 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIGEN: Expert-Informed Joint Learning Aggregation for High-Fidelity Information Extraction from Document Images
Nov 23, 2023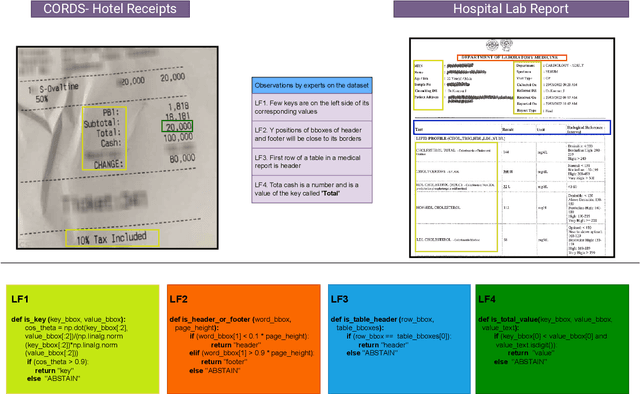



Information Extraction (IE) from document images is challenging due to the high variability of layout formats. Deep models such as LayoutLM and BROS have been proposed to address this problem and have shown promising results. However, they still require a large amount of field-level annotations for training these models. Other approaches using rule-based methods have also been proposed based on the understanding of the layout and semantics of a form such as geometric position, or type of the fields, etc. In this work, we propose a novel approach, EIGEN (Expert-Informed Joint Learning aGgrEatioN), which combines rule-based methods with deep learning models using data programming approaches to circumvent the requirement of annotation of large amounts of training data. Specifically, EIGEN consolidates weak labels induced from multiple heuristics through generative models and use them along with a small number of annotated labels to jointly train a deep model. In our framework, we propose the use of labeling functions that include incorporating contextual information thus capturing the visual and language context of a word for accurate categorization. We empirically show that our EIGEN framework can significantly improve the performance of state-of-the-art deep models with the availability of very few labeled data instances. The source code is available at https://github.com/ayushayush591/EIGEN-High-Fidelity-Extraction-Document-Images.