 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying graph neural network to SupplyGraph for supply chain network
Aug 23, 2024Supply chain networks describe interactions between products, manufacture facilities, storages in the context of supply and demand of the products. Supply chain data are inherently under graph structure; thus, it can be fertile ground for applications of graph neural network (GNN). Very recently, supply chain dataset, SupplyGraph, has been released to the public. Though the SupplyGraph dataset is valuable given scarcity of publicly available data, there was less clarity on description of the dataset, data quality assurance process, and hyperparameters of the selected models. Further, for generalizability of findings, it would be more convincing to present the findings by performing statistical analyses on the distribution of errors rather than showing the average value of the errors. Therefore, this study assessed the supply chain dataset, SupplyGraph, with better clarity on analyses processes, data quality assurance, machine learning (ML) model specifications. After data quality assurance procedures, this study compared performance of Multilayer Perceptions (MLP), Graph Convolution Network (GCN), and Graph Attention Network (GAT) on a demanding forecasting task while matching hyperparameters as feasible as possible. The analyses revealed that GAT performed best, followed by GCN and MLP. Those performance improvements were statistically significant at $\alpha = 0.05$ after correction for multiple comparisons. This study also discussed several considerations in applying GNN to supply chain networks. The current study reinforces the previous study in supply chain benchmark dataset with respect to description of the dataset and methodology, so that the future research in applications of GNN to supply chain becomes more reproducible.
A Comparative Study of Text Embedding Models for Semantic Text Similarity in Bug Reports
Aug 17, 2023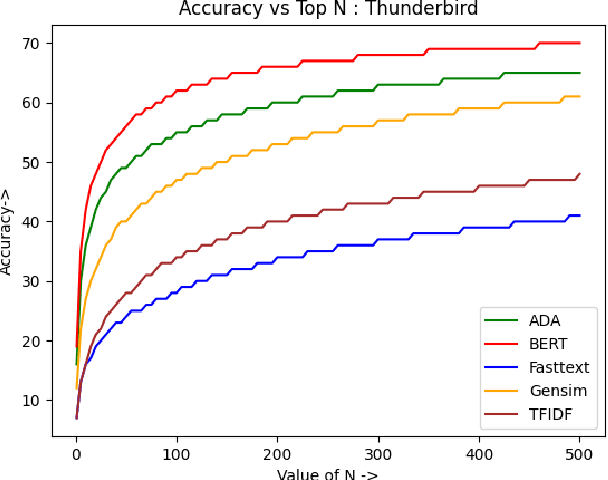
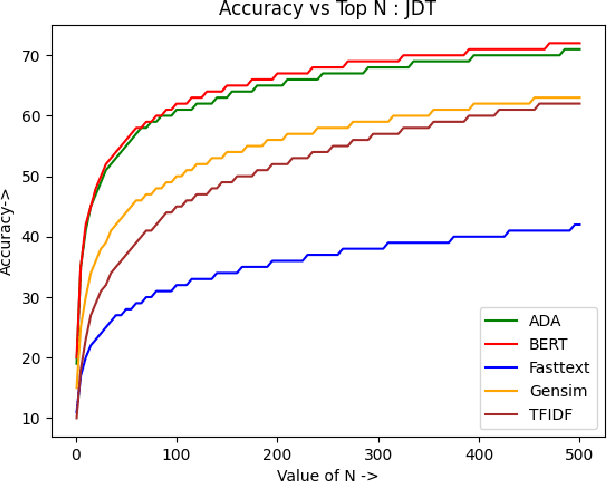
Bug reports are an essential aspect of software development, and it is crucial to identify and resolve them quickly to ensure the consistent functioning of software systems. Retrieving similar bug reports from an existing database can help reduce the time and effort required to resolve bugs. In this paper, we compared the effectiveness of semantic textual similarity methods for retrieving similar bug reports based on a similarity score. We explored several embedding models such as TF-IDF (Baseline), FastText, Gensim, BERT, and ADA. We used the Software Defects Data containing bug reports for various software projects to evaluate the performance of these models. Our experimental results showed that BERT generally outperformed the rest of the models regarding recall, followed by ADA, Gensim, FastText, and TFIDF. Our study provides insights into the effectiveness of different embedding methods for retrieving similar bug reports and highlights the impact of selecting the appropriate one for this task. Our code is available on GitHub.