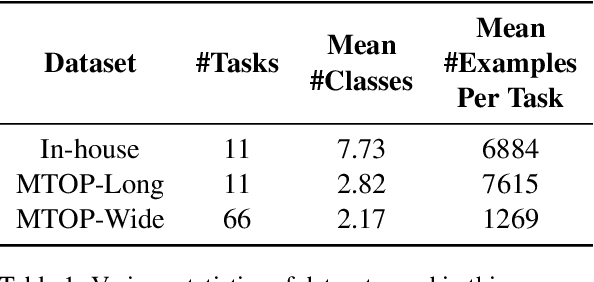
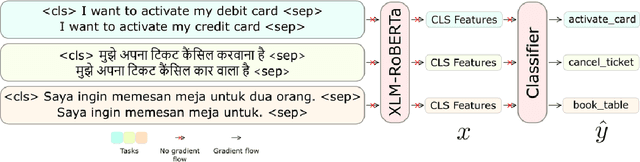
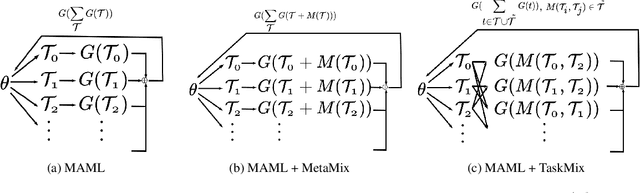
Meta-Learning has emerged as a research direction to better transfer knowledge from related tasks to unseen but related tasks. However, Meta-Learning requires many training tasks to learn representations that transfer well to unseen tasks; otherwise, it leads to overfitting, and the performance degenerates to worse than Multi-task Learning. We show that a state-of-the-art data augmentation method worsens this problem of overfitting when the task diversity is low. We propose a simple method, TaskMix, which synthesizes new tasks by linearly interpolating existing tasks. We compare TaskMix against many baselines on an in-house multilingual intent classification dataset of N-Best ASR hypotheses derived from real-life human-machine telephony utterances and two datasets derived from MTOP. We show that TaskMix outperforms baselines, alleviates overfitting when task diversity is low, and does not degrade performance even when it is high.