 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Domain-Specific Retrieval-Augmented Generation: Synthetic Data Generation and Evaluation using Reasoning Models
Feb 21, 2025



Retrieval-Augmented Generation (RAG) systems face significant performance gaps when applied to technical domains requiring precise information extraction from complex documents. Current evaluation methodologies relying on document-level metrics inadequately capture token-resolution retrieval accuracy that is critical for domain-related documents. We propose a framework combining granular evaluation metrics with synthetic data generation to optimize domain-specific RAG performance. First, we introduce token-aware metrics Precision $\Omega$ and Intersection-over-Union (IoU) that quantify context preservation versus information density trade-offs inherent in technical texts. Second, we develop a reasoning model-driven pipeline using instruction-tuned LLMs (DeepSeek-R1, DeepSeek-R1 distilled variants, and Phi-4) to generate context-anchored QA pairs with discontinuous reference spans across three specialized corpora: SEC 10-K filings (finance), biomedical abstracts (PubMed), and APT threat reports (cybersecurity). Our empirical analysis reveals critical insights: smaller chunks (less than 10 tokens) improve precision by 31-42% (IoU = 0.071 vs. baseline 0.053) at recall costs (-18%), while domain-specific embedding strategies yield 22% variance in optimal chunk sizing (5-20 tokens). The DeepSeek-R1-Distill-Qwen-32B model demonstrates superior concept alignment (+14% mean IoU over alternatives), though no configuration universally dominates. Financial texts favor larger chunks for risk factor coverage (Recall = 0.81 at size = 20), whereas cybersecurity content benefits from atomic segmentation, Precision $\Omega = 0.28$ at size = 5. Our code is available on https://github.com/aryan-jadon/Synthetic-Data-Generation-and-Evaluation-using-Reasoning-Model
English Please: Evaluating Machine Translation for Multilingual Bug Reports
Feb 20, 2025



Accurate translation of bug reports is critical for efficient collaboration in global software development. In this study, we conduct the first comprehensive evaluation of machine translation (MT) performance on bug reports, analyzing the capabilities of DeepL, AWS Translate, and ChatGPT using data from the Visual Studio Code GitHub repository, specifically focusing on reports labeled with the english-please tag. To thoroughly assess the accuracy and effectiveness of each system, we employ multiple machine translation metrics, including BLEU, BERTScore, COMET, METEOR, and ROUGE. Our findings indicate that DeepL consistently outperforms the other systems across most automatic metrics, demonstrating strong lexical and semantic alignment. AWS Translate performs competitively, particularly in METEOR, while ChatGPT lags in key metrics. This study underscores the importance of domain adaptation for translating technical texts and offers guidance for integrating automated translation into bug-triaging workflows. Moreover, our results establish a foundation for future research to refine machine translation solutions for specialized engineering contexts. The code and dataset for this paper are available at GitHub: https://github.com/av9ash/gitbugs/tree/main/multilingual.
A Comprehensive Survey of Evaluation Techniques for Recommendation Systems
Jan 12, 2024The effectiveness of recommendation systems is pivotal to user engagement and satisfaction in online platforms. As these recommendation systems increasingly influence user choices, their evaluation transcends mere technical performance and becomes central to business success. This paper addresses the multifaceted nature of recommendations system evaluation by introducing a comprehensive suite of metrics, each tailored to capture a distinct aspect of system performance. We discuss * Similarity Metrics: to quantify the precision of content-based filtering mechanisms and assess the accuracy of collaborative filtering techniques. * Candidate Generation Metrics: to evaluate how effectively the system identifies a broad yet relevant range of items. * Predictive Metrics: to assess the accuracy of forecasted user preferences. * Ranking Metrics: to evaluate the effectiveness of the order in which recommendations are presented. * Business Metrics: to align the performance of the recommendation system with economic objectives. Our approach emphasizes the contextual application of these metrics and their interdependencies. In this paper, we identify the strengths and limitations of current evaluation practices and highlight the nuanced trade-offs that emerge when optimizing recommendation systems across different metrics. The paper concludes by proposing a framework for selecting and interpreting these metrics to not only improve system performance but also to advance business goals. This work is to aid researchers and practitioners in critically assessing recommendation systems and fosters the development of more nuanced, effective, and economically viable personalization strategies. Our code is available at GitHub - https://github.com/aryan-jadon/Evaluation-Metrics-for-Recommendation-Systems.
Leveraging Generative AI Models for Synthetic Data Generation in Healthcare: Balancing Research and Privacy
May 09, 2023


The widespread adoption of electronic health records and digital healthcare data has created a demand for data-driven insights to enhance patient outcomes, diagnostics, and treatments. However, using real patient data presents privacy and regulatory challenges, including compliance with HIPAA and GDPR. Synthetic data generation, using generative AI models like GANs and VAEs offers a promising solution to balance valuable data access and patient privacy protection. In this paper, we examine generative AI models for creating realistic, anonymized patient data for research and training, explore synthetic data applications in healthcare, and discuss its benefits, challenges, and future research directions. Synthetic data has the potential to revolutionize healthcare by providing anonymized patient data while preserving privacy and enabling versatile applications.
Auto-labelling of Bug Report using Natural Language Processing
Dec 13, 2022


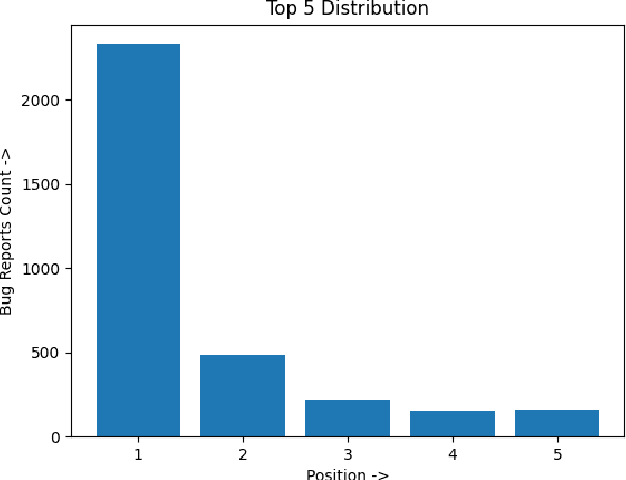
The exercise of detecting similar bug reports in bug tracking systems is known as duplicate bug report detection. Having prior knowledge of a bug report's existence reduces efforts put into debugging problems and identifying the root cause. Rule and Query-based solutions recommend a long list of potential similar bug reports with no clear ranking. In addition, triage engineers are less motivated to spend time going through an extensive list. Consequently, this deters the use of duplicate bug report retrieval solutions. In this paper, we have proposed a solution using a combination of NLP techniques. Our approach considers unstructured and structured attributes of a bug report like summary, description and severity, impacted products, platforms, categories, etc. It uses a custom data transformer, a deep neural network, and a non-generalizing machine learning method to retrieve existing identical bug reports. We have performed numerous experiments with significant data sources containing thousands of bug reports and showcased that the proposed solution achieves a high retrieval accuracy of 70% for recall@5.
A Comprehensive Survey of Regression Based Loss Functions for Time Series Forecasting
Nov 05, 2022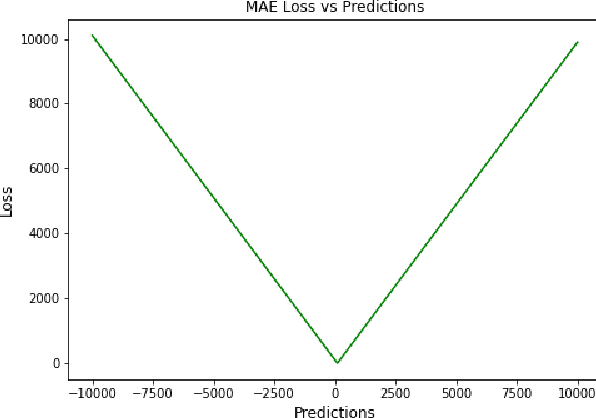
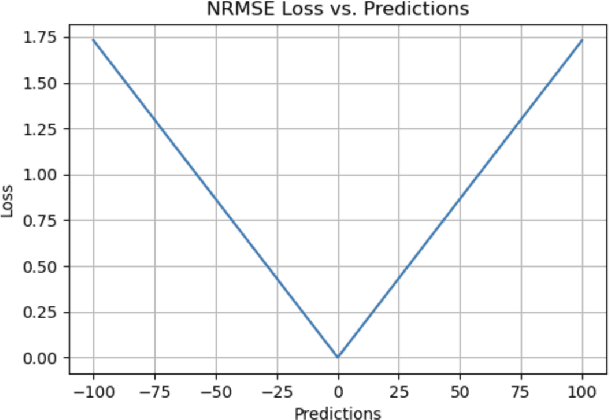
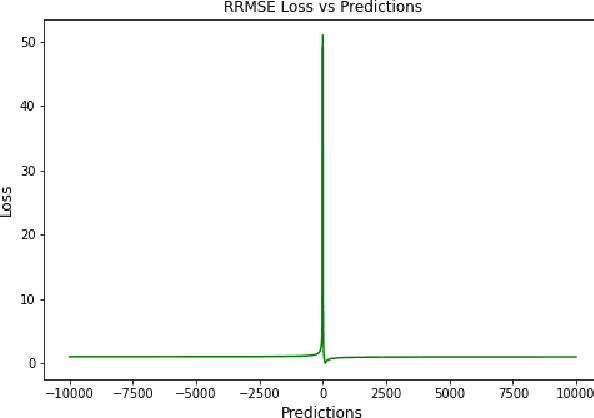
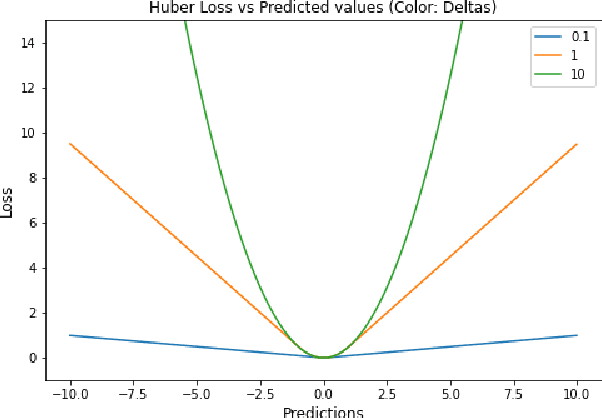
Time Series Forecasting has been an active area of research due to its many applications ranging from network usage prediction, resource allocation, anomaly detection, and predictive maintenance. Numerous publications published in the last five years have proposed diverse sets of objective loss functions to address cases such as biased data, long-term forecasting, multicollinear features, etc. In this paper, we have summarized 14 well-known regression loss functions commonly used for time series forecasting and listed out the circumstances where their application can aid in faster and better model convergence. We have also demonstrated how certain categories of loss functions perform well across all data sets and can be considered as a baseline objective function in circumstances where the distribution of the data is unknown. Our code is available at GitHub: https://github.com/aryan-jadon/Regression-Loss-Functions-in-Time-Series-Forecasting-Tensorflow.