 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Bugs Linger: A Study of Anomalous Resolution Time Outliers and Their Themes
Sep 19, 2025Efficient bug resolution is critical for maintaining software quality and user satisfaction. However, specific bug reports experience unusually long resolution times, which may indicate underlying process inefficiencies or complex issues. This study presents a comprehensive analysis of bug resolution anomalies across seven prominent open-source repositories: Cassandra, Firefox, Hadoop, HBase, SeaMonkey, Spark, and Thunderbird. Utilizing statistical methods such as Z-score and Interquartile Range (IQR), we identify anomalies in bug resolution durations. To understand the thematic nature of these anomalies, we apply Term Frequency-Inverse Document Frequency (TF-IDF) for textual feature extraction and KMeans clustering to group similar bug summaries. Our findings reveal consistent patterns across projects, with anomalies often clustering around test failures, enhancement requests, and user interface issues. This approach provides actionable insights for project maintainers to prioritize and effectively address long-standing bugs.
Advancing Software Quality: A Standards-Focused Review of LLM-Based Assurance Techniques
May 19, 2025Software Quality Assurance (SQA) is critical for delivering reliable, secure, and efficient software products. The Software Quality Assurance Process aims to provide assurance that work products and processes comply with predefined provisions and plans. Recent advancements in Large Language Models (LLMs) present new opportunities to enhance existing SQA processes by automating tasks like requirement analysis, code review, test generation, and compliance checks. Simultaneously, established standards such as ISO/IEC 12207, ISO/IEC 25010, ISO/IEC 5055, ISO 9001/ISO/IEC 90003, CMMI, and TMM provide structured frameworks for ensuring robust quality practices. This paper surveys the intersection of LLM-based SQA methods and these recognized standards, highlighting how AI-driven solutions can augment traditional approaches while maintaining compliance and process maturity. We first review the foundational software quality standards and the technical fundamentals of LLMs in software engineering. Next, we explore various LLM-based SQA applications, including requirement validation, defect detection, test generation, and documentation maintenance. We then map these applications to key software quality frameworks, illustrating how LLMs can address specific requirements and metrics within each standard. Empirical case studies and open-source initiatives demonstrate the practical viability of these methods. At the same time, discussions on challenges (e.g., data privacy, model bias, explainability) underscore the need for deliberate governance and auditing. Finally, we propose future directions encompassing adaptive learning, privacy-focused deployments, multimodal analysis, and evolving standards for AI-driven software quality.
Cognitive-Mental-LLM: Leveraging Reasoning in Large Language Models for Mental Health Prediction via Online Text
Mar 13, 2025Large Language Models (LLMs) have demonstrated potential in predicting mental health outcomes from online text, yet traditional classification methods often lack interpretability and robustness. This study evaluates structured reasoning techniques-Chain-of-Thought (CoT), Self-Consistency (SC-CoT), and Tree-of-Thought (ToT)-to improve classification accuracy across multiple mental health datasets sourced from Reddit. We analyze reasoning-driven prompting strategies, including Zero-shot CoT and Few-shot CoT, using key performance metrics such as Balanced Accuracy, F1 score, and Sensitivity/Specificity. Our findings indicate that reasoning-enhanced techniques improve classification performance over direct prediction, particularly in complex cases. Compared to baselines such as Zero Shot non-CoT Prompting, and fine-tuned pre-trained transformers such as BERT and Mental-RoBerta, and fine-tuned Open Source LLMs such as Mental Alpaca and Mental-Flan-T5, reasoning-driven LLMs yield notable gains on datasets like Dreaddit (+0.52\% over M-LLM, +0.82\% over BERT) and SDCNL (+4.67\% over M-LLM, +2.17\% over BERT). However, performance declines in Depression Severity, and CSSRS predictions suggest dataset-specific limitations, likely due to our using a more extensive test set. Among prompting strategies, Few-shot CoT consistently outperforms others, reinforcing the effectiveness of reasoning-driven LLMs. Nonetheless, dataset variability highlights challenges in model reliability and interpretability. This study provides a comprehensive benchmark of reasoning-based LLM techniques for mental health text classification. It offers insights into their potential for scalable clinical applications while identifying key challenges for future improvements.
Enhancing Domain-Specific Retrieval-Augmented Generation: Synthetic Data Generation and Evaluation using Reasoning Models
Feb 21, 2025



Retrieval-Augmented Generation (RAG) systems face significant performance gaps when applied to technical domains requiring precise information extraction from complex documents. Current evaluation methodologies relying on document-level metrics inadequately capture token-resolution retrieval accuracy that is critical for domain-related documents. We propose a framework combining granular evaluation metrics with synthetic data generation to optimize domain-specific RAG performance. First, we introduce token-aware metrics Precision $\Omega$ and Intersection-over-Union (IoU) that quantify context preservation versus information density trade-offs inherent in technical texts. Second, we develop a reasoning model-driven pipeline using instruction-tuned LLMs (DeepSeek-R1, DeepSeek-R1 distilled variants, and Phi-4) to generate context-anchored QA pairs with discontinuous reference spans across three specialized corpora: SEC 10-K filings (finance), biomedical abstracts (PubMed), and APT threat reports (cybersecurity). Our empirical analysis reveals critical insights: smaller chunks (less than 10 tokens) improve precision by 31-42% (IoU = 0.071 vs. baseline 0.053) at recall costs (-18%), while domain-specific embedding strategies yield 22% variance in optimal chunk sizing (5-20 tokens). The DeepSeek-R1-Distill-Qwen-32B model demonstrates superior concept alignment (+14% mean IoU over alternatives), though no configuration universally dominates. Financial texts favor larger chunks for risk factor coverage (Recall = 0.81 at size = 20), whereas cybersecurity content benefits from atomic segmentation, Precision $\Omega = 0.28$ at size = 5. Our code is available on https://github.com/aryan-jadon/Synthetic-Data-Generation-and-Evaluation-using-Reasoning-Model
English Please: Evaluating Machine Translation for Multilingual Bug Reports
Feb 20, 2025



Accurate translation of bug reports is critical for efficient collaboration in global software development. In this study, we conduct the first comprehensive evaluation of machine translation (MT) performance on bug reports, analyzing the capabilities of DeepL, AWS Translate, and ChatGPT using data from the Visual Studio Code GitHub repository, specifically focusing on reports labeled with the english-please tag. To thoroughly assess the accuracy and effectiveness of each system, we employ multiple machine translation metrics, including BLEU, BERTScore, COMET, METEOR, and ROUGE. Our findings indicate that DeepL consistently outperforms the other systems across most automatic metrics, demonstrating strong lexical and semantic alignment. AWS Translate performs competitively, particularly in METEOR, while ChatGPT lags in key metrics. This study underscores the importance of domain adaptation for translating technical texts and offers guidance for integrating automated translation into bug-triaging workflows. Moreover, our results establish a foundation for future research to refine machine translation solutions for specialized engineering contexts. The code and dataset for this paper are available at GitHub: https://github.com/av9ash/gitbugs/tree/main/multilingual.
Advancing Reasoning in Large Language Models: Promising Methods and Approaches
Feb 05, 2025


Large Language Models (LLMs) have succeeded remarkably in various natural language processing (NLP) tasks, yet their reasoning capabilities remain a fundamental challenge. While LLMs exhibit impressive fluency and factual recall, their ability to perform complex reasoning-spanning logical deduction, mathematical problem-solving, commonsense inference, and multi-step reasoning-often falls short of human expectations. This survey provides a comprehensive review of emerging techniques enhancing reasoning in LLMs. We categorize existing methods into key approaches, including prompting strategies (e.g., Chain-of-Thought reasoning, Self-Consistency, and Tree-of-Thought reasoning), architectural innovations (e.g., retrieval-augmented models, modular reasoning networks, and neuro-symbolic integration), and learning paradigms (e.g., fine-tuning with reasoning-specific datasets, reinforcement learning, and self-supervised reasoning objectives). Additionally, we explore evaluation frameworks used to assess reasoning in LLMs and highlight open challenges, such as hallucinations, robustness, and reasoning generalization across diverse tasks. By synthesizing recent advancements, this survey aims to provide insights into promising directions for future research and practical applications of reasoning-augmented LLMs.
A Comprehensive Survey of Evaluation Techniques for Recommendation Systems
Jan 12, 2024The effectiveness of recommendation systems is pivotal to user engagement and satisfaction in online platforms. As these recommendation systems increasingly influence user choices, their evaluation transcends mere technical performance and becomes central to business success. This paper addresses the multifaceted nature of recommendations system evaluation by introducing a comprehensive suite of metrics, each tailored to capture a distinct aspect of system performance. We discuss * Similarity Metrics: to quantify the precision of content-based filtering mechanisms and assess the accuracy of collaborative filtering techniques. * Candidate Generation Metrics: to evaluate how effectively the system identifies a broad yet relevant range of items. * Predictive Metrics: to assess the accuracy of forecasted user preferences. * Ranking Metrics: to evaluate the effectiveness of the order in which recommendations are presented. * Business Metrics: to align the performance of the recommendation system with economic objectives. Our approach emphasizes the contextual application of these metrics and their interdependencies. In this paper, we identify the strengths and limitations of current evaluation practices and highlight the nuanced trade-offs that emerge when optimizing recommendation systems across different metrics. The paper concludes by proposing a framework for selecting and interpreting these metrics to not only improve system performance but also to advance business goals. This work is to aid researchers and practitioners in critically assessing recommendation systems and fosters the development of more nuanced, effective, and economically viable personalization strategies. Our code is available at GitHub - https://github.com/aryan-jadon/Evaluation-Metrics-for-Recommendation-Systems.
A Comparative Study of Text Embedding Models for Semantic Text Similarity in Bug Reports
Aug 17, 2023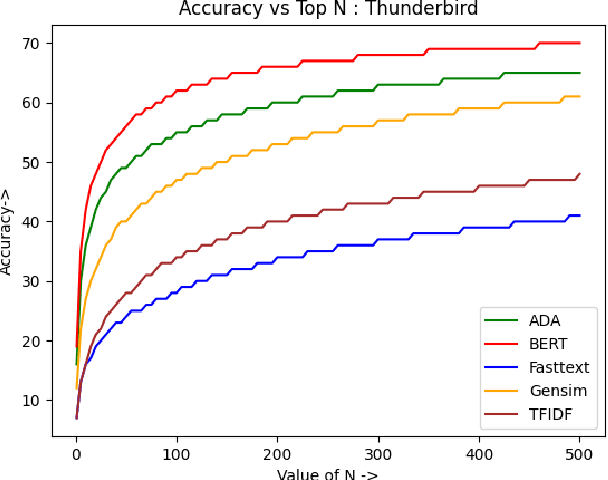
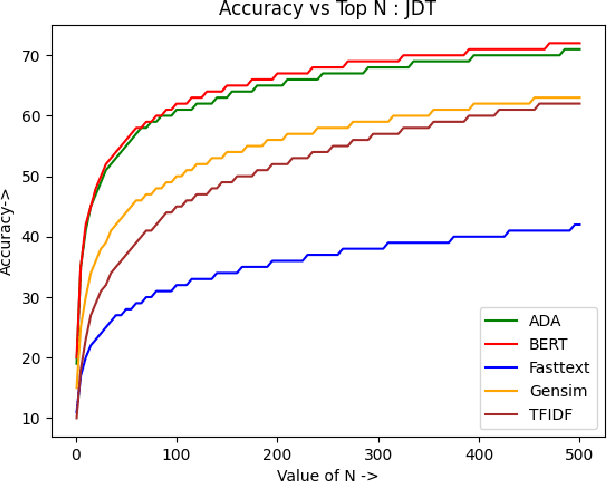
Bug reports are an essential aspect of software development, and it is crucial to identify and resolve them quickly to ensure the consistent functioning of software systems. Retrieving similar bug reports from an existing database can help reduce the time and effort required to resolve bugs. In this paper, we compared the effectiveness of semantic textual similarity methods for retrieving similar bug reports based on a similarity score. We explored several embedding models such as TF-IDF (Baseline), FastText, Gensim, BERT, and ADA. We used the Software Defects Data containing bug reports for various software projects to evaluate the performance of these models. Our experimental results showed that BERT generally outperformed the rest of the models regarding recall, followed by ADA, Gensim, FastText, and TFIDF. Our study provides insights into the effectiveness of different embedding methods for retrieving similar bug reports and highlights the impact of selecting the appropriate one for this task. Our code is available on GitHub.
Auto-labelling of Bug Report using Natural Language Processing
Dec 13, 2022


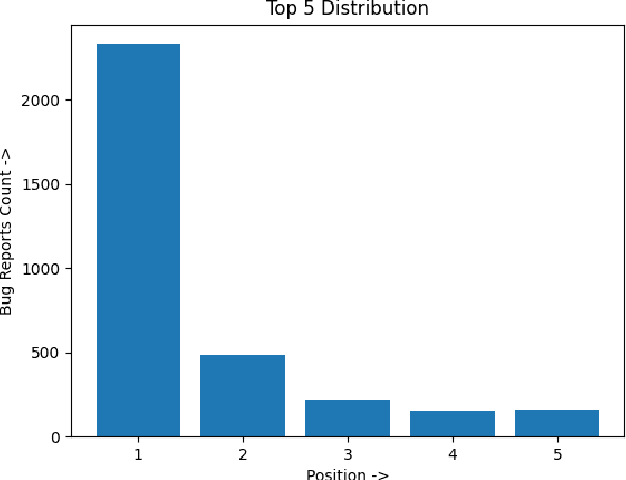
The exercise of detecting similar bug reports in bug tracking systems is known as duplicate bug report detection. Having prior knowledge of a bug report's existence reduces efforts put into debugging problems and identifying the root cause. Rule and Query-based solutions recommend a long list of potential similar bug reports with no clear ranking. In addition, triage engineers are less motivated to spend time going through an extensive list. Consequently, this deters the use of duplicate bug report retrieval solutions. In this paper, we have proposed a solution using a combination of NLP techniques. Our approach considers unstructured and structured attributes of a bug report like summary, description and severity, impacted products, platforms, categories, etc. It uses a custom data transformer, a deep neural network, and a non-generalizing machine learning method to retrieve existing identical bug reports. We have performed numerous experiments with significant data sources containing thousands of bug reports and showcased that the proposed solution achieves a high retrieval accuracy of 70% for recall@5.
A Comprehensive Survey of Regression Based Loss Functions for Time Series Forecasting
Nov 05, 2022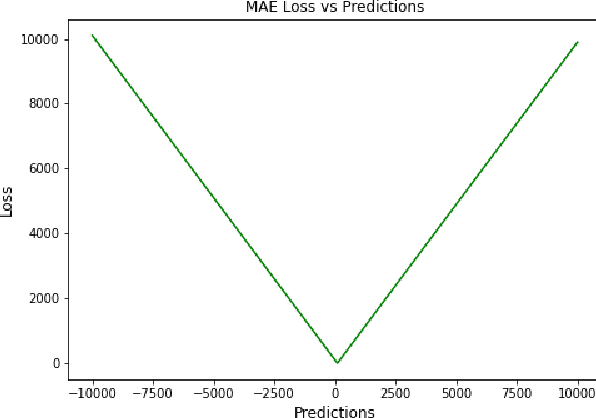
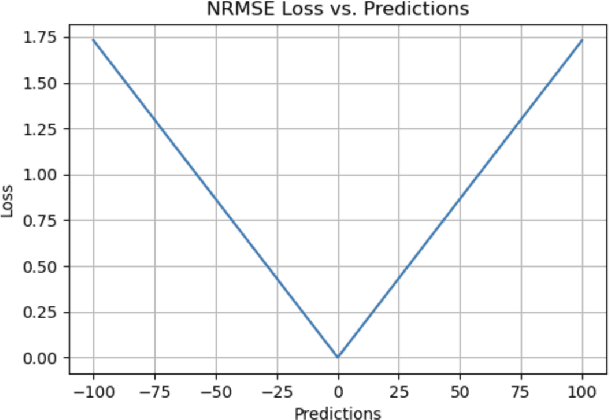
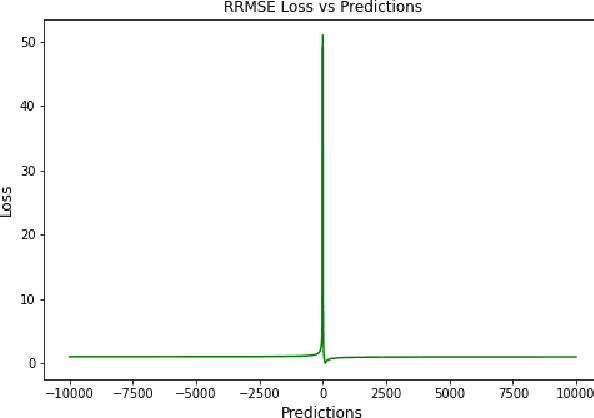
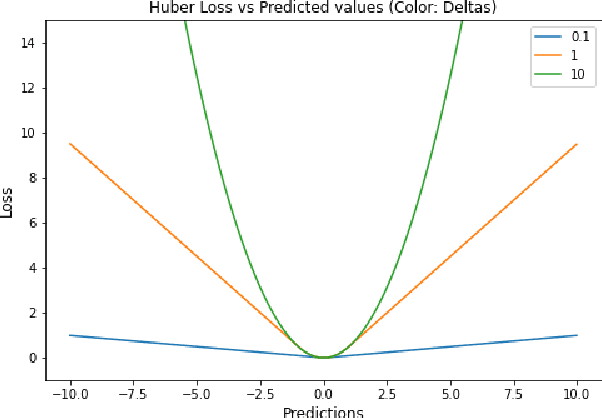
Time Series Forecasting has been an active area of research due to its many applications ranging from network usage prediction, resource allocation, anomaly detection, and predictive maintenance. Numerous publications published in the last five years have proposed diverse sets of objective loss functions to address cases such as biased data, long-term forecasting, multicollinear features, etc. In this paper, we have summarized 14 well-known regression loss functions commonly used for time series forecasting and listed out the circumstances where their application can aid in faster and better model convergence. We have also demonstrated how certain categories of loss functions perform well across all data sets and can be considered as a baseline objective function in circumstances where the distribution of the data is unknown. Our code is available at GitHub: https://github.com/aryan-jadon/Regression-Loss-Functions-in-Time-Series-Forecasting-Tensorflow.