 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Regression Based Loss Functions for Time Series Forecasting
Nov 05, 2022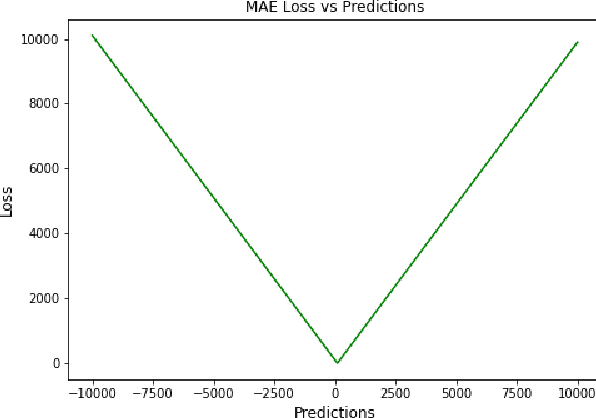
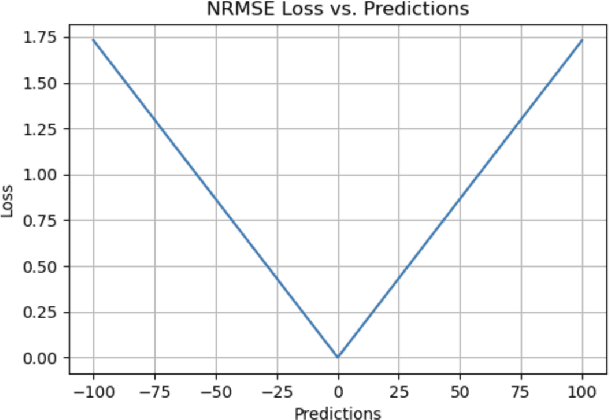
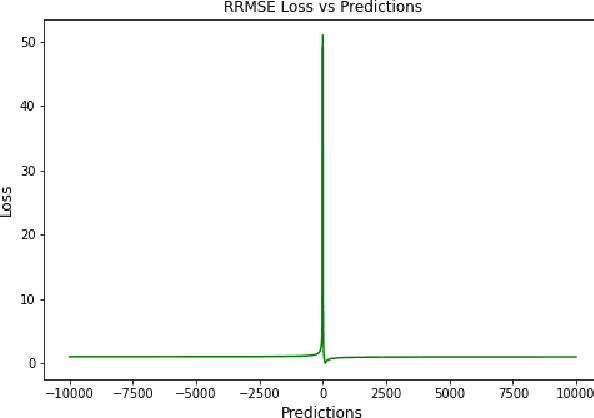
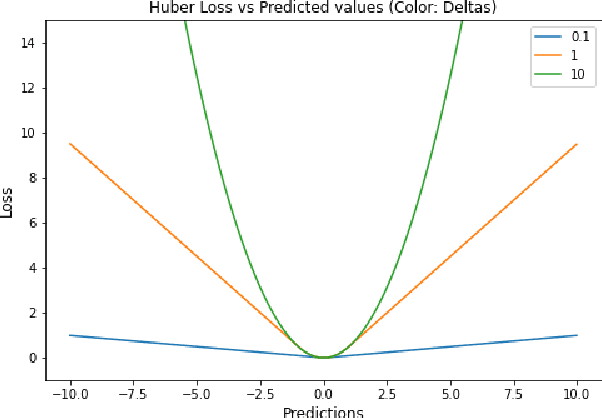
Time Series Forecasting has been an active area of research due to its many applications ranging from network usage prediction, resource allocation, anomaly detection, and predictive maintenance. Numerous publications published in the last five years have proposed diverse sets of objective loss functions to address cases such as biased data, long-term forecasting, multicollinear features, etc. In this paper, we have summarized 14 well-known regression loss functions commonly used for time series forecasting and listed out the circumstances where their application can aid in faster and better model convergence. We have also demonstrated how certain categories of loss functions perform well across all data sets and can be considered as a baseline objective function in circumstances where the distribution of the data is unknown. Our code is available at GitHub: https://github.com/aryan-jadon/Regression-Loss-Functions-in-Time-Series-Forecasting-Tensorflow.
SemSegLoss: A python package of loss functions for semantic segmentation
May 18, 2021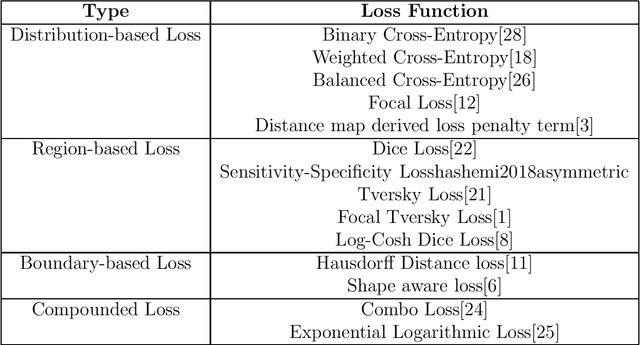
Image Segmentation has been an active field of research as it has a wide range of applications, ranging from automated disease detection to self-driving cars. In recent years, various research papers proposed different loss functions used in case of biased data, sparse segmentation, and unbalanced dataset. In this paper, we introduce SemSegLoss, a python package consisting of some of the well-known loss functions widely used for image segmentation. It is developed with the intent to help researchers in the development of novel loss functions and perform an extensive set of experiments on model architectures for various applications. The ease-of-use and flexibility of the presented package have allowed reducing the development time and increased evaluation strategies of machine learning models for semantic segmentation. Furthermore, different applications that use image segmentation can use SemSegLoss because of the generality of its functions. This wide range of applications will lead to the development and growth of AI across all industries.
COVID-19 detection from scarce chest x-ray image data using few-shot deep learning approach
Mar 01, 2021
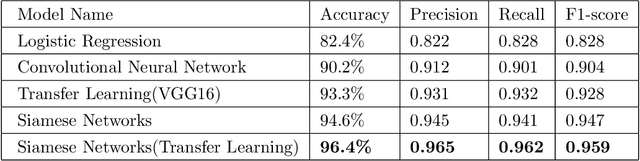

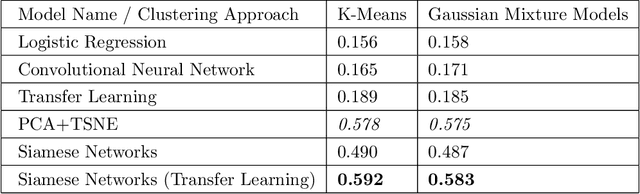
In the current COVID-19 pandemic situation, there is an urgent need to screen infected patients quickly and accurately. Using deep learning models trained on chest X-ray images can become an efficient method for screening COVID-19 patients in these situations. Deep learning approaches are already widely used in the medical community. However, they require a large amount of data to be accurate. The open-source community collectively has made efforts to collect and annotate the data, but it is not enough to train an accurate deep learning model. Few-shot learning is a sub-field of machine learning that aims to learn the objective with less amount of data. In this work, we have experimented with well-known solutions for data scarcity in deep learning to detect COVID-19. These include data augmentation, transfer learning, and few-shot learning, and unsupervised learning. We have also proposed a custom few-shot learning approach to detect COVID-19 using siamese networks. Our experimental results showcased that we can implement an efficient and accurate deep learning model for COVID-19 detection by adopting the few-shot learning approaches even with less amount of data. Using our proposed approach we were able to achieve 96.4% accuracy an improvement from 83% using baseline models.
Challenges and approaches to time-series forecasting in data center telemetry: A Survey
Feb 11, 2021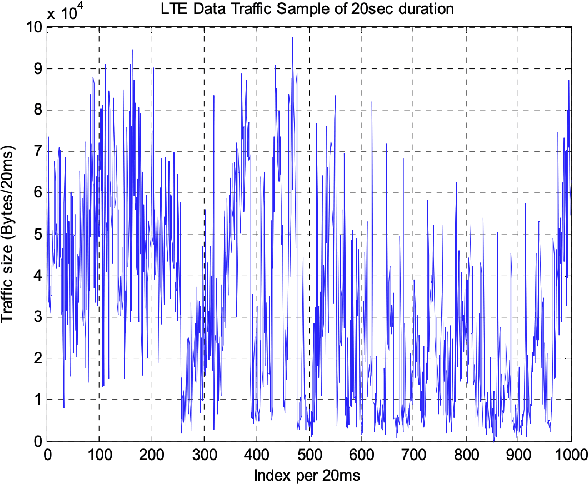
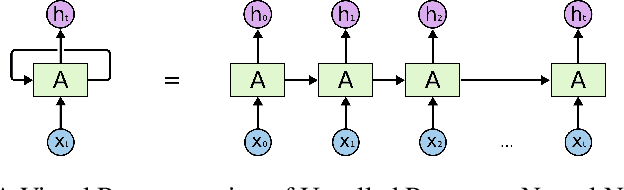
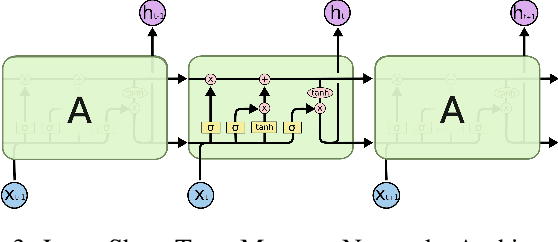
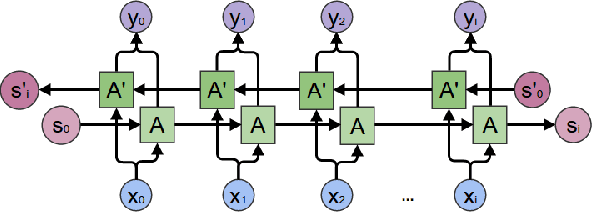
Time-series forecasting has been an important research domain for so many years. Its applications include ECG predictions, sales forecasting, weather conditions, even COVID-19 spread predictions. These applications have motivated many researchers to figure out an optimal forecasting approach, but the modeling approach also changes as the application domain changes. This work has focused on reviewing different forecasting approaches for telemetry data predictions collected at data centers. Forecasting of telemetry data is a critical feature of network and data center management products. However, there are multiple options of forecasting approaches that range from a simple linear statistical model to high capacity deep learning architectures. In this paper, we attempted to summarize and evaluate the performance of well known time series forecasting techniques. We hope that this evaluation provides a comprehensive summary to innovate in forecasting approaches for telemetry data.
An Overview of Deep Learning Architectures in Few-Shot Learning Domain
Aug 19, 2020
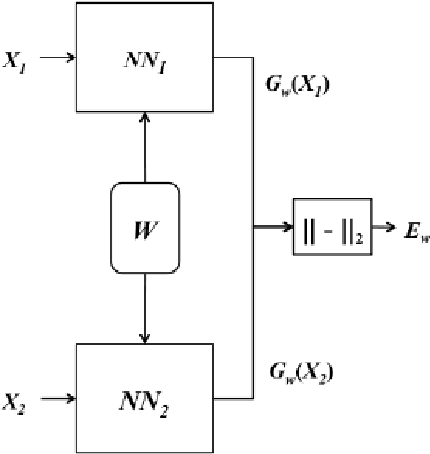
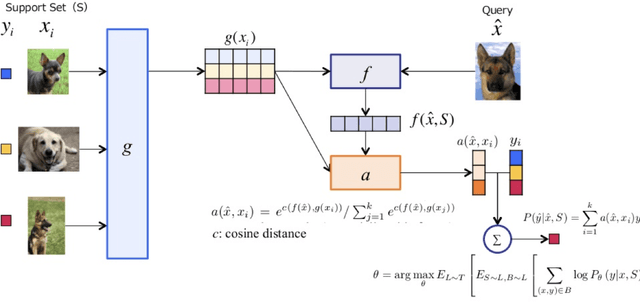
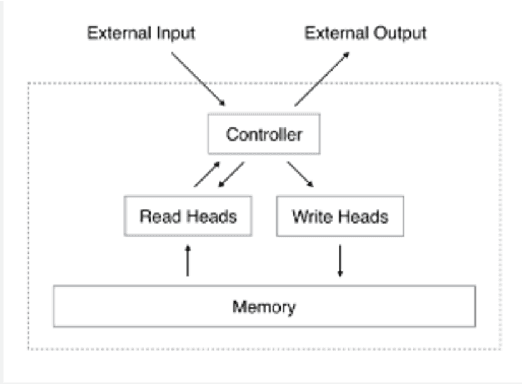
Since 2012, Deep learning has revolutionized Artificial Intelligence and has achieved state-of-the-art outcomes in different domains, ranging from Image Classification to Speech Generation. Though it has many potentials, our current architectures come with the pre-requisite of large amounts of data. Few-Shot Learning (also known as one-shot learning) is a sub-field of machine learning that aims to create such models that can learn the desired objective with less data, similar to how humans learn. In this paper, we have reviewed some of the well-known deep learning-based approaches towards few-shot learning. We have discussed the recent achievements, challenges, and possibilities of improvement of few-shot learning based deep learning architectures. Our aim for this paper is threefold: (i) Give a brief introduction to deep learning architectures for few-shot learning with pointers to core references. (ii) Indicate how deep learning has been applied to the low-data regime, from data preparation to model training. and, (iii) Provide a starting point for people interested in experimenting and perhaps contributing to the field of few-shot learning by pointing out some useful resources and open-source code. Our code is available at Github: https://github.com/shruti-jadon/Hands-on-One-Shot-Learning.
A survey of loss functions for semantic segmentation
Jun 30, 2020
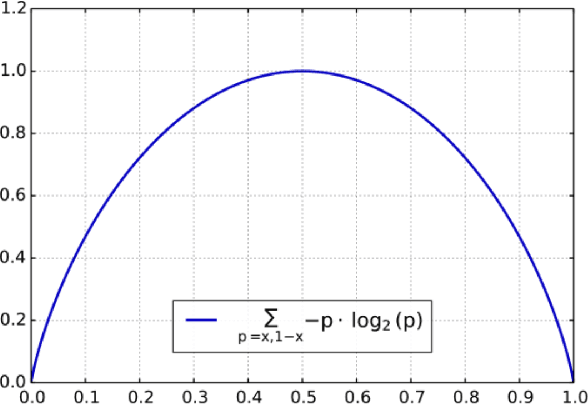
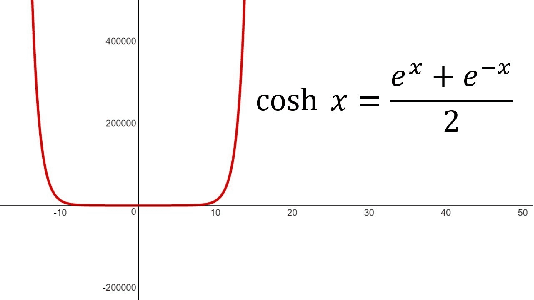
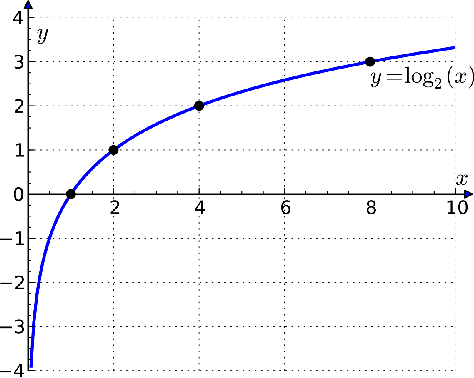
Image Segmentation has been an active field of research, as it has the potential to fix loopholes in healthcare, and help the mass. In the past 5 years, various papers came up with different objective loss functions used in different cases such as biased data, sparse segmentation, etc. In this paper, we have summarized most of the well-known loss functions widely used in Image segmentation and listed out the cases where their usage can help in fast and better convergence of a Model. Furthermore, We have also introduced a new log-cosh dice loss function and compared its performance on NBFS skull stripping with widely used loss functions. We showcased that certain loss functions perform well across all datasets and can be taken as a good choice in unknown-distribution datasets. The code is available at https://github.com/shruti-jadon/Semantic-Segmentation-Loss-Functions.
SSM-Net for Plants Disease Identification in Low Data Regime
Jun 02, 2020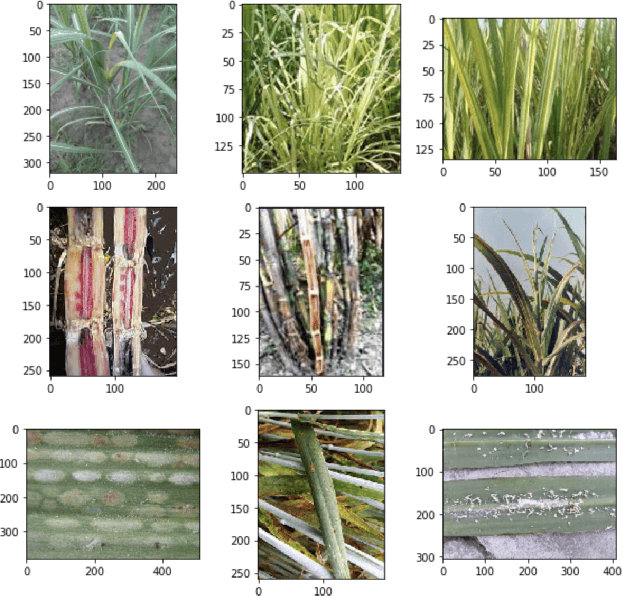
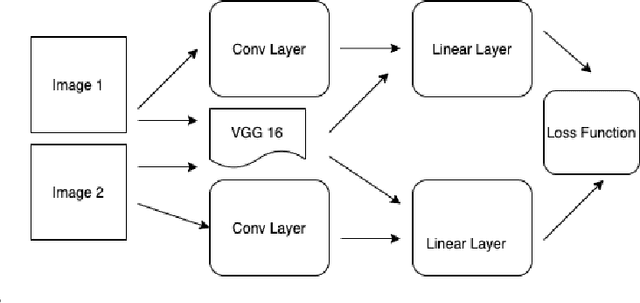
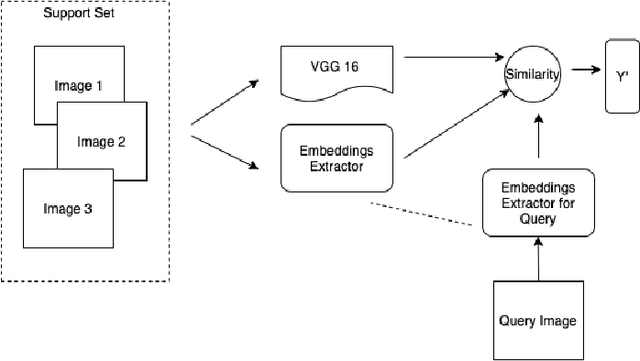
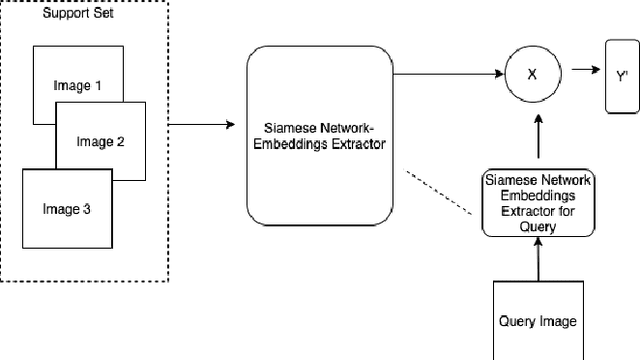
Plant disease detection is a necessary step in increasing agricultural production. Due to the difficulty of disease detection, farmers spray every form of pesticide on their crops to save them, causing harm to crop growth and food standards. Deep learning can help a lot in detecting such diseases. However, it is highly inconvenient to collect a large amount of data on all forms of disease of a specific plant species. In this paper, we propose a new metrics-based few-shot learning SSM net architecture, which consists of stacked siamese and matching network components to solve the problem of disease detection in low data regimes. We showcase that using the SSM net (stacked siamese matching) method, we were able to achieve better decision boundaries and accuracy of 94.3%, an increase of ~5% from using the traditional transfer learning approach (VGG16 and Xception net) and 3% from using original matching networks. Furthermore, we were able to attain an F1 score of 0.90 using SSM Net, an improvement from 0.30 using transfer learning and 0.80 using original matching networks.
A comparative study of 2D image segmentation algorithms for traumatic brain lesions using CT data from the ProTECTIII multicenter clinical trial
Jun 01, 2020Automated segmentation of medical imaging is of broad interest to clinicians and machine learning researchers alike. The goal of segmentation is to increase efficiency and simplicity of visualization and quantification of regions of interest within a medical image. Image segmentation is a difficult task because of multiparametric heterogeneity within the images, an obstacle that has proven especially challenging in efforts to automate the segmentation of brain lesions from non-contrast head computed tomography (CT). In this research, we have experimented with multiple available deep learning architectures to segment different phenotypes of hemorrhagic lesions found after moderate to severe traumatic brain injury (TBI). These include: intraparenchymal hemorrhage (IPH), subdural hematoma (SDH), epidural hematoma (EDH), and traumatic contusions. We were able to achieve an optimal Dice Coefficient1 score of 0.94 using UNet++ 2D Architecture with Focal Tversky Loss Function, an increase from 0.85 using UNet 2D with Binary Cross-Entropy Loss Function in intraparenchymal hemorrhage (IPH) cases. Furthermore, using the same setting, we were able to achieve the Dice Coefficient score of 0.90 and 0.86 in cases of Extra-Axial bleeds and Traumatic contusions, respectively.
Schema Matching using Machine Learning
Nov 24, 2019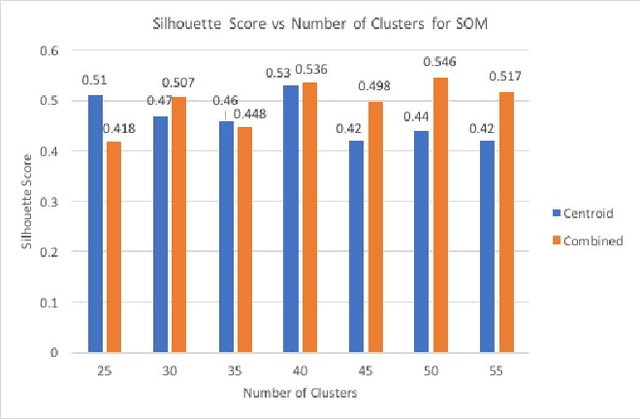
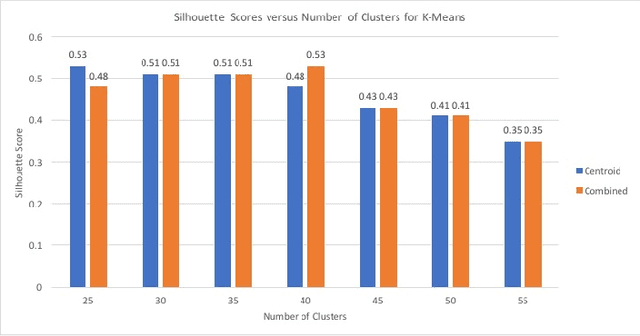
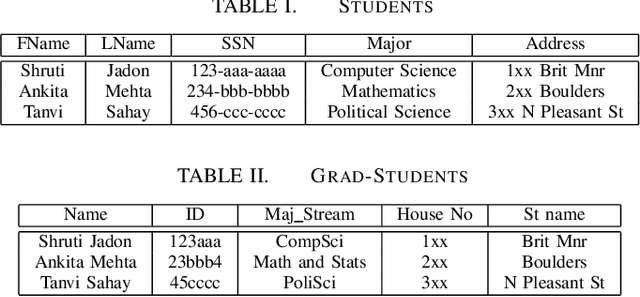
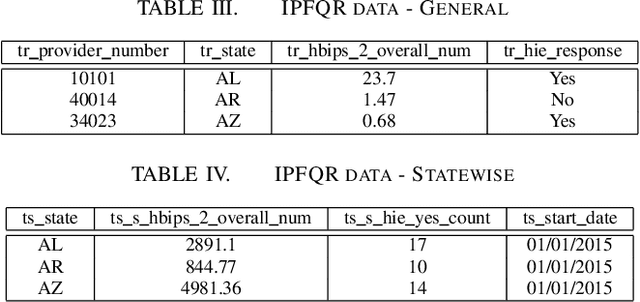
Schema Matching is a method of finding attributes that are either similar to each other linguistically or represent the same information. In this project, we take a hybrid approach at solving this problem by making use of both the provided data and the schema name to perform one to one schema matching and introduce the creation of a global dictionary to achieve one to many schema matching. We experiment with two methods of one to one matching and compare both based on their F-scores, precision, and recall. We also compare our method with the ones previously suggested and highlight differences between them.
Improving Siamese Networks for One Shot Learning using Kernel Based Activation functions
Oct 22, 2019
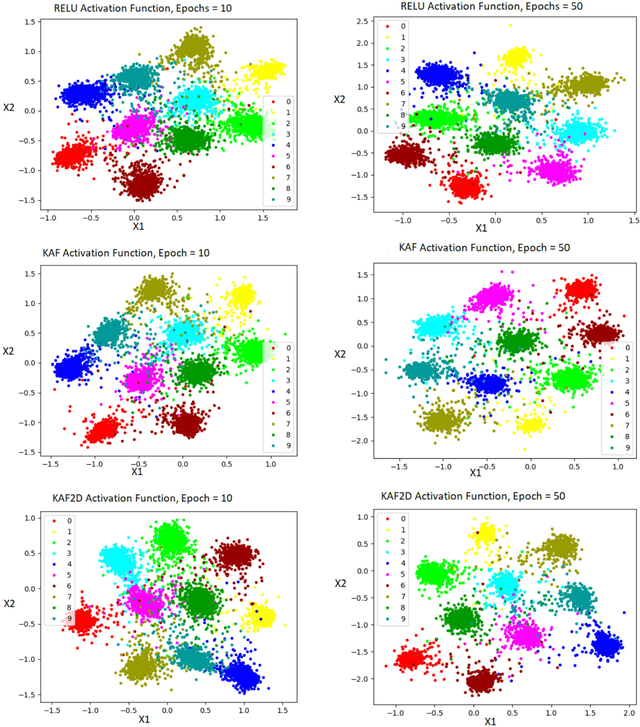
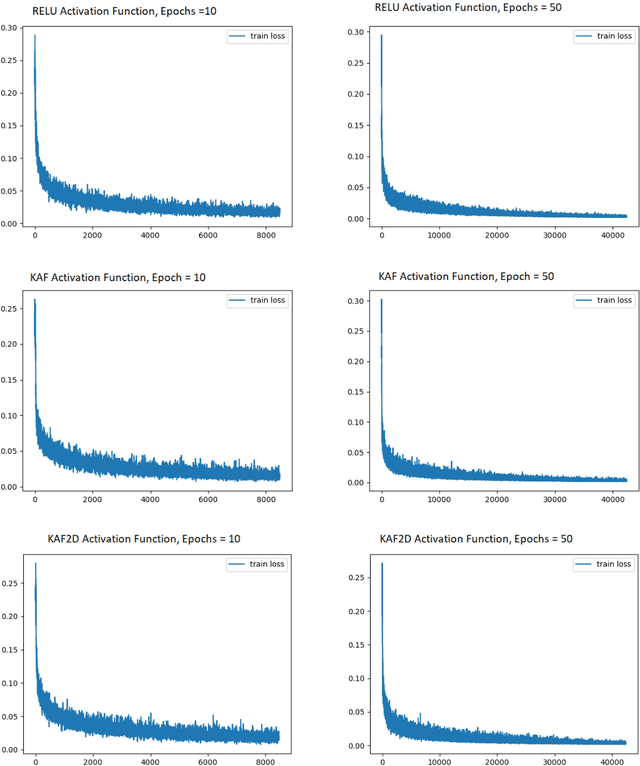
The lack of a large amount of training data has always been the constraining factor in solving a lot of problems in machine learning, making One Shot Learning one of the most intriguing ideas in machine learning. It aims to learn information about object categories from one, or only a few training examples. This process of learning in deep learning is usually accomplished by proper objective function, i.e; loss function and embeddings extraction i.e; architecture. In this paper, we discussed about metrics based deep learning architectures for one shot learning such as Siamese neural networks and present a method to improve on their accuracy using Kafnets (kernel-based non-parametric activation functions for neural networks) by learning proper embeddings with relatively less number of epochs. Using kernel activation functions, we are able to achieve strong results which exceed those of ReLU based deep learning models in terms of embeddings structure, loss convergence, and accuracy.