 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Domain-Specific Retrieval-Augmented Generation: Synthetic Data Generation and Evaluation using Reasoning Models
Feb 21, 2025



Retrieval-Augmented Generation (RAG) systems face significant performance gaps when applied to technical domains requiring precise information extraction from complex documents. Current evaluation methodologies relying on document-level metrics inadequately capture token-resolution retrieval accuracy that is critical for domain-related documents. We propose a framework combining granular evaluation metrics with synthetic data generation to optimize domain-specific RAG performance. First, we introduce token-aware metrics Precision $\Omega$ and Intersection-over-Union (IoU) that quantify context preservation versus information density trade-offs inherent in technical texts. Second, we develop a reasoning model-driven pipeline using instruction-tuned LLMs (DeepSeek-R1, DeepSeek-R1 distilled variants, and Phi-4) to generate context-anchored QA pairs with discontinuous reference spans across three specialized corpora: SEC 10-K filings (finance), biomedical abstracts (PubMed), and APT threat reports (cybersecurity). Our empirical analysis reveals critical insights: smaller chunks (less than 10 tokens) improve precision by 31-42% (IoU = 0.071 vs. baseline 0.053) at recall costs (-18%), while domain-specific embedding strategies yield 22% variance in optimal chunk sizing (5-20 tokens). The DeepSeek-R1-Distill-Qwen-32B model demonstrates superior concept alignment (+14% mean IoU over alternatives), though no configuration universally dominates. Financial texts favor larger chunks for risk factor coverage (Recall = 0.81 at size = 20), whereas cybersecurity content benefits from atomic segmentation, Precision $\Omega = 0.28$ at size = 5. Our code is available on https://github.com/aryan-jadon/Synthetic-Data-Generation-and-Evaluation-using-Reasoning-Model
On the limits of agency in agent-based models
Sep 14, 2024

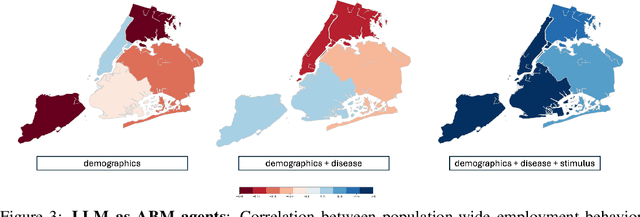
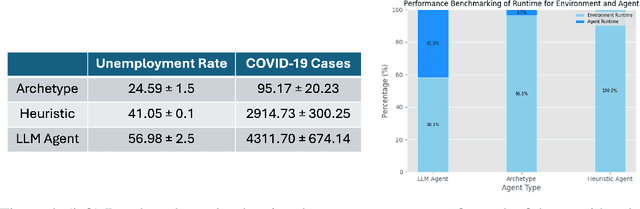
Agent-based modeling (ABM) seeks to understand the behavior of complex systems by simulating a collection of agents that act and interact within an environment. Their practical utility requires capturing realistic environment dynamics and adaptive agent behavior while efficiently simulating million-size populations. Recent advancements in large language models (LLMs) present an opportunity to enhance ABMs by using LLMs as agents with further potential to capture adaptive behavior. However, the computational infeasibility of using LLMs for large populations has hindered their widespread adoption. In this paper, we introduce AgentTorch -- a framework that scales ABMs to millions of agents while capturing high-resolution agent behavior using LLMs. We benchmark the utility of LLMs as ABM agents, exploring the trade-off between simulation scale and individual agency. Using the COVID-19 pandemic as a case study, we demonstrate how AgentTorch can simulate 8.4 million agents representing New York City, capturing the impact of isolation and employment behavior on health and economic outcomes. We compare the performance of different agent architectures based on heuristic and LLM agents in predicting disease waves and unemployment rates. Furthermore, we showcase AgentTorch's capabilities for retrospective, counterfactual, and prospective analyses, highlighting how adaptive agent behavior can help overcome the limitations of historical data in policy design. AgentTorch is an open-source project actively being used for policy-making and scientific discovery around the world. The framework is available here: github.com/AgentTorch/AgentTorch.
Leveraging Generative AI Models for Synthetic Data Generation in Healthcare: Balancing Research and Privacy
May 09, 2023


The widespread adoption of electronic health records and digital healthcare data has created a demand for data-driven insights to enhance patient outcomes, diagnostics, and treatments. However, using real patient data presents privacy and regulatory challenges, including compliance with HIPAA and GDPR. Synthetic data generation, using generative AI models like GANs and VAEs offers a promising solution to balance valuable data access and patient privacy protection. In this paper, we examine generative AI models for creating realistic, anonymized patient data for research and training, explore synthetic data applications in healthcare, and discuss its benefits, challenges, and future research directions. Synthetic data has the potential to revolutionize healthcare by providing anonymized patient data while preserving privacy and enabling versatile applications.
Imaging through fog using quadrature lock-in discrimination
May 17, 2021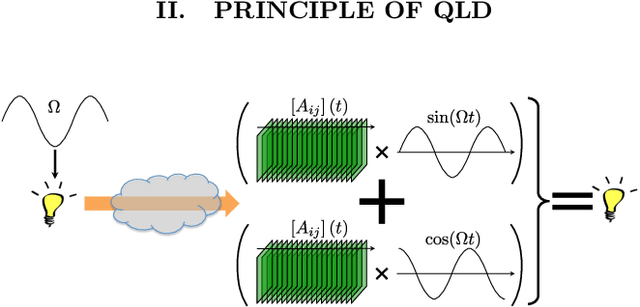

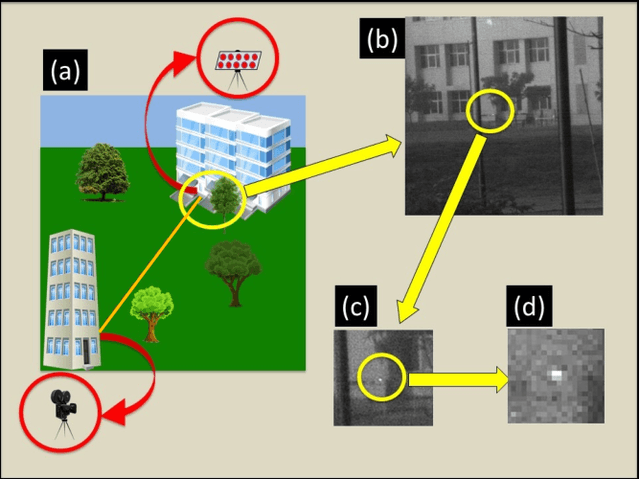
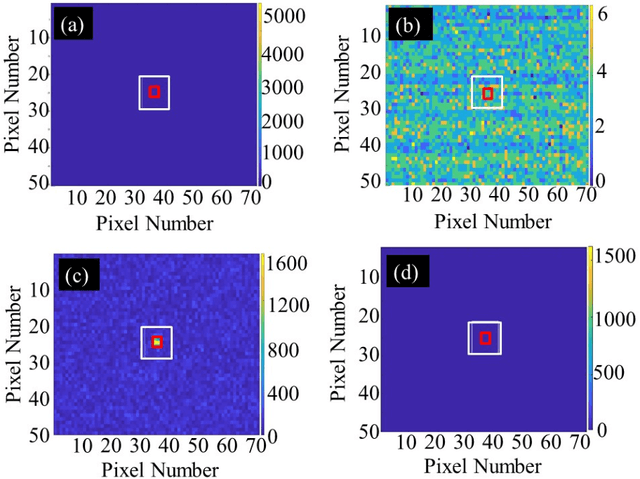
We report experiments conducted in the field in the presence of fog, that were aimed at imaging under poor visibility. By means of intensity modulation at the source and two-dimensional quadrature lock-in detection by software at the receiver, a significant enhancement of the contrast-to-noise ratio was achieved in the imaging of beacons over hectometric distances. Further by illuminating the field of view with a modulated source, the technique helped reveal objects that were earlier obscured due to multiple scattering of light. This method, thus, holds promise of aiding in various forms of navigation under poor visibility due to fog.